







DSMIL
DSMIL
1. 题目
Dual-stream Multiple Instance Learning Network for Whole Slide Image Classification with Self-supervised Contrastive Learning
github地址:https://github.com/binli123/dsmil-wsi
paper:https://arxiv.org/abs/2011.08939
2. 摘要
背景:解决WSI(高分辨率、缺乏局部注释)分类问题。
工作:提出一种基于MIL的WSI分类和病灶检查的方法。
- 提出一种新颖的MIL聚合器,通过可训练的距离度量对双流架构中实例的关系进行建模;
- 提出了自监督对比学习来提取MIL的良好表示(WSI会产生阻碍MIL模型训练的大型或不平衡包),并缓解大型包的高内存的问题;
- 对多尺度WSI特征采用金字塔融合机制,进一步提高分类和定位的准确性。
Our method has three major components. First, we introduce a novel MIL aggregator that models the relations of the instances in a dual-stream architecture with trainable distance measurement. Second, since WSIs can produce large or unbalanced bags that hinder the training of MIL models, we propose to use self-supervised contrastive learning to extract good representations for MIL and alleviate the issue of prohibitive memory cost for large bags. Third, we adopt a pyramidal fusion mechanism for multiscale WSI features, and further improve the accuracy of classification and localization.
数据集:TCGA、Camelyon16
3. 内容
3.1 问题背景
弱监督深度MIL模型WSI分类的主要挑战:
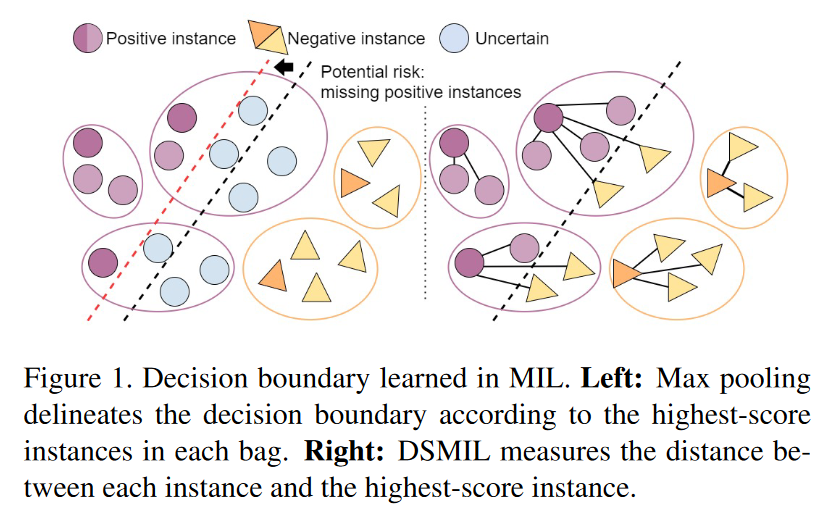
- 当正包中的实例是高度不平衡,即一小部分实例是积极的。当使用一个简单的聚合操作时(比如广泛采用max-pooling),模型可能会把这些积极的实例误分类。下图1
When patches (instances) in positive images (bags) are highly unbalanced, i.e., only a small portion of patches are positive, the models are likely to misclassify those positive instances [22] when using a simple aggregation operation, such as the widely adopted max-pooling.
- 因为端到端培训特征提取器和聚合器非常昂贵,当前模型使用由CNN提取的固定特性或使用几个高分补丁更新特征提取器。 这些简化的学习机制会导致WSI分类的次优 Patch 特征。
Current models either use fixed patch features extracted by a CNN or only update the feature extractor using a few high score patches, as the end-to-end training of the feature extractor and aggregator is prohibitively expensive for large bags.
