







在上一篇的文章中已经给大家详细讲述了随机森林的理论原理,如果说大家想详细了解的话,可以去看我上一章的随机森林算法解密,今天给大家呈现的是随机森林算法的实际应用,我们使用的是Kaggle平台上的Walmart Sales数据集,如果后面大家想尝试相关的操作,需要数据集,也可以到我的公众号“明天科技屋”回复关键词领取,我们将基于该数据的内容对商品销售额进行预测,没错,我们展示的是随机森林回归模型。
首先,我们对该数据集进行一个简单的介绍:
| 列名 | 含义 |
| Store | 商店数量 |
| Date | 日期 |
| Weekly_Sales | 周销售额 |
| Holiday_Flag | 是否假期 |
| Temperature | 温度 |
| Fuel_Price | 燃料成本 |
| CPI | 居民消费价格指数 |
| Unemployment | 失业率 |
详细数据展示:
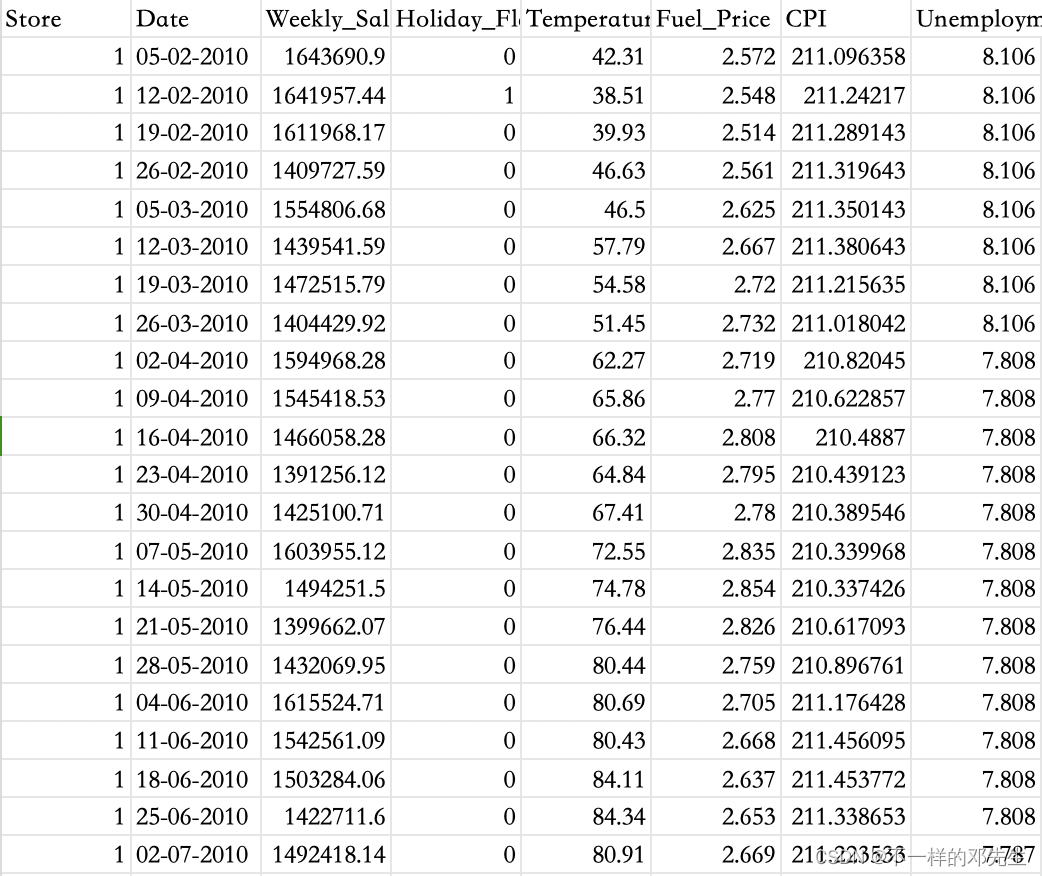
我们接下来将会利用该数据进行构建随机森林回归模型,并详细讲解模型的中的每一步,首先还在相关的依赖包,导入模块代码如下:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score在导入依赖之后,我们接下来将进行数据加载、数据预处理、数据标准化等操作,我们首先查看了一下数据结构以及各个特征等数据分布
walmart = pd.read_csv('./data/Walmart_sales.csv')
walmart.info()
walmart.describe()图片如下:

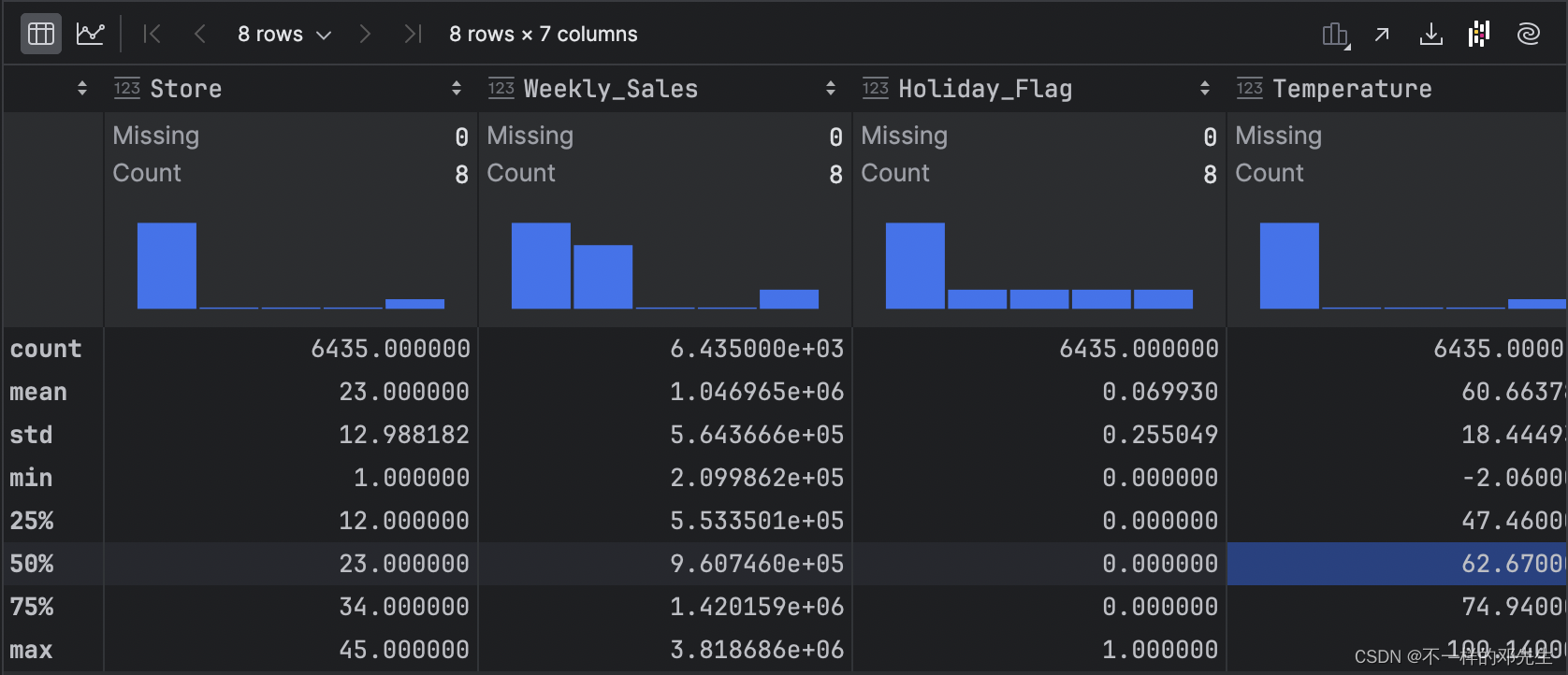
在数据结构中,我们发现所有特征数据都是完整的,不存在缺失值,因此我们不进行缺失值处理,接着,我们对一些数值型特征进行分布可视化操作,查看一下不同特征数据对分布以及是否存在异常值等,代码如下:
