






R-CNN这个领域目前研究非常活跃,先后出现了R-CNN,SPP-net,Fast R-CNN,Faster R-CNN,R-FCN,YOLO,SSD等研究,Ross Girshick(rbg大神)作为这个领域的开山鼻祖总是神一样的存在,R-CNN、Fast R-CNN、Faster R-CNN、YOLO都和他有关。这些创新的工作其实很多时候是把一些传统视觉领域的方法和深度学习结合起来了,比如选择性搜索(Selective Search)和图像金字塔(Pyramid)等。
深度学习相关的目标检测方法也可以大致分为两派:
基于区域提名的,如R-CNN, SPP-net, Fast R-CNN, Faster R-CNN, R-FCN;
端到端(End-to-End)无需区域提名的,如YOLO, SSD。
发展历程:
————————————————
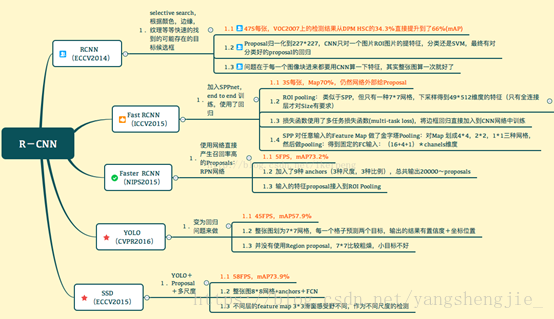
基于区域提名的R-CNN家族
R-CNN解决的是,“为什么不用CNN做classification呢?”
Fast R-CNN解决的是,“为什么不一起输出bounding box和label呢?”
Faster R-CNN解决的是,“为什么还要用selective search呢?”
R-CNN
2014年提出,其意义在于:CNN除了在object classification领域的有一大的应用,证明了CNN的广泛应用性,导致深度学习在成为非常热门的一个研究方向。R-CNN主要是应用在object detection领域,传统的识别是一张图片中有一个物体,而R-CNN是用来识别一个图片中的若干张物体的方法。
实现过程:
区域提名:通过Selective Search算法产生2k~ region proposals;
区域大小归一化:将产生的所有的boxes resize成固定的size(原文采用227×227,作为CNN网络的输入,用来选取特征);
特征提取:通过CNN网络,提取特征;
分类与回归:在特征层的基础上添加两个全连接层,再用SVM分类器用来判断whether this is an object, and if so what object,在boxes中找到object之后,通过对所有的region proposals run a simple linear regression to generate tighter bounding box coordinates.
Bottlenecks:
每张图片需要运行2k次CNN去寻找特征,耗时耗计算能力;
我们需要训练三个不同的模型:the CNN to generate image features;the Classifier that predicts the class; the Regression model to tighten the bounding boxes;
时间空间上很大的缺点:区域提名、特征提取、分类、回归都是断开的训练的过程,中间数据还需要单独保存;卷积出来的特征需要先存在硬盘上,这些特征需要几百G的存储空间;另外,时间消耗很大,GPU上处理一张图片需要13秒,CPU上则需要53秒。
Fast RCNN
Insight 1:RoI (Region of Interest) Pooling
这是fast r-cnn最大的一个创新,利用SPPNet提出的 RoI(Region of Interest) Pooling思想,对每张图片经过一次CNN网络之后产生一个feature map(尺寸大小为C * M * N,C为channels,即最后一层卷积层neuron的个数), Selective Search得到~2k个框,每个框对应feature map中的一个channel的feature,我们对得到的每个channel的feature统一化分成x*y的格子,每个格子进行max pooling来舍弃边缘特征,得到不同channel的相同尺寸以便接下来进行分类和回归使用。
怎么确定target的尺寸(x,y)呢?一个简单的想法是取所有channel层的特征层的尺寸的最大公约数,或者取2的倍数。

Insight 2:Combine All Models into One Network
replace the SVM classifier with a softmax layer on top of the CNN to output a classification.
add a linear regression layer parallel to the softmax layer to output bounding box coordinates.
运行过程:
特征提取:以整张图片为输入利用CNN得到图片的feature map;
区域提名:通过Selective Search等方法从原始图片提取1000-2000个区域候选框,并把这些候选框一一投影到最后的feature map;
区域归一化:针对特征层上的每个区域候选框进行RoI Pooling操作,得到固定大小的特征表示;
分类与回归:然后再通过两个全连接层,分别用softmax多分类做目标识别,用回归模型进行边框位置与大小微调。
Bottlenecks:
region proposal generating strategies
Faster R-CNN
Insight: the convolutional feature maps used by region-based detectors, can also be used for generating region proposals [nearly cost-free region proposals].
运行过程:
特征提取:对整张图片输进CNN,得到feature map;
区域提名:在最终的卷积特征层上利用RPN(Region Proposal Networks)网络来计算k个不同的矩形候选框(Anchor Box)进行提名,k一般取9;
分类与回归:对每个Anchor Box对应的区域进行object/non-object二分类,并用k个回归模型(各自对应不同的Anchor Box)微调候选框位置与大小,最后进行目标分类。
RPN(Region Proposal Networks)
Faster R-CNN adds a Fully Convolutional Network on top of the features of the CNN creating what’s known as the Region Proposal Network.
RPN过程是用一个窗口(比如3*3)在feature map上面移动,移动的slide比如为5,然后每个位置产生k(比如k=9)个anchors,anchor的尺寸大小角度根据我们检测的具体目标而定,比如检测的目标是人,则我们的bounding box需要very thin。另外,k个anchors产生2k个scores(background or foreground)和4k个coordinates(左上和右下的坐标值,四个数)
举例:
Input size : 600*800, Stride=16, Anchers= 9
600/16向上取整+1 = 39, 800/16向上取整+ 1 =51, 共有1989 (39x51) positions, 即共有17901 (1989 x 9) boxes
600x800的图片经过16次变换得到一个39x51的feature map, 特征图的每个位置有9 anchors, and 每个anchor有两个可能的值 (background, foreground). 如果我们认为特征图的深度为18 (9 anchors x 2 labels), 那么每个anchor将会有一个vector with two values (normal called logit), If we feed the logit into a softmax/logistic regression activation function, it will predict the labels.
未完待续,End-to-End提名策略...
————————————————















 3134
3134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









