







本篇文章我们继续研究图水平预测的传统机器学习。接下来我们专注于链接可捕获的预测任务和功能。
在给定的任务中,链接级别预测的任务如下:
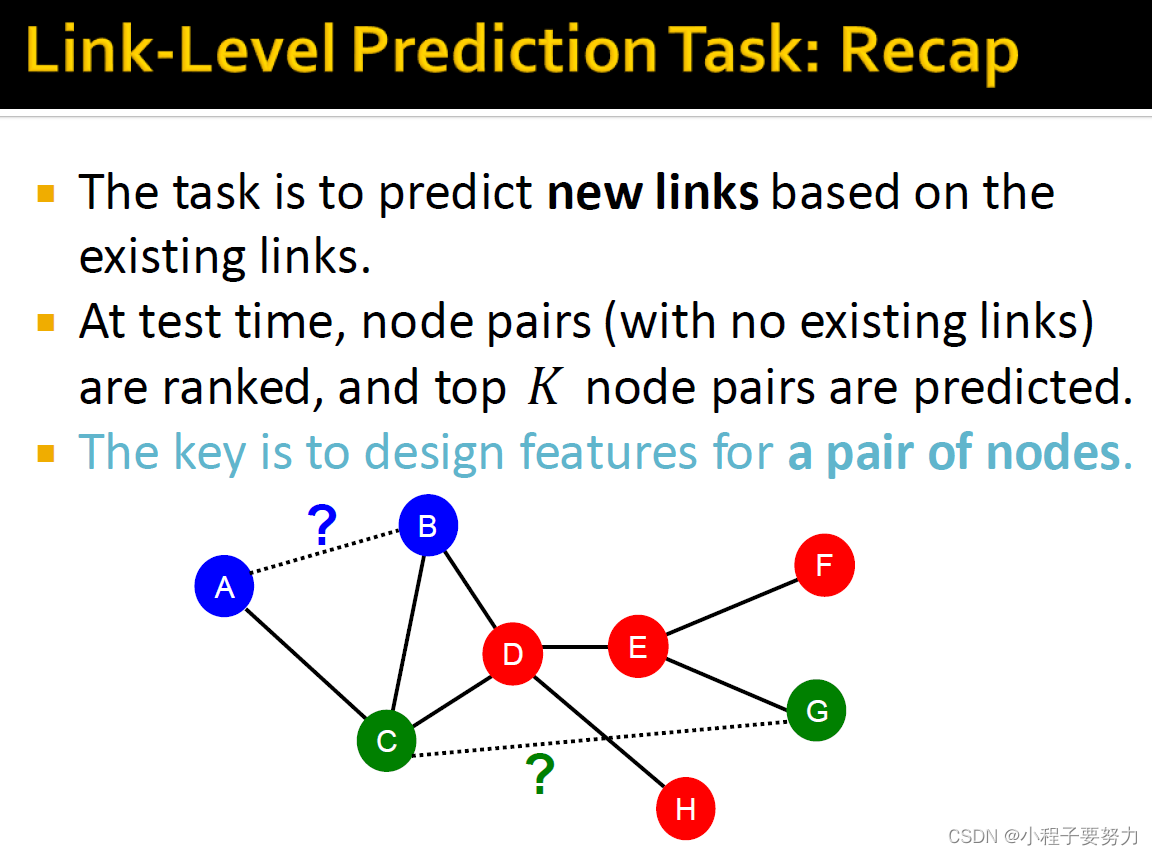
任务是根据网络中现有的链接来预测新的链接。因此,这意味着我们在测试时,我们必须评估所有尚未链接的节点对,给它们的排名,宣布前k个音符对由我们的算法预测,是将要发生的链接,在网络上。
这里的关键是为一对节点设计功能。当然,我们能做的是正如我们在节点级别看到的任务,我们可以去让我们串联起来节点编号1、2的功能,并在这种类型的表示形式上训练模型。但是,也有不满意的地方,因为,这会很多次失去了关于两个节点之间关系的许多重要信息。
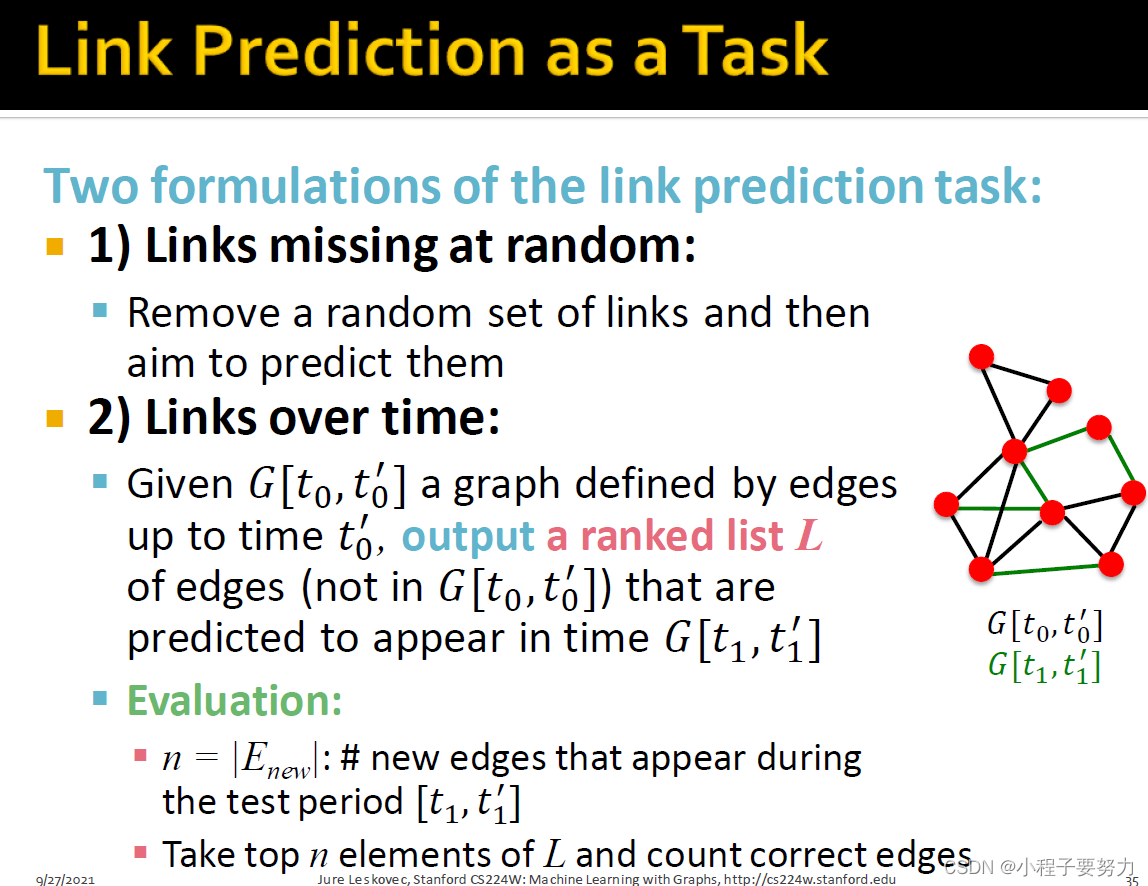