# 绘制不同特征的分布图
plt.figure(figsize=(16, 12))
data_columns=walmart[['Weekly_Sales','Temperature','Fuel_Price','CPI','Unemployment']].columns.tolist()
for index in range(len(data_columns)):
plt.subplot(3, 2, index+1)
sns.histplot(walmart[data_columns[index]], kde=True, color='skyblue')
plt.title('Feature'+str(index)+'Distribution')
plt.tight_layout()
plt.savefig('distribution.png')结果如下: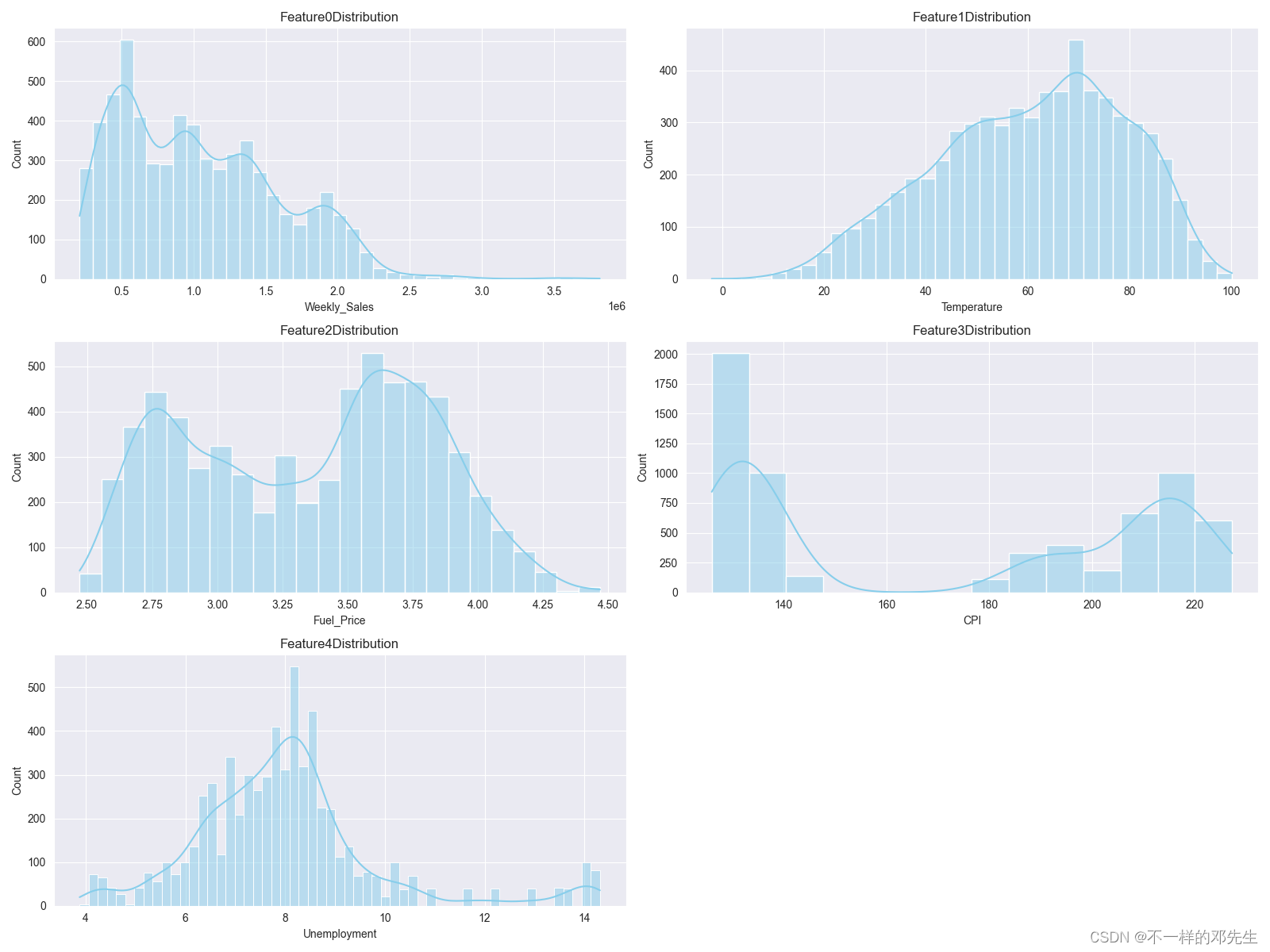
大家可以从图中展示结果可以看出,大部分特征总体上是保持正态分布,但是还是有部分数据呈现严重偏态分布,例如:周销售额数据呈现严重的右偏,同时还可能存在异常值数据,因此,我们对数据进行异常值检测和处理,代码如下:
# 计算每列的上界和下界
Q1 = walmart[['Store','Weekly_Sales','Temperature','Fuel_Price','CPI','Unemployment']].quantile(0.25)
Q3 = walmart[['Store','Weekly_Sales','Temperature','Fuel_Price','CPI','Unemployment']].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 标记异常值
