







STRATEGIES FOR PRE-TRAINING GRAPH NEURAL NETWORKS
ICLR2020,Stanford出品。用于GNN的预训练策略。
paper:https://openreview.net/forum?id=HJlWWJSFDH¬eId=HJlWWJSFDH
code:https://github.com/snap-stanford/pretrain-gnns/
预训练从CV领域开始取得了很好的效果,到BERT在NLP大杀四方,终于Graph也开始Pretraning了吗??
动机始于两点:
- 特定于任务的标签数据可能极其稀缺。这个问题在重要的科学领域的图数据集中更加严重,例如在化学和生物学等领域中,数据标签化是资源和时间密集型的。
- 来自真实世界应用的图形数据往往包含分布外样本,这意味着训练集中的图形与测试集中的图形在结构上有很大的差异。例如想要预测一个全新的、刚刚合成的分子的化学特性时,这个分子与迄今为止合成的所有分子不同,从而与训练集中的所有分子不同。
但是一个成功的迁移学习不仅仅是增加与下游任务来自同一领域的标注好的预训练数据集。相反,它需要大量的领域专业知识来仔细选择与感兴趣的下游任务相关的样本和目标标签。否则,可能带来反效果,被称之为Negative Transfer,也就是说虽然预训练了可能反而效果更差,这种情况作者认为直接在整图级预测任务下更为突出。
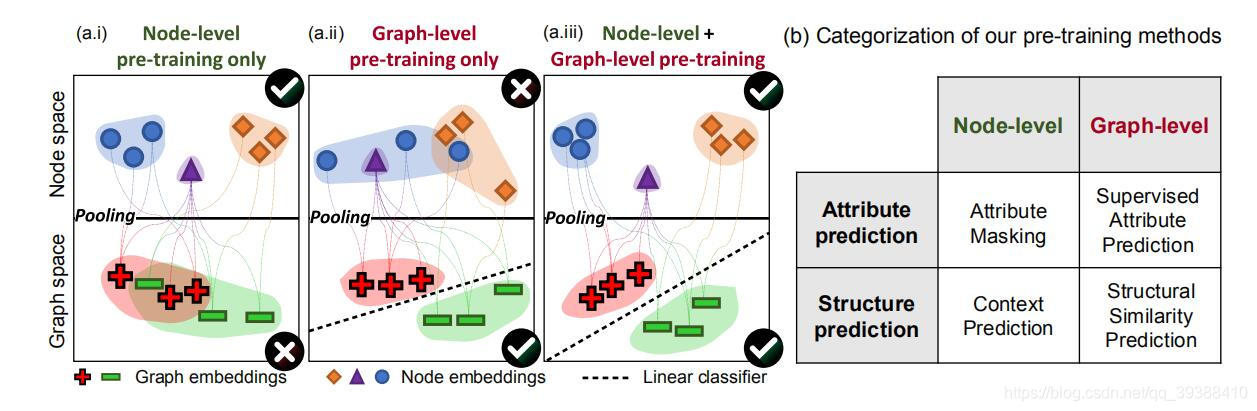
所以本文的训练核心思想是添加用易于得到的节点级别的信息,去让GNN捕获节点与边以及图级别的特定领域的知识。即同时在独立的节点级别与全图级别去预训练GNN,如下图所示:
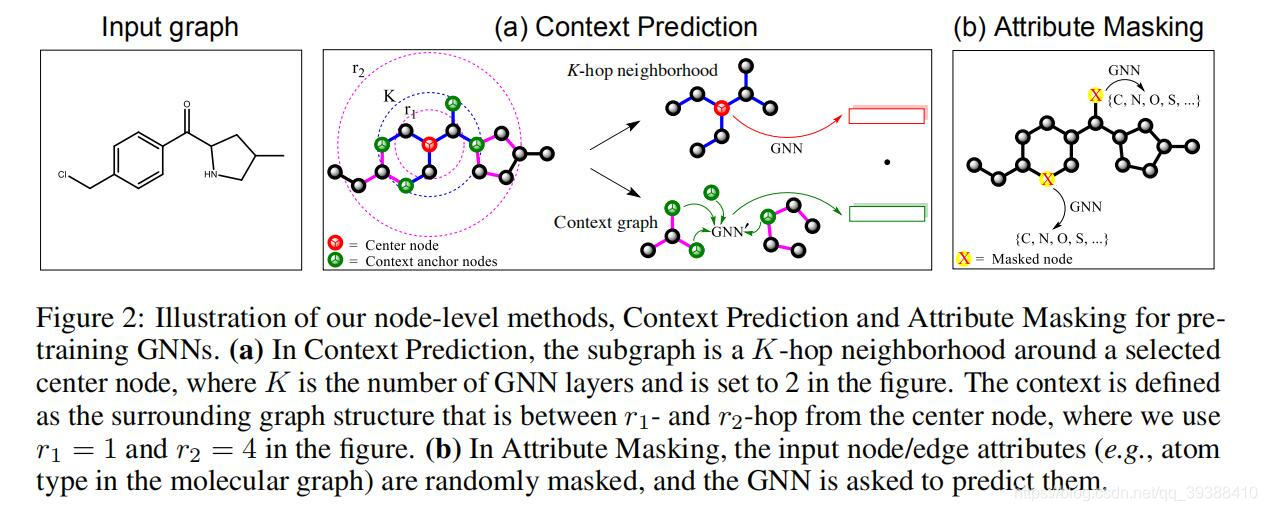
节点级预训练可以捕获图中特定领域的知识/规则性,作者提出了两种自监督的方法,即Context Prediction(上下文预测)和Attribute Masking(属性掩码)。
Context Prediction
使用子图来预测周围的图结构,目标是将出现在相似结构上下文中的节点映射到邻近的嵌入。如图a,对于每个结点v,k-跳邻居包括距离结点v最多k跳的所有结点和边(K层GNN在v的K阶邻域中聚集信息)。上下文图定义为围绕v的邻域的图结构(由r1和r2两个参数控制,即一个圆环的范围即为子图),其中r1 < K,这样一些节点在邻域图和上下文图之间共享,这些节点称为上下文锚节点。这些锚节点提供了关于邻域图和上下文图之间如何相互连接的信息。
然后对子图进行embedding编码成一个固定向量(对锚节点求平均),同时进行负采样训练,即用定义好了的这个上下文子图context graph和邻居做训练,判断两者是否相似,负采样是其他的邻居(随机采样得到),也就自然和这个图向量不相似。
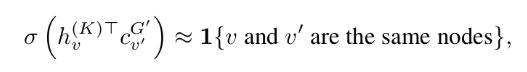
其中负采样率为1,即正负样本数量相等,使用负对数似然函数作为损失函数(二分类)。