3.2 总体结构
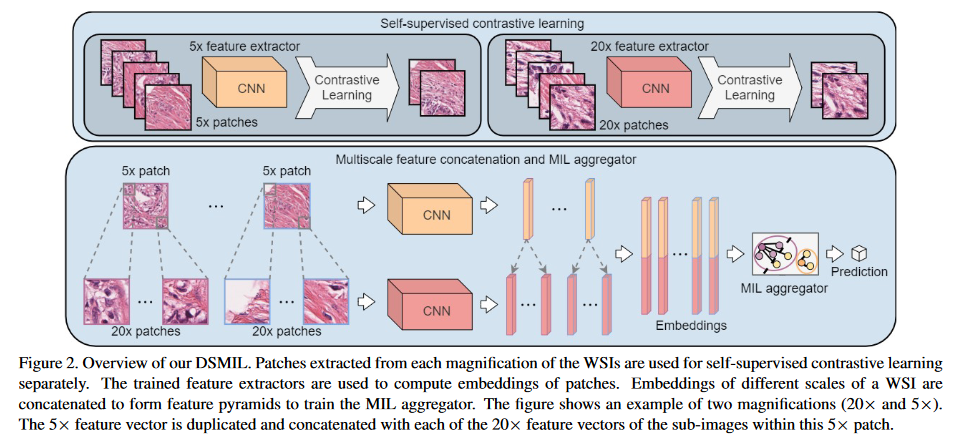
3.3 方法
3.3.1. MIL 范式
包: B = ( x 1 , y 1 ) , ⋯ , ( x n , y n ) B = {(x_1,y_1), \cdots, (x_n,y_n)} B=(x1,y1),⋯,(xn,yn) ,实例:$x_i \in \chi $ , 标签 y i ∈ 0 , 1 y_i \in {0, 1} yi∈0,1 。
KaTeX parse error: Undefined control sequence: \mbox at position 28: …in{cases} 0, & \̲m̲b̲o̲x̲{if } \sum y_i …
进一步,MIL使用一个适当变换
f
f
f 和一个置换不变 (permutation-invariant) 变换
g
g
g 来预测标签
B
B
B 。
c
(
B
)
=
g
(
f
(
x
0
)
,
⋯
,
g
(
f
n
)
)
c(B) = g(f(x_0), \cdots,g(f_n))
c(B)=g(f(x0),⋯,g(fn))
基于
f
f
f 和
g
g
g 有两种不同的MIL建模方式:
- Instance-based: $ f$ 是一个实例分类器(赋予每个实例分数), g g g 是一个池化操作符(聚合实例分数得到包分数)
- Embedding-based: f f f 是实例级的特征提取器(映射每个实例到一个嵌入), g g g 是一个聚合操作符(从实例嵌入中产生一个包嵌入,基于包嵌入输出一个包分数)
Embedding-based 比 Instance-based 精度更高, 但难以确定触发分类器的关键实例。
The embedding-based method produces a bag score based on a bag embedding directly supervised by the bag label and usually yields better accuracy compared to the instance-based method [52], however, it is usually harder to determine the key instances that trigger the classifier [30].
3.3.2. DSMIL
关键创新: 新颖的集合函数 g g g 的设计, 特征提取器 f f f 的学习。
1. MIL Aggregator with Masked Non-Local Operation
包含用于特征聚合的 masked non-local 块 和 max-pooling 块。
输入: 自监督对比学习得到的特征嵌入。
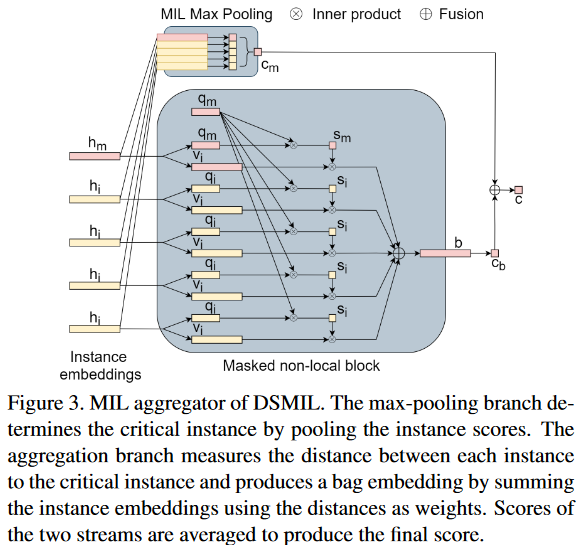
- First Stream
包:
B
=
x
1
,
⋯
,
x
n
B = {x_1,\cdots,x_n}
B=x1,⋯,xn , 特征提取器
f
f
f , 实例
x
i
x_i
xi 投影到嵌入
h
i
=
f
(
x
i
)
∈
ℜ
L
×
1
h_i = f(x_i) \in \Re^{L \times 1}
hi=f(xi)∈ℜL×1 。
c
(
B
)
=
g
m
(
f
(
x
0
)
,
⋯
,
g
(
f
n
)
)
=
max
{
W
0
h
0
,
⋯
,
W
0
h
N
−
1
}
\begin{align} c(B) & = g_m(f(x_0), \cdots,g(f_n)) \\ & = \max \{W_0h_0,\cdots,W_0h_{N-1}\} \end{align}
c(B)=gm(f(x0),⋯,g(fn))=max{W0h0,⋯,W0hN−1}
W
0
W_0
W0 是一个权重向量, max-pooling 是一个置换不变操作,因此这一流满足定义。
- Second Stream
转换实例嵌入
h
i
h_i
hi 到两个向量 , query
q
i
∈
ℜ
L
×
1
q_i \in \Re^{L \times 1}
qi∈ℜL×1 和 information $v_i \in \Re^{L \times 1} $。
q
i
=
W
q
H
i
,
v
i
=
W
v
h
i
,
i
=
0
,
⋯
,
N
−
1
q_i = W_qH_i, \ \ \ v_i = W_vh_i, \ \ \ \ i = 0, \cdots, N - 1
qi=WqHi, vi=Wvhi, i=0,⋯,N−1
W
q
W_q
Wq 和
W
v
W_v
Wv 是权重矩阵。
定义距离度量
U
U
U (关键实例到其他实例):
U
(
h
i
,
h
m
)
=
e
x
p
(
⟨
q
i
,
q
m
⟩
)
∑
i
N
−
1
e
x
p
(
⟨
q
k
,
q
m
⟩
)
U(h_i,h_m) = \frac {exp(\left \langle q_i, q_m \right \rangle)} {\sum_i^{N-1} exp(\left \langle q_k, q_m \right \rangle )}
U(hi,hm)=∑iN−1exp(⟨qk,qm⟩)exp(⟨qi,qm⟩)
⟨
,
⟩
\left \langle \ , \ \right \rangle
⟨ , ⟩ 表示两个向量的内积。
包嵌入 b 是所有实例的 信息向量 v i v_i vi 的加权元素和 (weighted element-wise sum),使用到关键实例的距离作为权重。
b = ∑ i N − 1 U ( h i , h m ) v i b = \sum_i^{N-1} U(h_i,h_m)v_i b=i∑N−1U(hi,hm)vi
包分数
c
b
c_b
cb :
c
b
(
B
)
=
g
b
(
f
(
x
i
)
