







[1] Liu A, Zhang Y, Zhang X, et al. Representation Learning with Multi-level Attention for Activity Trajectory Similarity Computation[J]. IEEE Transactions on Knowledge and Data Engineering, 2020.
文章目录
Abstract
Massive trajectory data stem from the prevalence of equipment-supporting GPS and wireless communication technology. Especially, activity trajectory from LBSN (Location-based Social Network) endows traditional trajectory data with additional user semantic activities, e.g., visiting work/home/entertainment places. Measuring the similarity between activity trajectories is to compare their proximity in multiple dimensions such as time, location, and semantics. In this way, we can mine implicit user preference and apply it to route planning, POI recommendation or any other online tasks. The key challenge of comparing activity trajectories (i.e., computing their similarity) lies in two aspects. One is the uneven sampling rate in both time and space. The other is the discrepancy of individual activities. Previous effort alleviates the issue of uneven sampling rate via trajectory complements, which is limited to spatial-temporal information. In this paper, we propose to learn a representation for one activity trajectory by jointly considering the spatio-temporal characteristics and the activity semantics. The similarity of two trajectories is computed by weighting individual trajectory points and contextual features with multi-level attention mechanisms. In specific, we propose a point-level and feature-level attention mechanism to adaptively select critical elements and contextual factors for learning trajectory representation. Our proposed approach, called At2vec, demonstrates better performance than existing baselines in extensive experimental evaluation on real trajectory databases.
-
生词
endow 赋予 discrepancy 不符;矛盾 alleviate 减轻;缓和 -
测量
活动轨迹之间的相似性是在多个维度上比较它们的相似性,例如时间、位置和语义。 -
计算活动轨迹的相似性的关键
挑战: 1. 时间和空间采样率的不均匀。2. 个体活动的差异性。 -
以往的研究工作:通过
轨迹补全缓解采样率不均匀,受限于时空信息。 -
本文:提出通过结合时空特征和活动语义来
学习一个活动轨迹的表示。通过对轨迹点和上下文特征的多层次注意力机制加权来计算两个轨迹的相似性。具体来说,我们提出了一个点级和特征级注意力机制来自适应地选择关键元素和上下文因素来学习轨迹表征。我们提出的方法,称为At2vec。
Index Terms
- trajectory similarity
- representation learning
- activity trajectory
- attention mechanisms
1 Introduction
- 在轨迹离群检测、轨迹聚类、轨迹加密等许多应用中,测量两条轨迹的相似度是最基本的操作。
- 基于轨迹点匹配的高级相似度计算方法,包括LCSS[8]和DTW[9]。然而,这些方法的前提:轨迹采样率均匀
- 实际的轨迹往往在时间和空间上
采样不均匀——轨迹异质性问题(trajectory heterogeneity) - 解决轨迹非均质性问题的
核心思想:轨迹修正和完备(trajectory modification and completion) - 一些方法将轨迹的采样率与时空特征统一起来,使两条轨迹上的定位点能够匹配。
One example of 定位点匹配
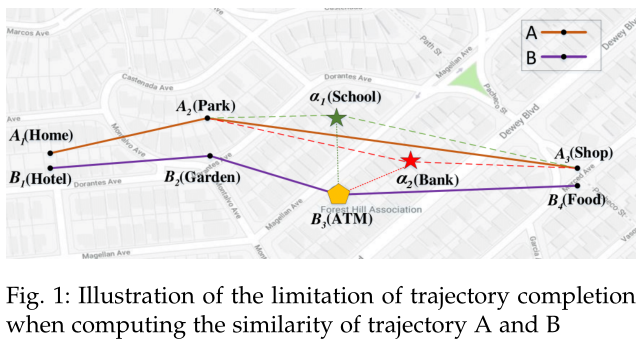
如图A和B是两条轨迹,需要从A的候选点 α 1 \alpha_1 α1和 α 2 \alpha_2 α2中选出与 B 3 B_3 B3匹配的点。
假设dist( α 1 \alpha_1 α1, B 3 B_3 B3) = dist( α 2 \alpha_2 α2, B 3 B_3 B3)(物理距离相同),如何选择?
考虑描述地点的关键词信息, α 2 \alpha_2 α2的关键词信息“Bank”和 B 3 B_3 B3的关键词“ATM”语义上更接近。因此选择 α 2 \alpha_2 α2作为轨迹A中与轨迹B中的 B 3 B_3 B3匹配的点。
- 本文是在
作者之前的工作基础上完成的。
作者在[14]中第一次尝试解决活动轨迹相似度计算的问题。[14]中的模型有一些局限性。1. 没有考虑不同轨迹特征(空间、时间、活动信息)在相似性度量中的重要性。2. 在训练过程中没有突出轨迹中的关键点,如拐点。3. RNN无法捕获长序列中的长期依赖关系,并且在轨迹表示中丢失了大量上下文关系。
[14] Y . Zhang, A. Liu, G. Liu, Z. Li, and Q. Li, “Deep representation learning of activity trajectory similarity computation,” in 2019 IEEE International Conference on Web Services (ICWS). IEEE, 2019, pp. 312–319.
针对上述局限性,我们提出了一种具有多层次注意力机制的新模型At2vec。
我们提出的模型的一个重要优点是它在语义映射空间中比较了两条轨迹,不需要trajectory completion. 具体来说,它通过整合时空和活动信息将每个轨迹映射到一个向量。因此,我们提出的模型被称为At2vec(Activity trajectory to vector)。学习到的语义向量可以通过点积等简单指标来比较,以计算轨迹相似性。虽然不需要复杂的completion过程,但轨迹比较仍然面临低采样轨迹的高不确定性。
- 假设低采样轨迹是其完整高采样轨迹的子序列。因此,从低采样轨迹中学习到的表示法有望恢复高采样轨迹。
Seq2Seq模型用于将任意长度的序列映射到其他任意长度的序列,并已成功地用于机器翻译和图像字幕。 模型训练要点:将一个低采样轨迹(高采样轨迹的子序列)作为输入,一个高采样轨迹作为期
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