因此,我们在链接预测任务的看法是双向的。我们可以用两种不同的方式来表达它。我们可以这样表述的一种方法就是简单地说:网络中的链接是可以说随机失踪。所以我们有一些网络,可以删除随机一些链接,然后尝试预测,那些使用我们链接的机器学习算法。公式的另一种类型是我们将随着时间的推移预测链接。
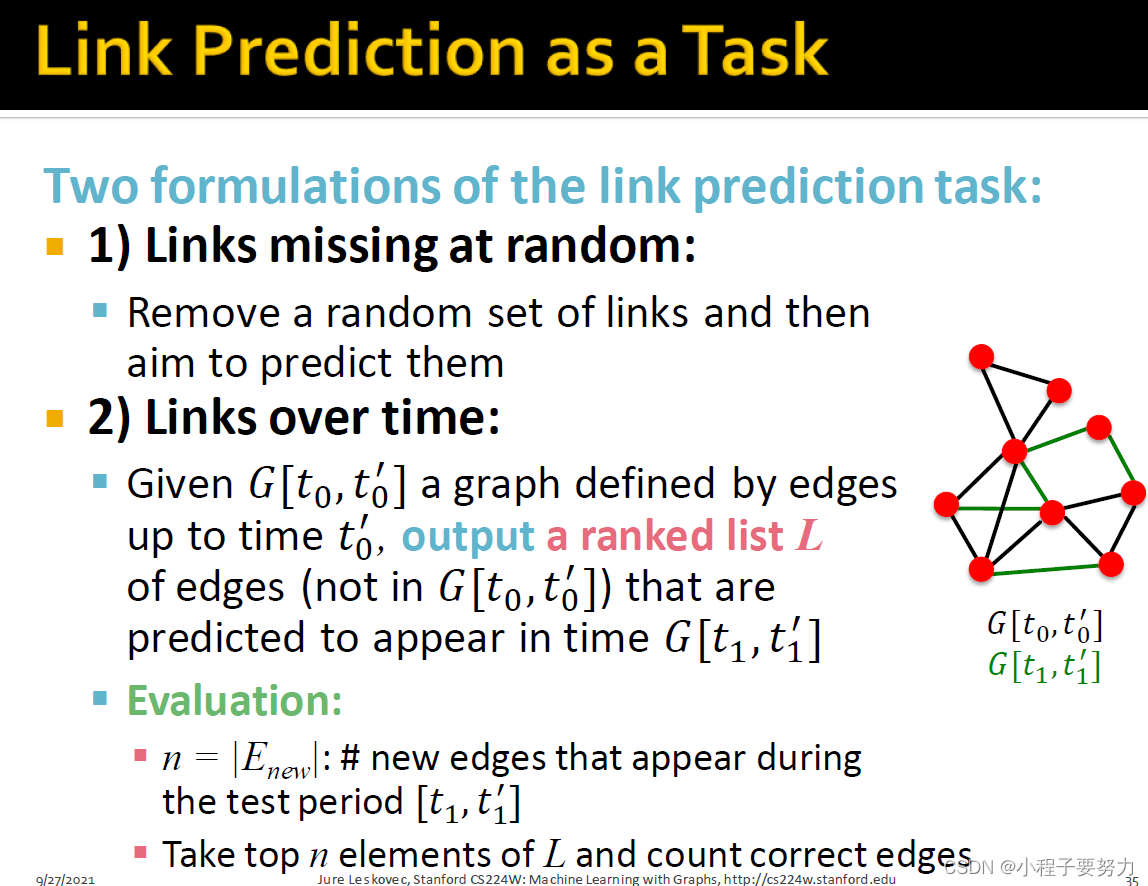
所以,现在我们考虑如何提供功能描述符?因此,对于两个节点x,y,我们将计算一些分数c(x, y)。例如,分数可以是节点之间的公共邻居的数量X和Y。然后,我们将对所有对(x, y)进行递减排序得到分数c(x,y)。我们将预测高端对将作为新链接出现,然后,我们可以结束测试时间。我们可以去观察实际出现的链接并比较这两个列表,以此确定我们的方法有多么的好。
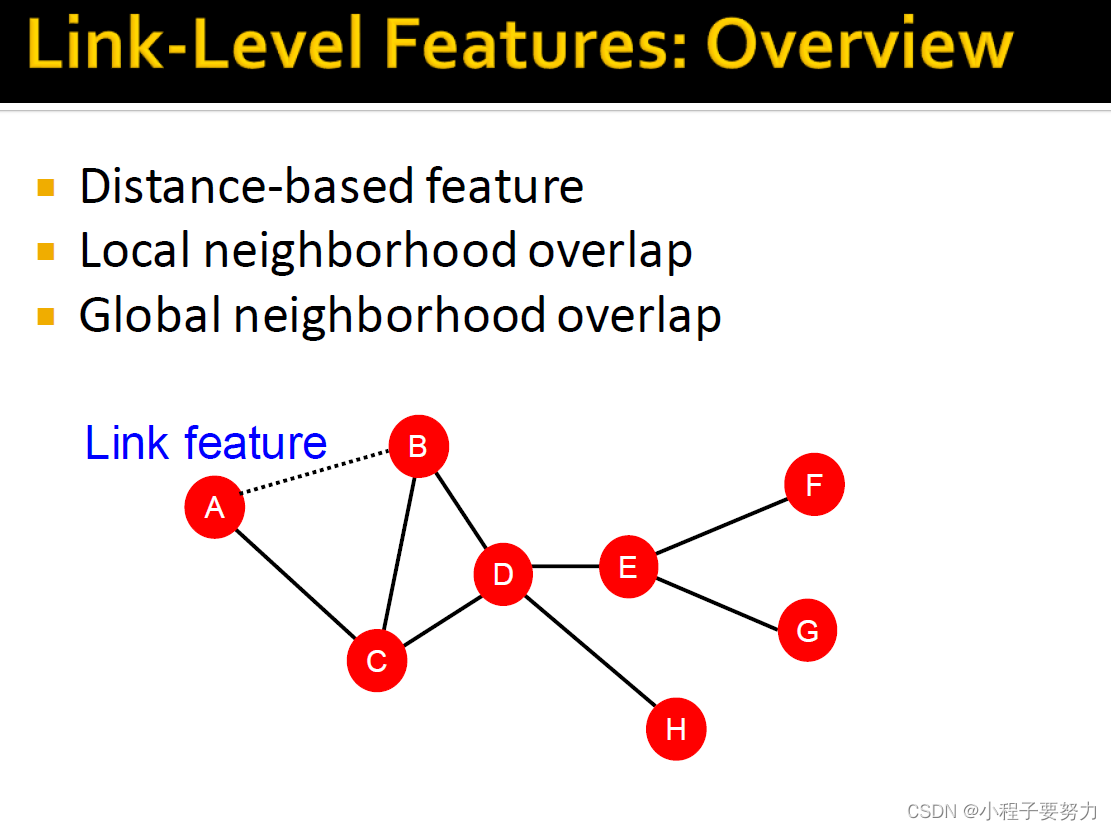
