







在前一篇目标检测(R-CNN,SPP,Fast R-CNN,Faster R-CNN),所整理的R-CNN,SPP,Fast R-CNN,Faster R-CNN中,这些目标检测技术都只是两阶段网络,比如性能相对来说最好的Faster R-CNN,是先用RPN生成候选目标区域,然后再进行Fast R-CNN的方法,继续目标对象的分类和边框的回归预测。但是那有办法一步做完这些事吗?
YOLO
YOLO是一个很重要的目标检测框架,准确率和检测速度都非常好也已经进化更新了3代了(https://pjreddie.com/media/files/papers/YOLOv3.pdf)。它之所以可以一步到位,就是使用了如下图的统一架构:
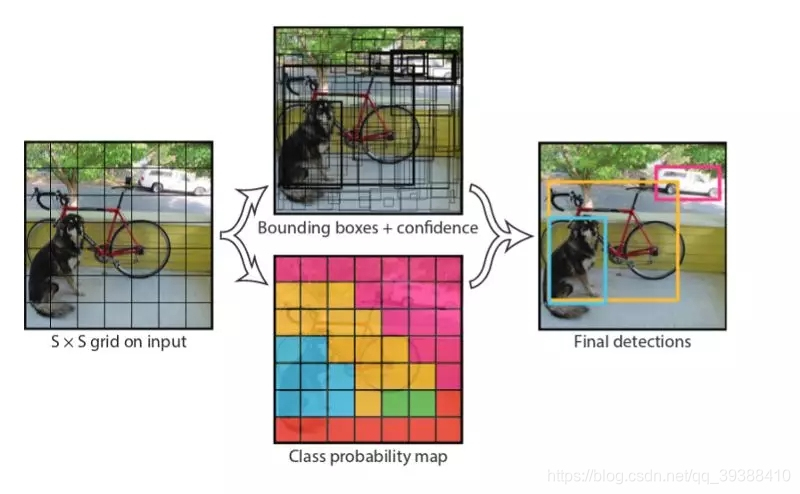
即先把图片分成固定的单元S x S,如图是7 X 7,每个方格都各自负责使用卷积去预测框内有无目标存在的情况,再以小格子为中心寻找更精确的目标框,如图中各种颜色的预测,最后再结合预测到的概率,最大化抑制等就可以得到最后的结果。即它的检测过程是:
1.划分方格,每个方格有(x,y,w,h,confidence,C1…Cn),(x,y)坐标代表了中心,w,h分别代表目标的宽度高度比(相对整张图),置信度是由预测框和任意实际框的iou值,C是预测到的类别,用这样的矩阵格式就可以一次性的预测出类别,边框。因此对于有10个类别的数据来说,每个方格使用2种大小的锚框(一宽一窄),那么每个方格单元的输出将会是((4+1)2+10)=20,那么对于77的方格数,最后有7720大小的的输出。
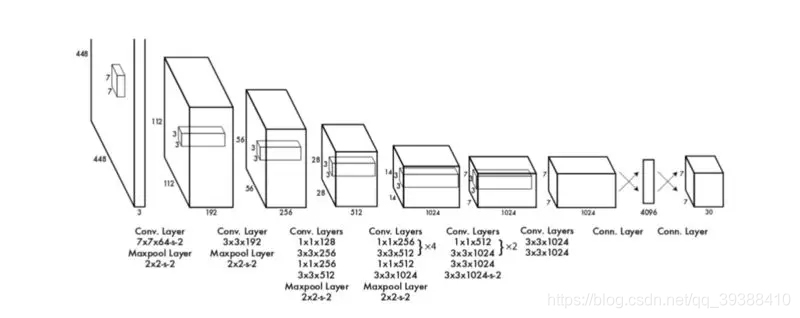
2.输入到网络中进行训练。如下图是YOLO自己所使用了一种叫DarkNet的网络。
损失函数:
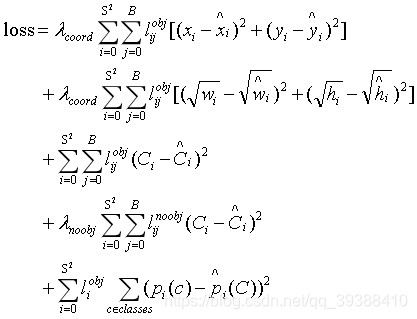
Yolo损失函数一共包括:协调误差,客体性的分数( 1 o b j 1^{obj} 1obj,评价框内是否存在目标,只有它大于0.5时,才有计算协调误差和分类误差),分类误差三项。其中第一项是边界框中心坐标的误差项, 1 o b j 1^{obj} 1obj指的是第i个单元格存在目标,而且该单元格中的第j个边界框负责预测该目标。第二项是边界框的高与宽的W,H误差项。第三项是包含目标的边界框的置信度误差项。第四项是不包含目标的边界框的置信度误差项。而最后一项是包含目标的单元格的分类误差项, 1 o b j 1^{obj} 1obj指的是第i个单元格存在目标。但是实际上这个误差函数并不是对所以的数据集都适用,在其他的数据上它的效果可能并没有那么的出色。
YOLO的全项目地址是:https://pjreddie.com/darknet/ ,下面是部分代码解析:
#YOLO网络模型
from keras.models import Model
from keras.layers import Input, Conv2D, GlobalAveragePooling2D, Dense
from keras.layers import add, Activation, BatchNormalization
from keras.layers.advanced_activations import LeakyReLU
from keras.regularizers import l2
#每个卷积层
def conv2d_unit(x, filters, kernels, strides=1):
x = Conv2D(filters, kernels,
padding='same',
strides=strides,
activation='linear',
kernel_regularizer=l2(5e-4))(x)
x = BatchNormalization()(x)#BN处理
x = LeakyReLU(alpha=0.1)(x)#使用LeakyReLU做激活函数
return x
#每个残差块
def residual_block(inputs, filters):
x = conv2d_unit(inputs, filters, (1, 1))
x = conv2d_unit(x, 2 * filters, (3, 3))
x = add([inputs, x])
x = Activation('linear')(x)
return x
#一堆残差块
def stack_residual_block(inputs, filters, n):
x = residual_block(inputs, filters)
for i in range(n - 1):
x = residual_block(x, filters)
return x
#darknet架构
def darknet_base(inputs):
x = conv2d_unit(inputs, 32, (3, 3))
x = conv2d_unit(x, 64, (3, 3), strides=2)
x = stack_residual_block(x, 32, n=1)
x = conv2d_unit(x, 128, (3, 3), strides=2)
x = stack_residual_block(x, 64, n=2)
x = conv2d_unit(x, 256, (3, 3), strides=2)
x = stack_residual_block(x, 128, n=8)
x = conv2d_unit(x, 512, (3, 3), strides=2)
x = stack_residual_block(x, 256, n=8)
x = conv2d_unit(x, 1024, (3, 3), strides=2)
x = stack_residual_block(x, 512, n=4)
return x
def darknet():
inputs = Input(shape=(416, 416, 3))
x = darknet_base(inputs)
x = GlobalAveragePooling2D()(x)#全局平均池化以处理size不一致(改进SPP的池化方法)
x = Dense(1000, activation='softmax')(x)
model = Model(inputs, x)
return model
if __name__ == '__main__':
model = darknet()
print(model.summary())
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









