







导入科学库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("fivethirtyeight")
plt.rcParams["font.sans-serif"] = ["Microsoft YaHei"]
plt.rcParams["axes.unicode_minus"] = False
import warnings
warnings.filterwarnings("ignore")
导入数据
path = "../data/train_data.csv"
data = pd.read_csv(path)
data
| 行ID | 商店ID | 商店类型 | 位置 | 地区 | 日期 | 节假日 | 折扣 | 销量 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | T1000001 | 1 | S1 | L3 | R1 | 2018/1/1 | 1 | Yes | 7011.84 |
| 1 | T1000002 | 253 | S4 | L2 | R1 | 2018/1/1 | 1 | Yes | 51789.12 |
| 2 | T1000003 | 252 | S3 | L2 | R1 | 2018/1/1 | 1 | Yes | 36868.20 |
| 3 | T1000004 | 251 | S2 | L3 | R1 | 2018/1/1 | 1 | Yes | 19715.16 |
| 4 | T1000005 | 250 | S2 | L3 | R4 | 2018/1/1 | 1 | Yes | 45614.52 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 188335 | T1188336 | 149 | S2 | L3 | R2 | 2019/5/31 | 1 | Yes | 37272.00 |
| 188336 | T1188337 | 153 | S4 | L2 | R1 | 2019/5/31 | 1 | No | 54572.64 |
| 188337 | T1188338 | 154 | S1 | L3 | R2 | 2019/5/31 | 1 | No | 31624.56 |
| 188338 | T1188339 | 155 | S3 | L1 | R2 | 2019/5/31 | 1 | Yes | 49162.41 |
| 188339 | T1188340 | 152 | S2 | L1 | R1 | 2019/5/31 | 1 | No | 37977.00 |
188340 rows × 9 columns
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 188340 entries, 0 to 188339
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 行ID 188340 non-null object
1 商店ID 188340 non-null int64
2 商店类型 188340 non-null object
3 位置 188340 non-null object
4 地区 188340 non-null object
5 日期 188340 non-null object
6 节假日 188340 non-null int64
7 折扣 188340 non-null object
8 销量 188340 non-null float64
dtypes: float64(1), int64(2), object(6)
memory usage: 12.9+ MB
查看是否有缺失值
def missing(data):
missing_number = data.isnull().sum().sort_values(ascending = False)
missing_percent = ((data.isnull().sum())/(data.isnull().count())).sort_values(ascending=False)
missing_values = pd.concat([missing_number,missing_percent],axis=1,keys=["missing number","missing percent"])
return missing_values
missing(data)
| missing number | missing percent | |
|---|---|---|
| 行ID | 0 | 0.0 |
| 商店ID | 0 | 0.0 |
| 商店类型 | 0 | 0.0 |
| 位置 | 0 | 0.0 |
| 地区 | 0 | 0.0 |
| 日期 | 0 | 0.0 |
| 节假日 | 0 | 0.0 |
| 折扣 | 0 | 0.0 |
| 销量 | 0 | 0.0 |
由上述可以看出目前的数据表中没有缺失值。但是这是个时间序列问题,因此需要考虑在时间维度中, 时间是否有缺失,稍后再看。
对每个属性进行初步的分析
行ID
assert data["行ID"].nunique() == data.shape[0]
由此可知,行ID数目可以类比为索引。
商店ID