我们的算法将正在进行工作,正在进行审核的三种不同方式使网络中两个节点之间的关系特征化或创建一个描述符。我们将讨论基于距离的功能、本地邻域重叠特征、全球邻域邻居重叠特征,目标是对于给定的一对节点,我们将描述在两个节点之间的这种关系。这样我们就可以根据这种关系预测或了解它们之间是否存在链接。
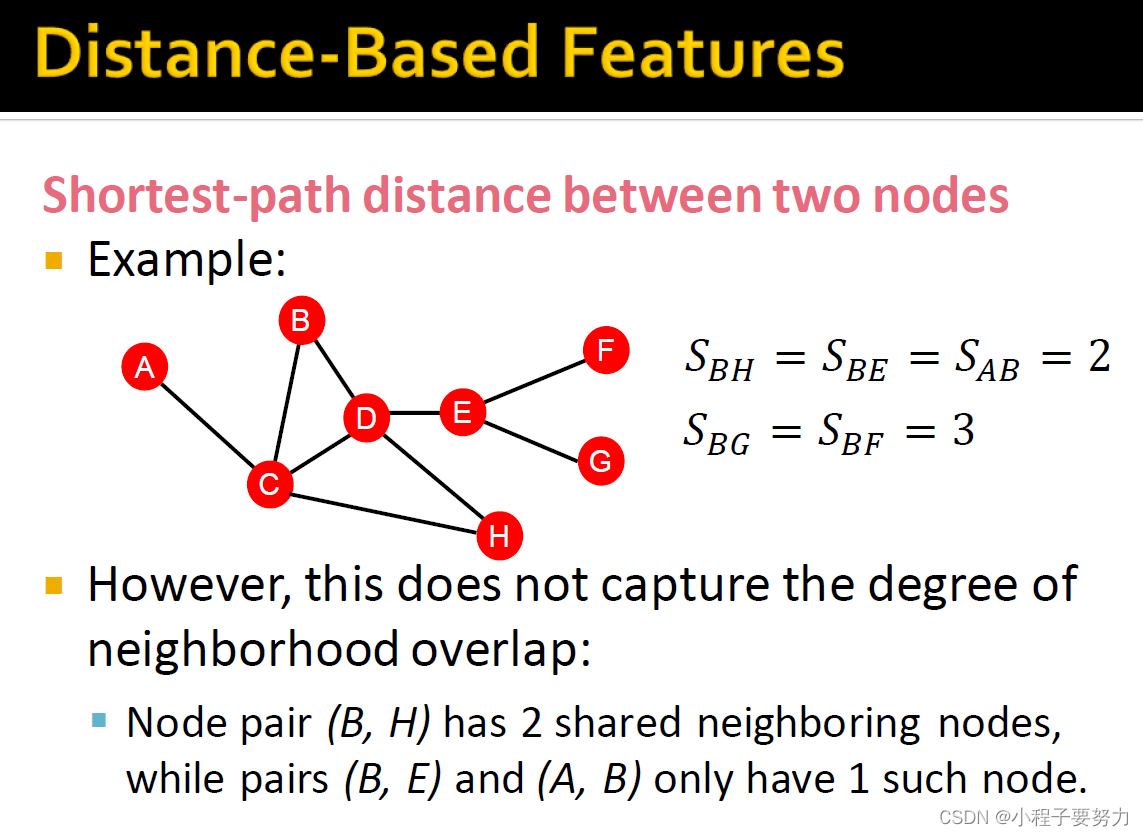
首先,我们来谈谈基于距离的功能。我们可以考虑两个节点之间的最短路径距离,并以此方式对其进行表征。例如:我们有节点B和H,那么它们之间的最短路径长度,等于2。因此,此功能的值将等于2。但是如果你看着,这是什么--该指标没有捕获它,它捕获了距离,但这并不能衡量捕获邻域重叠程度或连接强度的一种。因此,例如,你可以在此网络中查看节点B和H实际上有两个共同点。因此,从某种意义上来讲,它们之间的联系更加牢固。例如,节点D和F,因此,它们只有一条路径,而这里有两条不同的路径。