outliers = ((walmart[['Store','Weekly_Sales','Temperature','Fuel_Price','CPI','Unemployment']] < lower_bound) | (walmart[['Store','Weekly_Sales','Temperature','Fuel_Price','CPI','Unemployment']] > upper_bound)).any(axis=1)
# 删除异常值
new_walmart = walmart[~outliers]
print("清洗后的数据:")
print(new_walmart)我们采用分位数距离的1.5倍为浮动区间,对数据进行选择,并对选择之后的数据观察分布,经过处理之后,数据分布逐渐成正态分布,我们就以周销售额数据分布为例进行展示,
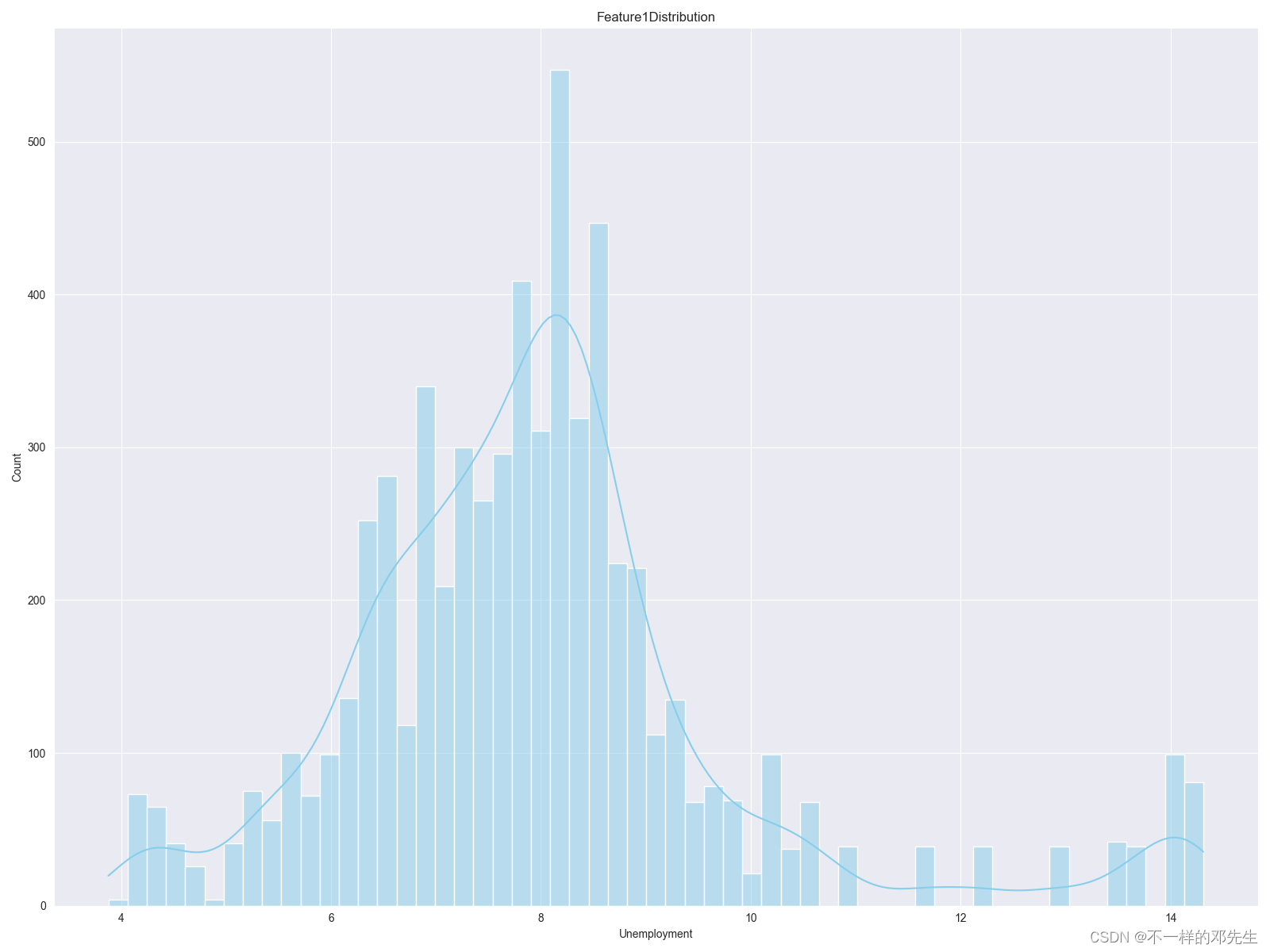
在进行异常值检测和处理之后,就进入到数据标准化处理了,同时将标准化之后的数据与分类类型数据和周销售额数据进行拼接,由于分类类型数据是二分类数据,并且转换成0,1数值变量,所以我们不再做额外的编码处理,代码如下:
# 假设data是包含连续型数据的DataFrame
scaler = StandardScaler()
data_scaled = scaler.fit_transform(new_walmart[['Store','Temperature','Fuel_Price','CPI','Unemployment']])
# 将One-Hot编码后的数据转换为DataFrame
data_scaled = pd.DataFrame(data_scaled, columns=new_walmart[['Store','Temperature','Fuel_Price','CPI','Unemployment']].columns)
data_scaled['Weekly_Sales'] = new_walmart[['Weekly_Sales']].reset_index(drop=True)