data["商店ID"].unique()
array([ 1, 253, 252, 251, 250, 249, 248, 247, 246, 254, 245, 11, 243,
242, 241, 240, 239, 238, 237, 244, 236, 255, 256, 273, 272, 271,
270, 269, 268, 9, 267, 10, 266, 264, 263, 262, 261, 260, 259,
258, 257, 265, 235, 234, 233, 211, 210, 209, 208, 207, 14, 206,
205, 212, 204, 202, 201, 200, 199, 198, 197, 196, 195, 203, 213,
214, 215, 232, 12, 231, 230, 229, 228, 227, 226, 225, 224, 223,
222, 221, 220, 219, 13, 218, 217, 216, 274, 15, 275, 277, 335,
334, 333, 332, 331, 330, 4, 329, 336, 328, 326, 325, 324, 323,
322, 321, 320, 319, 327, 318, 337, 339, 355, 354, 2, 353, 352,
351, 350, 349, 338, 348, 346, 345, 344, 343, 342, 3, 341, 340,
347, 317, 5, 316, 293, 7, 292, 291, 290, 289, 288, 287, 294,
286, 284, 283, 282, 281, 8, 280, 279, 278, 285, 295, 296, 297,
315, 314, 313, 312, 311, 310, 309, 308, 307, 306, 305, 6, 304,
303, 302, 301, 300, 299, 298, 276, 194, 193, 192, 87, 86, 85,
24, 84, 83, 82, 81, 88, 80, 78, 77, 76, 75, 74, 73,
72, 25, 79, 71, 89, 91, 108, 107, 106, 105, 104, 103, 102,
101, 90, 100, 98, 97, 23, 96, 95, 94, 93, 92, 99, 70,
69, 68, 46, 45, 44, 43, 42, 41, 40, 39, 47, 38, 36,
28, 35, 34, 33, 32, 31, 30, 37, 27, 48, 49, 67, 66,
65, 64, 63, 62, 61, 60, 26, 59, 58, 57, 56, 55, 54,
53, 52, 51, 50, 22, 109, 110, 111, 17, 169, 168, 167, 166,
165, 164, 163, 170, 162, 160, 159, 158, 18, 157, 156, 155, 154,
161, 171, 172, 173, 191, 190, 189, 188, 187, 186, 185, 184, 183,
16, 182, 181, 180, 179, 178, 177, 176, 175, 174, 153, 356, 152,
150, 128, 127, 126, 125, 124, 123, 122, 121, 129, 21, 119, 118,
117, 116, 115, 114, 113, 112, 120, 130, 131, 132, 149, 148, 147,
146, 19, 145, 144, 143, 142, 141, 140, 139, 138, 137, 136, 135,
134, 20, 133, 151, 357, 29, 365, 361, 358, 359, 362, 363, 360,
364], dtype=int64)
data["商店ID"].unique().min(),data["商店ID"].unique().max()
(1, 365)
商店的ID从1到365个类别
商店类型
print("="*30)
print(data["商店类型"].unique())
print("="*30)
print(data["商店类型"].value_counts())
print("="*30)
==============================
['S1' 'S4' 'S3' 'S2']
==============================
S1 88752
S4 45924
S2 28896
S3 24768
Name: 商店类型, dtype: int64
==============================
24768/88752
0.27906976744186046
plt.hist(data["商店类型"],4,alpha=0.7)
(array([88752., 45924., 24768., 28896.]),
array([0. , 0.75, 1.5 , 2.25, 3. ]),
<BarContainer object of 4 artists>)
位置
print("="*30)
print(data["位置"].nunique(),data["位置"].unique())