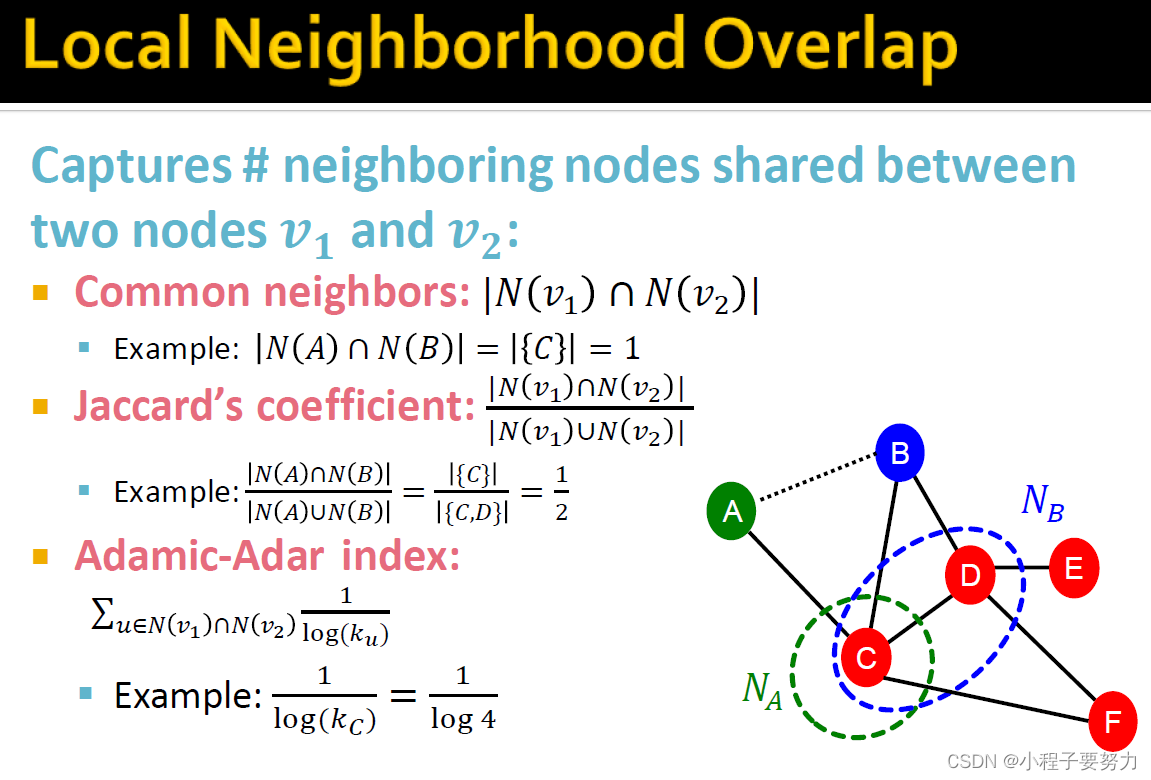
所以,我们可以尝试捕捉两个节点之间的连接强度有多少邻居以及共同点数量的方式,一对节点之间的共同好友数是多少?这是由本地邻域重叠的概念所捕获的,捕获两个节点之间共享的相邻节点的数量v1和v2。捕获这种情况的一种方式就是简单地说:什么是共同邻居的人数是多少?我们取节点v1和v2,并取这两个集合的交集。这个是规范化的标本。同样的想法是Jaccard's coefficient,我们在十字路口走,相交的大小除以并集的大小。普通邻居的问题是度数较高的节点更有可能与其它节点建立邻居。然后是另一种形式,当地邻居重叠。在实践中非常有效的指标被称为Adamic-Adar索引。这只是说让我们总结一下节点v1和节点v2有共同点的邻居。因此,基本的想法是我们计算有多少个邻居,这两个节点有共同点,但是邻居不平衡的重要性是很低,随着这些度数降低。