Attribute Masking
目的是通过学习图结构上节点/边属性分布的规律,捕获到领域知识。masking可以和BERT的masking做对比,如图b,作者对节点/边属性进行掩码,然后让GNNs基于相邻结构预测这些属性。
图级预训练也有两种选择:Supervised Graph-Level Property Prediction和Structual Simailarity Prediction。即对整个图的域特定属性进行预测(如监督标签),或者对图结构进行预测。
Supervised Graph-Level Property Prediction
由于图级别的表示 h G h_G hG 是直接用于下游预测任务的微调的,所以需要将特定领域的信息编码进去。所以作者考虑了一种实用的图表示的预训练方法:图级多任务有监督的预训练,以共同预测多个图的label,即每个属性都对应于一个二分类任务,在得到图的表示后经过一个线性分类器。
但是朴素的直接将多任务图级别的预训练可能在迁移的时候失效,即执行广泛的多任务图级预训练可能无法给出可转移的图级表示,因为这些任务可能与下游任务无关,造成negative transfer,一些无意义的节点会与训练任务会互相干扰。所以本文预训练的策略是:首先进行节点级别的预训练,然后再进行图级别的预训练。预训练结束后,再将得到的GNN模型在下游任务中进行微调,图级别的表示经过线性分类器后预测下游任务的图标签。
至于Structual Simailarity Prediction,作者也没有做,主要是因为graph相似度的度量困难,目前没有一个比较好的定义。
源码解析
作者的代码基于pytorch,源码链接在开头。
首先看看Context Prediction部分的代码:
def train(args, model_substruct, model_context, loader, optimizer_substruct, optimizer_context, device):
model_substruct.train()#调成训练模式
model_context.train()
balanced_loss_accum = 0
acc_accum = 0
for step, batch in enumerate(tqdm(loader, desc="Iteration")):
batch = batch.to(device)
#创建子图的表示
substruct_rep = model_substruct(batch.x_substruct, batch.edge_index_substruct, batch.edge_attr_substruct)[batch.center_substruct_idx]
###创建上下文的表示
overlapped_node_rep = model_context( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









