







环境搭建
安装paddlepaddle和paddleSpeech:
pip install paddlepaddlepip install paddlespeech
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型,一些典型的应用如下:
-
声音分类
-
语音识别
-
语音翻译
-
语音合成
相关依赖如下:
-
gcc >= 4.8.5
-
paddlepaddle >= 2.3.1
-
python >= 3.7
-
linux(推荐), mac, windows
-
win必须安装Microsoft C++生成工具
命令行调用
语音分类
paddlespeech cls --input 1.mp3
一段python办公自动化抖音广告语,因为有背景音乐,所以判断为Music。
语音识别
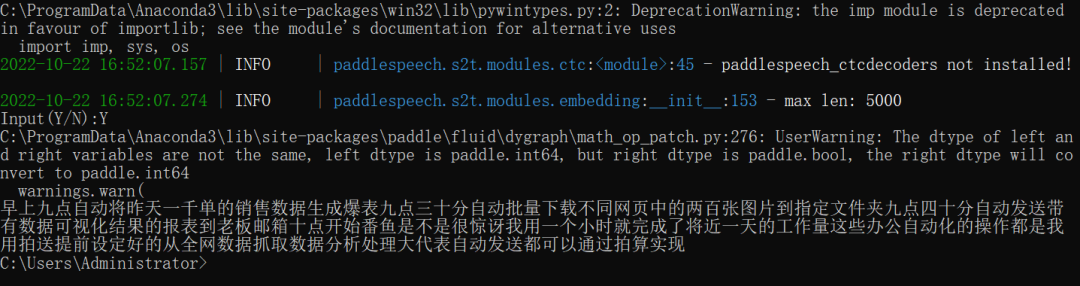
这段广告语被完整识别出来,唯一的问题是不带标点符号。
语音翻译(英翻中)
paddlespeech asr --lang zh --input input_16k.wavwindows暂不支持,但是linux可以。
语音合成
paddlespeech tts --input "你好,欢迎关注电力数据新应用!" --output output.wav
自动生成语音,大数据工匠,2秒
API调用语音识别
from paddlespeech.cli.asr. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4854
4854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