,
⋯
,
f
(
x
n
)
)
=
W
b
∑
i
N
−
1
U
(
h
i
,
h
m
)
v
i
=
W
b
b
\begin{align} c_b(B) &= g_b(f(x_i), \cdots, f(x_n)) \\ &=W_b \sum_i^{N-1} U(h_i, h_m)v_i = W_bb \end{align}
cb(B)=gb(f(xi),⋯,f(xn))=Wbi∑N−1U(hi,hm)vi=Wbb
W b W_b Wb 是二分类的权重向量 。 这个操作类似于自注意力, 不同在于query-key 匹配只表现在关键节点和其他节点之间。
点积测量两个 query 之间的相似性,更大的值更相似。因此,与关键实例更相似的实例会有更好的注意力权重。information 向量 v i v_i vi 的附加层允许从每个实例中提取贡献信息,soft-max 操作确保注意力权重之和为1。
因为关键实例不依赖于实例的顺序,U 也是对称的,即,包嵌入 b 不依赖于实例的顺序。因此, 第二流是置换不变的且满足定义。
最后的 包 分数是两个流的平均:
c
(
B
)
=
1
2
(
g
m
(
f
(
x
i
)
,
⋯
,
f
(
x
n
)
)
+
g
b
(
f
(
x
i
)
,
⋯
,
f
(
x
n
)
)
)
=
1
2
(
W
0
h
m
+
W
b
∑
i
U
(
h
i
,
H
m
)
v
i
)
\begin{align} c(B) & = \frac {1} {2} (g_m(f(x_i), \cdots, f(x_n)) + g_b(f(x_i), \cdots, f(x_n))) \\ & = \frac {1} {2} (W_0h_m + W_b \sum_iU(h_i,H_m)v_i) \end{align}
c(B)=21(gm(f(xi),⋯,f(xn))+gb(f(xi),⋯,f(xn)))=21(W0hm+Wbi∑U(hi,Hm)vi)
包嵌入的结果是一个矩阵 $ b \in \Re^{L \times C}$ , C 是类的数目,每个 information 向量
v
i
v_i
vi 的加权和。最后的全连接层输出 C 通道。 information 向量
v
i
v_i
vi 允许实例间特征选择(距离度量被用来实例间特征选择, 根据实例间相似性)。结果的包嵌入是一个与包大小无关的固定的形状,将被用来计算包得分
c
b
c_b
cb。如图3。
2. Self-Supervised Contrastive Learning of WSI Features
SimCLR
3. Locally-Constrained Multiscale Attention
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Jzmt5ruq-1667189338775)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20221031114531047.png)]](https://img-blog.csdnimg.cn/1e9a480a68134577ab9a36f3994cfb8f.png)
4. 实验
- 数据集: Camelyon16 and TCGA lung cancer
- 指标:accuracy 、 area under the curve (AUC) scores
4.1 结果
- Camelyon 16
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KJxNmF7i-1667189338776)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20221031115208443.png)]](https://img-blog.csdnimg.cn/17353cde1c274d0988f6dc33595b7b50.png)
- TCGA
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e3ty1DZO-1667189338776)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20221031115221212.png)]](https://img-blog.csdnimg.cn/f2739a8676fd445fb3311e541ee595c8.png)
4.2 消融实验
- Effects of Contrastive Learning
- Effects of Multiscale Attention
- DSMIL Aggregator on Other MIL Tasks
5. 结论和展望
结论: MIL聚合器、自监督对比学习、多尺度特征
展望
- 设计适应于组织病理图像特征的自监督学习策略
- 整合建模空间关系机制捕获 WSI 的多分辨率特征
引用
@inproceedings{Li:2021:1431814328,
author = {Bin Li and Yin Li and Kevin W Eliceiri},
title = {Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning},
booktitle = {{IEEE} Conference on Computer Vision and Pattern Recognition},
pages = {14318--14328},
year = {2021}
url = {https://arxiv.org/abs/2011.08939}
}















 1450
1450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