因此,如果你有很多度数低的邻居,那比你有很多具有高度联系的名人,作为一组共同的邻居。因此,这是一个网络,该功能在社交网络中非常有效。
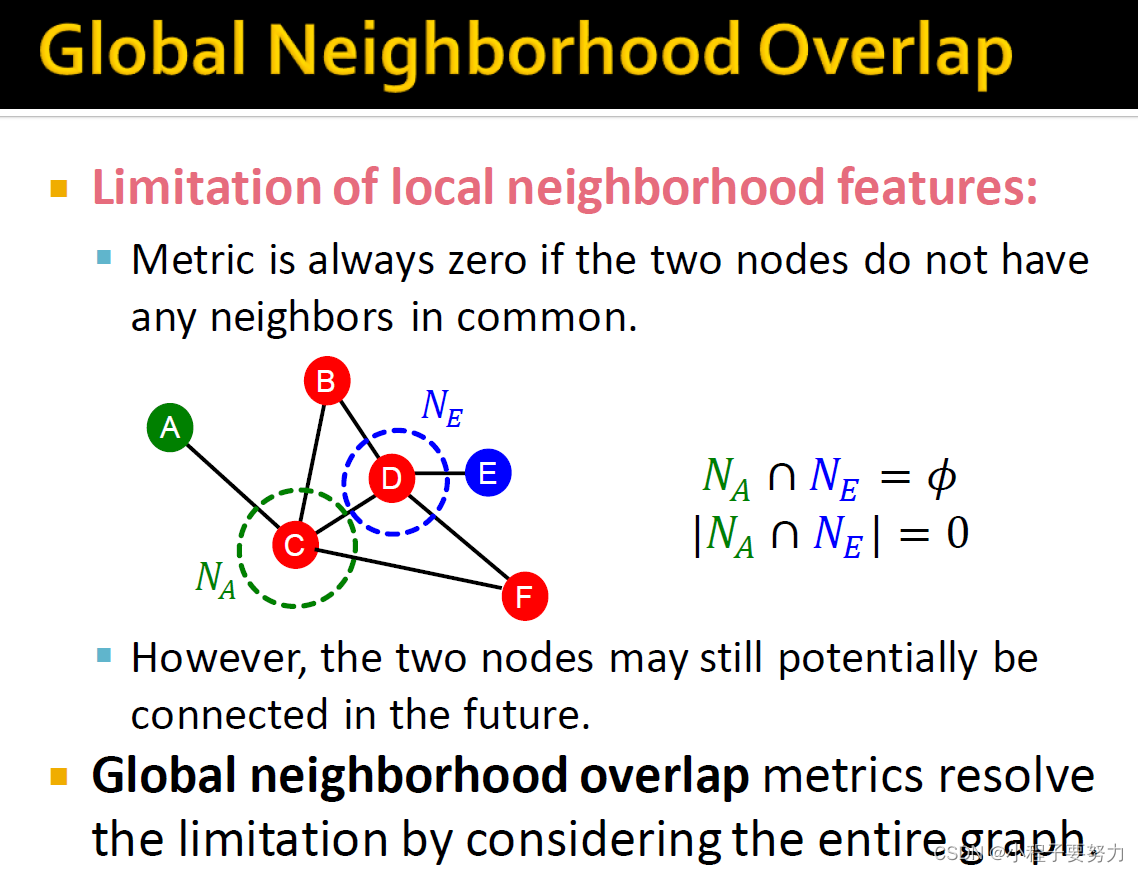
本地邻域重叠特征是其局限性,如果没有两个节点-两个节点都不存在,则metric始终返回零。因此,例如,在这种情况下,如果我们要说节点A和E之间的邻域重叠是什么?因为他们没有共同的邻居,它们不仅仅是彼此之间相距两跳。然后,如果在这种情况下,return将要返回的值始终为零。但是,实际上,这两个节点将来可能仍会连接在一起。因此,要解决此问题,我们定义全局邻域重叠矩阵,这就是所有这些限制,专注于一跳、两跳距离和一对节点对之间的两跳路径,并考虑所有其他距离或者整个图形。
现在,让我们看一下全局邻域重叠类型。
