







聚类
聚类任务
“无监督学习”的目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”。通过这样的划分,每个簇可能对应于一些潜在的概念(类别),这些概念对聚类算法而言事先是未知的,聚类过程仅能自动形成簇结构,簇所对应的概念语义由使用者来把握和命名。
性能度量
聚类性能度量亦称聚类“有效性指标”。
类别:将聚类结果与某个“参考模型”进行比较,称为“外部指标”;直接参考聚类结果而不利用任何参考模型,称为“内部指标”。
常用的聚类性能度量外部指标:
- Jaccard系数(Jaccard Coefficient,简称JC)
- FM指数(Fowlkes and Mallows Index,简称FMI)
- Rand指数(Rand Index,简称RI)
常用的聚类性能度量内部指标:
- DB指数(Davies-Bouldin Index,简称DBI)
- Dunn指数(Dunn Index,简称DI)
距离计算
距离度量需满足一些基本性质:非负性、同一性、对称性、直递性,主要有闵可夫斯基距离、欧氏距离、曼哈顿距离
属性分类:
- 连续属性:在定义域上有无穷多个可能的取值
- 离散属性:在定义域上有限个取值
- 有序属性:可以直接在属性值上计算距离
- 无序属性:不能直接在属性值上计算距离
有序属性可使用闵可夫斯基距离,而无序属性则使用VDM
原型聚类
原型聚类亦称“基于原型的聚类”,此类算法假设聚类结构能通过一组原型刻画。通常情形下,算法先对原型进行结构化,然后对原型进行迭代更新求解。
- k均值算法
- 学习向量量化
- 高斯混合聚类
密度聚类
密度聚类亦称“基于密度的聚类”,此类算法假设聚类结构能通过样本分布的紧密程度确定。通常情形下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果。【DBSCAN】
层次聚类
层次聚类视图在不同不同层次对数据集进行划分,从而形成树形的聚类结构,数据集的划分可采用“自底向上”的聚合策略,也可采用“自顶向下”的分拆策略。【AGNES算法】
降维与度量技术
k近邻学习
k近邻学习工作机制:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息进行预测。
- “投票法”:选择这k个样本中出现最多的类别标记作为预测结果
- “平均法”:将这k个样本的实值输出标记的平均值作为预测结果
- “懒惰学习”:在训练阶段仅仅是把样本保存起来,训练时间开销为零,待收到测试样本后再进行处理
- “急切学习”:在训练阶段就对样本学习处理的方法
最近邻分类器虽然简单,但它的泛化错误率不超过贝叶斯最优分类器的错误率的两倍。
低维嵌入
维数灾难:在高维清形下出现的数据样本稀疏,距离计算困难等问题。
维数约简:通过某种数学变化将原始高位属性空间转变为一个低维“子空间”,在这个子空间中样本密度大幅提高,距离计算也变得更为容易。
低维嵌入:在很多时候,人们观测或收集到的数据样本虽是高维的,但与学习任务密切相关的也许仅是某个低维分布。
主成分分析
对于正交属性空间中的样本点,用一个超平面(直线的高维推广)对所有样本进行恰当的表达:
- 最近重构性:样本点到这个超平面的距离都足够近
- 最大可分性:样本点在这个超平面上的投影能尽可能分开
PCA仅需保留W与样本的均值向量即可通过简单的向量减法和矩阵-向量乘法将新样本投影至低维空间中,所舍弃的部分信息既可以使样本的采样密度增大,也能在一定程度上起到去噪的效果。
核化线性降维
“本真”低维空间:“原本采样的”低维空间
非线性降维:基于核技巧对线性降维方法进行“核化”
流形学习
“流形”是在局部与欧式空间同胚的空间,其在局部具有欧式空间性质,能用欧式距离进行距离计算。
若低维流形嵌入到高维空间中,则数据样本在高维空间的分布虽然看上去非常复杂,但在局部上仍具有欧式空间的性质,因此,可以容易地在局部建立降维映射关系,然后再设法将局部映射关系推广到全局。
等度量映射
基本出发点:低维流形嵌入到高维空间之后,直接在高维空间中计算有线距离具有误导性,因为高维空间中的直线距离在低维嵌入流形上是不可达的。
可利用流形在局部上与欧式空间同胚性质,对每个点基于欧式距离找出其邻近点,然后就能建立一个近邻连接图,图中近邻点之间存在连接,而非邻近点之间不存在连接。于是,计算两点之间测地线距离的问题,就转变为计算近邻连接图上两点之间的最短路径问题。
近邻图的构建:指定近邻点的个数、指定距离阈值(小于阈值的点被认为是近邻点)
局部线性嵌入
局部线性嵌入试图保持邻域内样本之间的线性关系
度量学习
基本动机:“学习”出一个合适的距离度量
马氏距离:
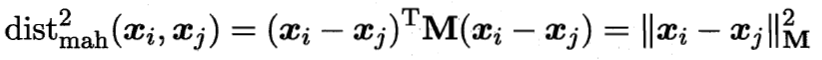
其中M亦称“度量矩阵”,而度量学习则是对M进行学习。为了保持距离非负且对称,M必须是(半)正定对称矩阵,即必有正交基P使得M能写为M=PP^T。
不仅能把错误率作为度量学习的优化目标,还能在度量学习中引入领域知识。














 882
882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