print("="*30)
print(data["位置"].value_counts())
print("="*30)
==============================
5 ['L3' 'L2' 'L1' 'L5' 'L4']
==============================
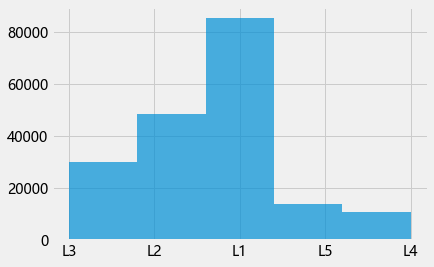
L1 85140
L2 48504
L3 29928
L5 13932
L4 10836
Name: 位置, dtype: int64
==============================
plt.hist(data["位置"],5,alpha=0.7)
地区
print("="*30)
print(data["地区"].nunique(),data["地区"].unique())
print("="*30)
print(data["地区"].value_counts())
print("="*30)
==============================
4 ['R1' 'R4' 'R2' 'R3']
==============================
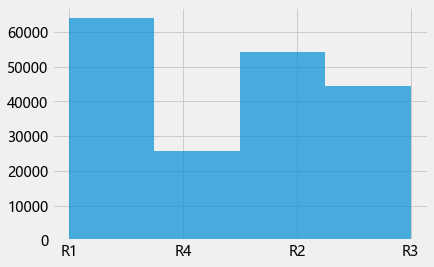
R1 63984
R2 54180
R3 44376
R4 25800
Name: 地区, dtype: int64
==============================
plt.hist(data["地区"],data["地区"].nunique(),alpha=0.7)
(array([63984., 25800., 54180., 44376.]),
array([0. , 0.75, 1.5 , 2.25, 3. ]),
<BarContainer object of 4 artists>)
节日
data["节假日"].value_counts()
0 163520
1 24820
Name: 节假日, dtype: int64
data["节假日"].value_counts()[1]/data["节假日"].value_counts()[0]
0.15178571428571427
折扣
data["折扣"].value_counts()
No 104051
Yes 84289
Name: 折扣, dtype: int6
日期
data["运营日期"] = pd.to_datetime(data["日期"])
针对每个商店,检验日期是否存在不连续的问题。
miss_count = []
for i in data["商店ID"].unique():
date_count_1 = data[data["商店ID"] ==i]["运营日期"].shape[0]
min_date_1 = data[data["商店ID"] ==i]["运营日期"].min()
max_date_1 = data[data["商店ID"] ==i]["运营日期"].max()
miss_count2 = ( max_date_1 - min_date_1 ).days+1 - date_count_1
miss_count.append(miss_count2)
print( np.array(miss_count).sum())
0
因此,在原始数据集中是不存在日期不连续的问题的。
每个商店的位置和地区
for i in data["商店ID"].unique():
num = 0
# print("="*10,i,"="*10)
# print(data[data["商店ID"] ==i]["位置"].unique())
num +=len(data[data["商店ID"] ==i]["位置"].unique())
# print(data[data["商店ID"] ==i]["地区"].unique())
num +=len(data[data["商店ID"] ==i]["地区"].unique())
# print(data[data["商店ID"] ==i]["商店类型"].unique())
num +=len(data[data["商店ID"] ==i]["商店类型"].unique())
if num >3:
print(i)
break
print("done!")
done!
初步结果
初步结论
- 原始数据表中没有缺失值,时间维度也不存在日期不连续的问题。
- 行ID属性即为每个样本的索引,所以这列在分析时候可以不用在意。
- 该数据集中一共有365个商店,4个商店类型,分布在5个不同的位置,4个地区。
- 商店类型中,S1类最多,S3类最少. S 3 : S 1 ≈ 1 : 3 S3:S1≈1:3 S3:S1≈1:3
- 位置类别中, S1类最多,S4类最少. S 4 : S 1 ≈ 1 : 8 S4:S1≈1:8 S4:S1≈1:8
- 地区类别中,R1类最多,R4类最少. R 4 : R 1 ≈ 1 : 2.5 R4:R1≈1:2.5 R4:R1≈1:2.5
- 节假日类别中,1类少,0类多. 1 : 0 ≈ 1 : 8 1:0≈1:8 1:0≈1:8
- 验证了其实每个商店ID确定后,就知道他的位置和地区以及类型。
因此可以尝试考虑多种建模策略
- 针对每个商户分别建模策略。 Prophet/ARIMA可以被作为basine.