我们要讨论的指标称为Katz指数,它计算所有路径的数量,给定节点对之间所有不同的长度。现在我们需要弄清楚两件事情,首先是在两点之间如何计算给定长度的路径数。实际上,这个可以通过使用图邻接矩阵的幂这种方式来计算。

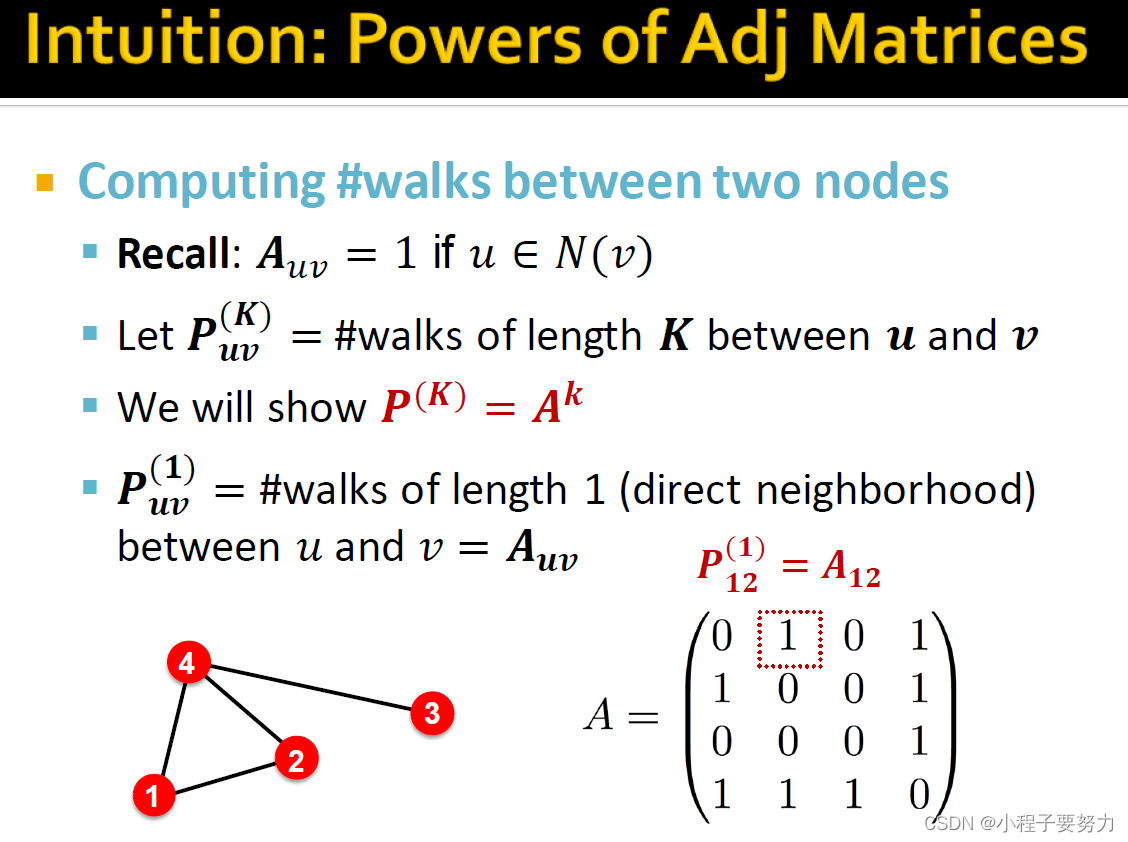
证明过程:首先是关于邻接矩阵幂的直觉。关键我们展示的是计算两个节点之间的路径数来降低图邻接矩阵的计算能力或者本质上是采用图邻接矩阵矩阵并将其与自身相乘。因此,第一个图邻接矩阵召回,如果节点u和v连接,则在每个条目uv处其值为1。那我们说uv、uh上标大写K计数,节点u和v之间的长度K。我们的目标是证明uh。如果我们对路径数感兴趣的话,长度为K。那我们必须计算A到k的幂,项uv将告诉我们宠物的数量。因此,A的K次方可测量给定长度的路径数。如果你考虑正确的话,那么一对图邻接矩阵精确捕获的节点之间的有多少条长度为1的路径。如果连接了一对节点,然后有一个值为1,如果没有连接一对节点,则为0。
