






教程内容包含分类变量、连续变量、单个率的Meta分析。
一、分类变量
1.数据输入格式:
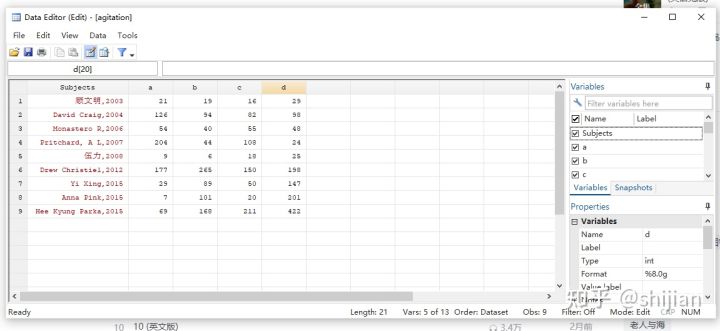
注:“a”代表试验组阳性数量,“b”代表试验组阴性数量,“c”代表对照组阳性数量,“d”代表对照组阴性数量。(代码中a、b、c、d同)
2. 森林图代码:metan a b c d, counts or fixed group1(对照组名字) group2(治疗组名字) lcols(Subjects) texts(110)
森林图亚组分析代码:metan a b c d, counts or fixed group1(对照组名字) group2(治疗组名字) lcols(Subjects) texts(110) by(subunit)
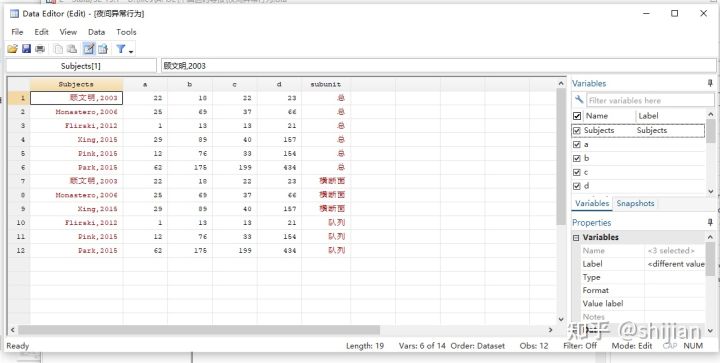
注:or代表比值比;fixed代表固定效应模型,可换成random随机效应模型;texts代表图的大小,里面数值可自行设置;by()是亚组分析的代码,subunit是自定义的亚组列的名字,可自行设置,和a,b,c,d的类型及设置一样。具体见下图。
3.敏感性分析:metaninf a b c d, label(namevar = Subjects) fixed or
4.漏斗图metafunnel _ES _selogES
5.发表偏移
Egger法
gen logor=log(a/b)/(c/d)
gen selogor=sqrt((1/a)+(1/b)+(1/c)+(1/d))
metabias logor selogor, egger
Begg法
gen logor=log(a/b)/(c/d)
gen selogor=sqrt((1/a)+(1/b)+(1/c)+(1/d))
metabias logor selogor, begg
二、连续变量
1.数据输入格式:

注:“tn”代表试验组样本量,“tmean”代表试验组均值,“tsd”代表试验组方差,“cn”代表对照组样本量,“cmean”代表对照组均值,“csd”代表对照组方差。(代码中同)
2.森林图代码:metan tn tmean tsd cn cmean csd, label(namevar=studies) random
森林图亚组分析代码:metan tn tmean tsd cn cmean csd, label(namevar=studies) random cohen by(subunit)
metan tn tmean tsd cn cmean csd, label(namevar=studies) fixed cohen by(subunit)
注:random代表随机效应模型,可换成fixed固定效应模型;by()是亚组分析的代码,subunit是自定义的亚组列的名字,可自行设置。
3.漏斗图metafunnel _ES _selogES
三、单个率的meta分析
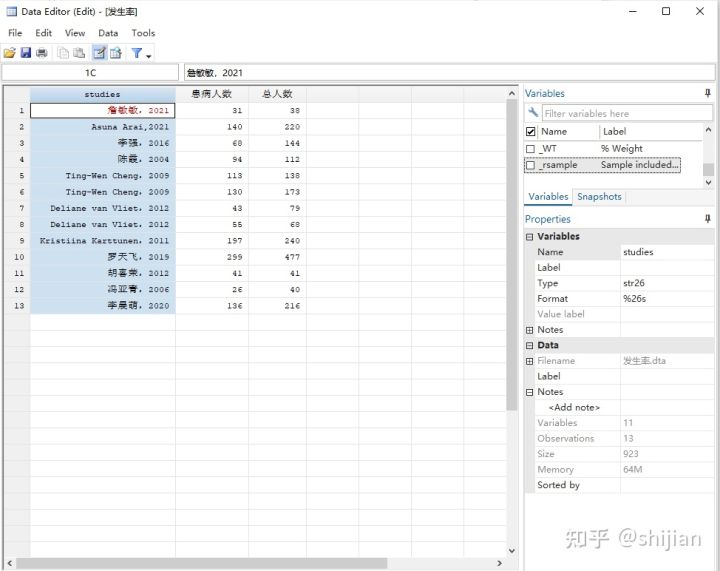
1.数据输入格式
2.stata代码
stata代码:森林图:gen rate=患病人数/总人数;
gen ser=sqrt(rate*(1-rate)/总)
metan rate ser, label(namevar=studies) random
敏感性分析:metaninf rate ser, label(namevar = studies) random or

















 1427
1427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