data_scaled['Holiday_Flag'] = new_walmart[['Holiday_Flag']].reset_index(drop=True)数据标准化处理是模型训练的前奏了,因此,接下来的工作就是模型训练调优,调优方式我们使用网格搜索和5折交叉验证进行,代码如下:
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data_scaled[['Store','Temperature','Fuel_Price','CPI','Unemployment','Holiday_Flag']], data_scaled['Weekly_Sales'], test_size=0.3, random_state=42)
#定义超参数网格
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [10,15, 20],
'min_samples_split': [2, 5, 10]
}
rf_regressor = RandomForestRegressor()
# 使用 GridSearchCV 进行网格搜索和交叉验证
grid_search = GridSearchCV(estimator=rf_regressor, param_grid=param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
# 输出最佳参数
best_params = grid_search.best_params_
print("Best parameters:", best_params)将数据划分为训练集、测试集数据之后,我们使用了训练集数据进行模型训练和调优,当然调优是采用交叉验证将训练集数据划分一部分为验证集数据进行的,在训练完模型之后,我们还有更重要的一步就是使用外部数据集也就是测试集数据评估模型性能,对于回归模型性能的评估常用的指标有均方误差(MSE)、均方根误差(RMSE)、绝对误差以及等,测试集数据用于测试模型在未知数据上的表现,如果模型在训练集上表现好,但是在测试集上表现差说明模型有过拟合风险,代码如下:
# 在测试集上评估模型
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)
mse = mean_squared_error(y_test, y_pred, squared=False)
print("MSE:", mse)
# 计算均方根误差(Root Mean Squared Error)
rmse = np.sqrt(mse)
print("Root Mean Squared Error:", rmse)
# 计算平均绝对误差(Mean Absolute Error)
mae = mean_absolute_error(y_test, y_pred)
print("Mean Absolute Error:", mae)
# 计算决定系数(Coefficient of Determination)
r2 = r2_score(y_test, y_pred)
print("R^2 Score:", r2)结果如下: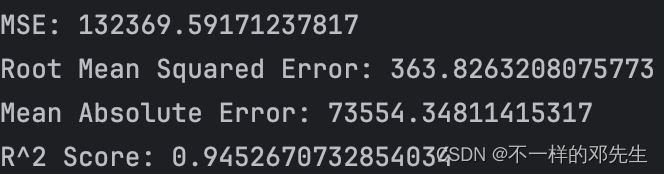
总的来说,均方误差、均方根误差、绝对误差指标都不是很大,同时系数也比较高,说明模型性能比较好,以上就是随机森林实际操作的全部内容,希望大家多多关注公众号“明天科技屋”,更多优质内容为你呈现,如果大家也想使用该数据集进行操作,进入公众号回复关键词即可。



















 1522
1522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