现在我们知道了如何计算一对节点之间长度为1的路径数。现在我们可以问一对节点之间的长度为2的路径数u。我们将通过两步程序来完成此操作:我们通过分解路径将长度2转换成长度为1的路径加上长度为1的另一条路径。因此,想法是在每个u邻居和v之间,我们计算长度为1的路径数,然后,再加上一个。因此,想法如下:长度为2和长度为1的节点u和v之间的路径数为与起始节点u相邻的节点i的求和乘以现在的路径数,这个邻居我到目标节点v。这将给我们u和v之间长度为2的路径数。现在你可以看到一个替换物邻接矩阵。所以所有这些都是我的总和Aui*Aiv。如果你看到这个的话,那么这只是矩阵的乘积。由邻接矩阵Aiu本身组成。

现在我们可以定义--我们已经开发了第一个将使我们能够计算出切割指数的组件,因为它允许我们计算给定K的一对节点之间的路径数。但我们仍然需要决定的是,我们如何在所有路径长度上做到这一点,从一个到无限。因此,正如我们所说,要计算两个节点之间的路径?我们将使用邻接矩阵的幂。邻接矩阵本身告诉我们长度为1的幂,它的平方告诉我们长度为2的路径和邻接矩阵提高到了要计算一对节点之间长度为1的路径数。

现在,Katz索引从1个路径长度一直延伸到无穷大。所以Katz索引节点v1与节点v2之间的全局邻域重叠,v2只是从1到无穷大的和。基本上,我们将此Beta提升为l的幂的系数,其重要性较低。到更长的路径和A到bl的路径,v1和v2的节点之间长度为l的路径数。现在Katz有趣的是我们实际上可以封闭形式计算此特定表达式。

因此,总结一下,链接级功能。我们描述了其中的三种类型。我们讨论了用户基于距离的功能、邻域重叠指标、全球邻域重叠类型指标。















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









