










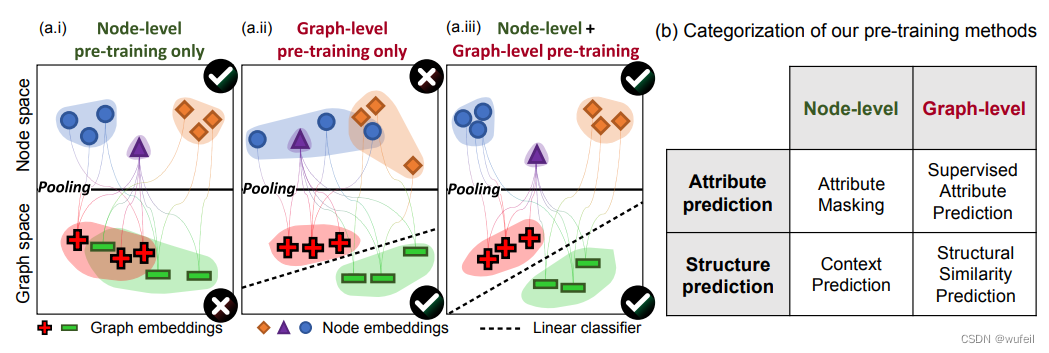
到目前为止,Conetext prediction 和 Attribute Prediction 两种节点和边层面的预训练方法,及其之后的图层面的分子性质监督学习预测,都已经介绍完毕。
基本上,Strategies for Pre-training Graph Neural Networks 简介已经结束,并且提供了可以直接运行的代码及其环境。代码见之前文章的链接。
现在来总结一下,其中包含的有用的内容:
1. 分子由SMILES生成pyg图;
2. 分子pyg图组成批次的dataloader,包括自定义的特征组合;
3. GIN及GAT等多个模型;
4. Conetext prediction预训练方法,模型学习(接受)子结构相似嵌入特征相似的约束;
5. Attribute Prediction预训练方法,模型学习(接受)不同节点/边类型嵌入向量不同的约束;
6. 预训练模型用于图层面的监督学习的使用方法;
7. 结论,预训练确实有效果,预训练可以减少迭代次数,在graph transformer等复杂的图神经网络中更明显。对于GIN等较为简单的图神经网络,通过多次迭代,也是可以达到预训练的结果。
8. 当前模型预训练效果受限于分子的表示方法,使用119种原子种类,4种原子空间构型,以及4种边并不能很好的表示分子,对于当前的深度学习模型来说,太难了,导致预训练效果仍存在提升空间。















 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









