







本文为本人另两篇博客机器学习/计算机视觉(cv)实习面试资料整理(附字节、阿里、腾讯、美团面经)以及机器学习知识点整理下的子内容,有需要的朋友按需自取~
另:本文只是知识点的整理概括,更为详细的可以参考我每个部分给出的链接~
本文参考链接:EM算法详解和HMM算法详解(内含推导)
这两篇讲的比较详细,我的博客只是对它的一个总结概括,大家想更详细了解的可以看这两篇文章
摘要
- EM(Expectation-Maximum)算法也称期望最大化算法,曾入选“数据挖掘十大算法”中,可见EM算法在机器学习、数据挖掘中的影响力。EM算法是最常见的隐变量估计方法,在机器学习中有极为广泛的用途,例如常被用来学习高斯混合模型(Gaussian mixture model,简称GMM)的参数;隐式马尔科夫算法(HMM)、LDA主题模型的变分推断等等。
EM
概述
- EM:最大期望算法(Expectation-maximization algorithm,又译为期望最大化算法),是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐性变量;
- 最大期望算法经过两个步骤交替进行计算:
第一步是计算期望(E),利用对隐藏变量的现有估计值,计算其最大似然估计值;
第二步是最大化(M),最大化在E步上求得的最大似然值来计算参数的值。M步上找到的参数估计值被用于下一个E步计算中,这个过程不断交替进行;
算法步骤
输入:观察到的数据 x = ( x 1 , x 2 , . . . , x n ) x = (x1,x2,...,xn) x=(x1,x2,...,xn),联合分布 p ( x , z ; θ ) p(x,z;θ) p(x,z;θ) ,条件分布 p ( z ∣ x , θ ) p(z|x,θ) p(z∣x,θ),最大迭代次数J;
算法步骤:
(1)随机初始化模型参数θ的初值θ0。
(2)j=1,2,…,J 开始EM算法迭代:
- E步:计算联合分布的条件概率期望:
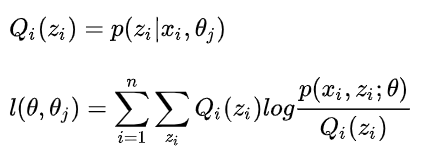
- M步:极大化
l
(
θ
,
θ
j
)
l(θ,θj)
l(θ,θj) ,得到
θ
j
+
1
θj+1
θj+1:
![[公式]](https://img-blog.csdnimg.cn/20210422133013414.png)
- 如果 θ j + 1 θj+1 θj+1已经收敛,则算法结束。否则继续进行E步和M步进行迭代;
输出:模型参数θ;
总结
EM算法是迭代求解最大值的算法,同时算法在每一次迭代时分为两步,E步和M步。一轮轮迭代更新隐含数据和模型分布参数,直到收敛,即得到我们需要的模型参数。
一个最直观了解EM算法思路的是K-Means算法。在K-Means聚类时,每个聚类簇的质心是隐含数据。我们会假设K个初始化质心,即EM算法的E步;然后计算得到每个样本最近的质心,并把样本聚类到最近的这个质心,即EM算法的M步。重复这个E步和M步,直到质心不再变化为止,这样就完成了K-Means聚类。当然,K-Means算法是比较简单的,高斯混合模型(GMM)也是EM算法的一个应用。
HMM
HMM结构

-
HMM的就是计算z1与z2之间的关系,z与x之间的关系,这两个关系也就是HMM的参数我们设置为A和B;
-
A 是一个矩阵,每一行都对应一个状态z其中的值表示下一状态出现的概率,状态转移矩阵:

-
B也是一个矩阵,也就是表示z状态下生成x的概率:

解决的三个问题
- 给定模型找到最优的状态z:参数A , B , π已经训练好了,我们直接利用可观测值x来进行反推状态z;暴力求解+维特比算法求解;
- 给定一系列观测值计算参数也就是:A , B 和 π;向前向后算法+EM算法;
- 已知模型λ(A,B,π)和观测序列,计算该观测序列出现的概率;
HMM两大假设
- 隐藏的马尔科夫链在t时刻的状态只和t-1时刻有关,和之前的其他时刻无关;
- 观测独立性假设。每个观测至于该时刻的隐藏状态有关,和其它观测状态无关;















 2617
2617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









