







SSD RetinaNet EfficientDet

1.SSD(2016)


创新:
- 多尺度检测:SSD的一个主要贡献是在不同的输出层上使用不同比例的默认框
- 采用预设边界框,我们习惯称它为anchor(在SSD论文中叫default bounding boxes),预测框的尺寸在anchor的指导下进行微调。默认框具有不同的尺度和纵横比,并在每个特征图位置进行预测。这允许模型高效地离散化可能的输出框形状的空间。
- 数据增强,水平翻转,色域扭曲。
- 使用小卷积核进行预测。SSD使用3x3的小卷积核直接预测每个默认框的类别得分和边界框偏移量,而不是像YOLO那样使用全连接层。这使得训练和推理更快
网络结构:
- 过程:SSD方法输入尺寸为300 × 300,基于前馈卷积网络,特征提取部分采用VGG16,在基础网络的末端添加了几个特征层,其产生固定大小的边界框集合和不同尺度和纵横比的默认框的偏移量及其相关置信度,随后是非最大抑制步骤以产生最终检测。
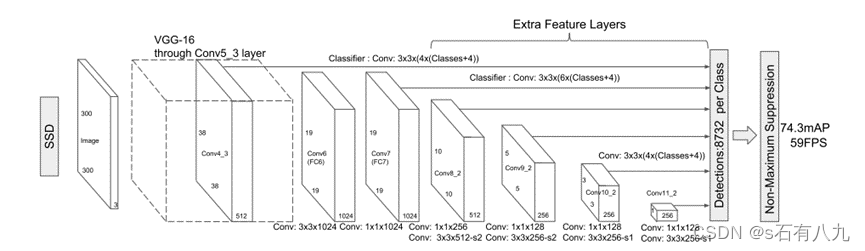
- 在网络的末尾,也就是检测head部分,利用6个特征层进行预测。具体地,将6个特征层分别进行3*3卷积,通道数根据特征层顺序、anchor数、类别数进行变换。
损失函数包括两部分的加权:
1.位置损失函数Smooth L1 2.置信度损失函数softmax
优点:
- 精度高,速度快,优于Faster R-CNN和YOLO
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









