







读书笔记–《强化学习在阿里的技术演进与业务创新》
强化学习 :强化学习和其他学习⽅法不同之处在于强化学习是智能系统从环境到⾏为映射的学习,以使奖励信号函数值最⼤。如果智能体(agent)的某个⾏为策略(action)导致环境正的奖赏(reward),那么智能体以后产⽣这个⾏为策略的趋势便会加强。强化学习是最接近于⾃然界动物学习的本质的⼀种学习范式。
主要瓶颈:对于规模⼤⼀点的问题就会出现维数爆炸,难于计算。
阿里应用场景:在阿⾥移动电商平台中,⼈机交互的便捷,碎⽚化使⽤的普遍性,页⾯切换的串⾏化,⽤户轨迹的可跟踪性等都要求系统能够对变幻莫测的⽤户⾏为以及瞬息万变的外部环境进⾏完整地建模。
模型选择
在模型选择的问题上,主要有多种不同的算法:
- 基于值函数的 Q-Learning、DQN 等,这些⽅法适⽤于离散动作空间,不适合类似 action 为 rank feature 的权重值,是⼀个连续变化的量,⽽且 DQN 算法在实际训练时也有收敛慢的缺点;
- 经典的 Policy Gradient 算法虽然适⽤于连续动作输出的场景,但缺点是训练的过程太慢,因为算法必须在每⼀轮 Episode 结束后才能进⾏梯度的估计和策略的更新;
- Actor-Critic 算法通过引⼊ critic ⽹络对每⼀步的 action 进⾏评价解决了必须在 Episode 结束后才能更新策略的问题,算法可以通过 step by step 的⽅式进⾏更新,但该算法的缺点是由于使⽤连续的样本更新模型,样本之间的相关性强⽽影响模型的收敛性;
- Google DeepMind 团队把在 DQN 训练中取得成功的 Experience Replay 机制和 TargetNetwork 两个组件引⼊了 Actor-Critic 算法,极⼤的提⾼了模型训练的稳定性和收敛性,在很多复杂的连续动作控制任务上取得了⾮常好的效果。
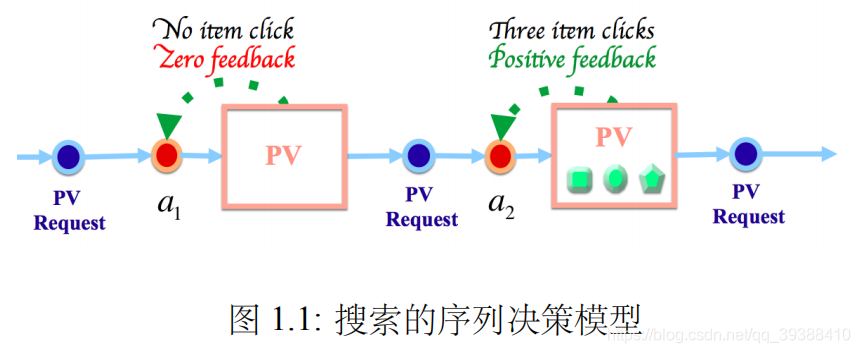
1.场景一.商品的搜索问题可以被视为典型的顺序决策问题
选择强化学习的理由:
前向视⾓(Forward View)来看:⽤户在每个 PV 中的上下⽂状态与之前所有 PV 中的上下⽂状态和 Agent 的⾏为有着必然因果关系,同⼀个 PV 中 Agent采取的不同排序策略将使得搜索过程朝不同的⽅向演进;
反过来,以后向视⾓(Backward View)来看:在遇到相同的上下⽂状态时,Agent 就可以根据历史演进的结果对排序策略进⾏调整,将⽤户引导到更有利于成交的 PV 中去。
顺序决策问题逻辑:
- (1) ⽤户每次请求 PV 时,Agent 做出相应的排序决策,将商品展⽰给⽤户;
- (2) ⽤户根据 Agent 的排序结果,给出点击、翻页等反馈信号;
- (3) Agent 接收反馈信号,在新的 PV 请求时做出新的排序决策;
- (4) 这样的过程将⼀直持续下去,直到⽤户购买商品或者退出搜索。
故原先强化学习的定义需要修改为:
- 状态: s = ( p r i c e 1 , c v r 1 , s a l e 1 , . . . , p r i c e n , c v r n , s a l e n , p o w e r , i t e m , s h o p ) s=(price_1,cvr_1,sale_1,...,price_n,cvr_n,sale_n,power,item,shop) s=(price1,cvr1,sale1,...,pricen,cvrn,salen,power,item,shop),即 (n个历史商品特征) + (购买力、偏好宝贝、偏好店铺)
- 动作:排序向量 μ = ( μ 1 , μ 2 , . . . , μ m ) \mu=(\mu_1,\mu_2,...,\mu_m) μ=(μ1,μ2,...,μm),排序次序是由其特征分数和排序权重向量 µ 的内积所决定的
- 奖励:
-
- (1) 在⼀个 PV 中如果仅发⽣商品点击,则相应的奖赏值为⽤户点击的商品的数量;
-
- (2) 在⼀个 PV 中如果发⽣商品购买,则相应奖赏值为被购买商品的价格;
-
- (3) 其他情况下,奖赏值为 0。
但是在⼤规模动作空间问题中,线性形式的 Q 函数较难在整个值函数空间范围中精确地估计每⼀个状态动作对的值。⼀个优化的办法是引⼊优势函数(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