- 由于这里分为假期阶段和非假期阶段,所以可以尝试二阶段建模策略,验证其可行性。
- 根据商店的ID号码可以做分类,即转化为多阶段建模问题,同样可以验证其可行性。
- 可以同时考虑点预测和区间预测。
- 由于是为了预测未来两个月的销量,其实可以从循环遍历和直接预测来做。
- 超短期预测遍历未来长时间会有累计误差,因此针对未来一个点的预测精度要尽量的高,机器学习的话,可以从这个角度来尝试。
衡量指标的选取
1.回归问题的评估指标都可以作为时间序列的评估指标,因此
R
2
,
M
A
P
E
R^2,MAPE
R2,MAPE 等都可以作为衡量指标。
2.此外,因为
m
a
p
e
mape
mape分母不能为0,所以也可以考虑将
S
M
A
P
E
SMAPE
SMAPE作为衡量指标。
结尾
数据大小的探索
对于大量数据的话,为了避免内存占用的问题,其实可以尽量的压缩下来。
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 188340 entries, 0 to 188339
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 行ID 188340 non-null object
1 商店ID 188340 non-null int64
2 商店类型 188340 non-null object
3 位置 188340 non-null object
4 地区 188340 non-null object
5 日期 188340 non-null object
6 节假日 188340 non-null int64
7 折扣 188340 non-null object
8 销量 188340 non-null float64
9 运营日期 188340 non-null datetime64[ns]
dtypes: datetime64[ns](1), float64(1), int64(2), object(6)
memory usage: 14.4+ MB
data.dtypes.index.tolist()
['行ID', '商店ID', '商店类型', '位置', '地区', '日期', '节假日', '折扣', '销量', '运营日期']
data.dtypes.values.tolist()
[dtype('O'),
dtype('int64'),
dtype('O'),
dtype('O'),
dtype('O'),
dtype('O'),
dtype('int64'),
dtype('O'),
dtype('float64'),
dtype('<M8[ns]')]
def downcast(df):
cols = df.dtypes.index.tolist()
types =df.dtypes.values.tolist()
for i,t in enumerate(types):
if "int" in str(t):
if df[cols[i]].min()>np.iinfo(np.int8).min and df[cols[i]].max()<np.iinfo(np.int8).max:
df[cols[i]] = df[cols[i]].astype(np.int8)
elif df[cols[i]].min()>np.iinfo(np.int16).min and df[cols[i]].max()<np.iinfo(np.int16).max:
df[cols[i]] = df[cols[i]].astype(np.int16)
elif df[cols[i]].min()>np.iinfo(np.int32).min and df[cols[i]].max()<np.iinfo(np.int32).max:
df[cols[i]] = df[cols[i]].astype(np.int32)
else:
df[cols[i]] = df[cols[i]].astype(np.int64)
elif "float" in str(t):
if df[cols[i]].min()>np.finfo(np.float16).min and df[cols[i]].max()<np.finfo(np.float32).max:
df[cols[i]] = df[cols[i]].astype(np.float32)
else:
df[cols[i]] = df[cols[i]].astype(np.float64)
elif t ==np.object:
if cols[i] =="date":
df[cols[i]] = pd.to_datetime(df[cols[i]],format="%Y-%m-%d")
else:
df[cols[i]] = df[cols[i]].astype("category")
return df
df= downcast(data)
NameError: name 'downcast' is not defined
df.info()
数据的保存
# data.to_csv("../preocess_data/train_data_o.csv",index=False)
df.to_csv("../preocess_data/train_data_d.csv",index=False)
data
| 行ID | 商店ID | 商店类型 | 位置 | 地区 | 日期 | 节假日 | 折扣 | 销量 | 运营日期 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | T1000001 | 1 | S1 | L3 | R1 | 2018/1/1 | 1 | Yes | 7011.84 | 2018-01-01 |
| 1 | T1000002 | 253 | S4 | L2 | R1 | 2018/1/1 | 1 | Yes | 51789.12 | 2018-01-01 |
| 2 | T1000003 | 252 | S3 | L2 | R1 | 2018/1/1 | 1 | Yes | 36868.20 | 2018-01-01 |
| 3 | T1000004 | 251 | S2 | L3 | R1 | 2018/1/1 | 1 | Yes | 19715.16 | 2018-01-01 |
| 4 | T1000005 | 250 | S2 | L3 | R4 | 2018/1/1 | 1 | Yes | 45614.52 | 2018-01-01 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 188335 | T1188336 | 149 | S2 | L3 | R2 | 2019/5/31 | 1 | Yes | 37272.00 | 2019-05-31 |
| 188336 | T1188337 | 153 | S4 | L2 | R1 | 2019/5/31 | 1 | No | 54572.64 | 2019-05-31 |
| 188337 | T1188338 | 154 | S1 | L3 | R2 | 2019/5/31 | 1 | No | 31624.56 | 2019-05-31 |
| 188338 | T1188339 | 155 | S3 | L1 | R2 | 2019/5/31 | 1 | Yes | 49162.41 | 2019-05-31 |
| 188339 | T1188340 | 152 | S2 | L1 | R1 | 2019/5/31 | 1 | No | 37977.00 | 2019-05-31 |
188340 rows × 10 columns















 9066
9066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









