







前言
上期文章:「05」回归的诱惑:一文读懂线性回归 中 , 我们介绍了线性回归的原理,组成和优缺点,并探讨了回归的本质含义。在这一期,我们将从回归开始,引出一个机器学习中最重要的任务——分类。
还记得我们上一节的课后题吗?其实答案很简单,任意一条线都可以把任意的数据点分为不同的类,也就是有无数个直线方程存在,这种解并没有意义。这就引出了我们的主题——分类。对于分类问题来说,不同的数据必须分为不同的类别,这个类别,在机器学习中也叫作标签(label)。只有知道了类别,才可以真正进行分类学习,这叫做监督学习。
因此,线性回归的使用场景是回归,而我们这一期的主题——逻辑回归则是用于分类。关于分类和回归,该如何理解它们的区别和联系呢?往下看。

什么是回归?
分类和回归是两个相关联的概念,我们在上一篇文章讲过,以前的一位生物学家高尔顿在研究父母和孩子身高的遗传关系时,发现了一个直线方程,通过这个方程,他几乎准确地拟合了被调查父母的平均身高 x 和 子女平均身高 y 之前的关系:
这个方程是什么意思呢?它代表父母身高每增加1个单位, 其成年子女的平均身高只增加0.516个单位,反映了一种“衰退”效应(“回归”到正常人平均身高)。虽然之后的x与 y变量之间并不总是具有“衰退”(回归)关系,但是为了纪念高尔顿这位伟大的统计学家,“回归”这一名称就保留了下来。
我们可以把回归理解为关系的找寻:回归分析是通过规定因变量和自变量来确定变量之间的因果关系,建立回归模型,并根据实测数据来求解模型的各个参数,然后评价回归模型是否能够很好的拟合实测数据,如果能够很好的拟合,则可以根据自变量作进一步预测,比如我们提到的广告费用与产品销售额的关系。
什么是分类?
所谓分类,简单来说,就是根据文本的特征或属性,划分到已有的类别中。从功能上看,分类问题就是预测数据所属的类别,比如垃圾邮件检测、客户流失预测、情感分析、犬种检测等。分类算法的基本功能是做预测。我们已知某个实体的具体特征,然后想判断这个实体具体属于哪一类,或者根据一些已知条件来估计感兴趣的参数。比如:我们已知某个人存款金额是10000元,这个人没有结婚,并且有一辆车,没有固定住房,然后我们估计判断这个人是否会涉嫌信用欺诈问题。这就是最典型的分类问题,预测的结果为离散值,当预测结果为连续值时,分类算法就退化为之前所说的的回归模型。
二分类
我们先来看看什么是二分类:
给定不同种类数据点,二分类就是找到一条线,使得不同的数据点位于这条线的两侧。一般来说,只存在一条唯一的直线方程,也就是y = f(x),让分类点之间的误差距离最小,比较直观的解法就是SVM,以后会谈到。这里我们用下面这张图举个例子:
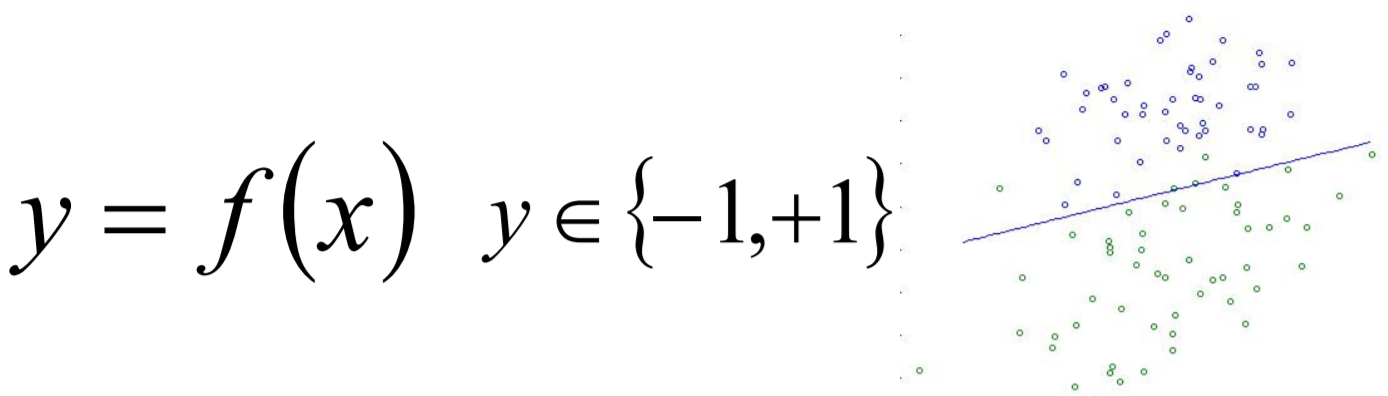
可以看到,图中的2类数据分别是蓝点和绿点。已经知道了这条直线方程,那如何把新出现的数据点根据数据类别的不同划分成不同的类?只需要判断它是在直线的上面(紫色点)还是下面(绿色点)就行了。
多分类
那么,如果存在两种以上的数据且混合分布在一起,要怎么划分呢?一条直线显然已经无法划分了,需要多个直线/平面,甚至是曲线进行划分,这个时候的参数方程就不是直线方程了,而是更复杂的多次项方程。不过我们也可以用很多条直线来近似的拟合这种曲线。这里也涉及到机器学习的灵魂拷问:过拟合,在后面的一期文章,我们会单独聊聊它,这里先按下不表。
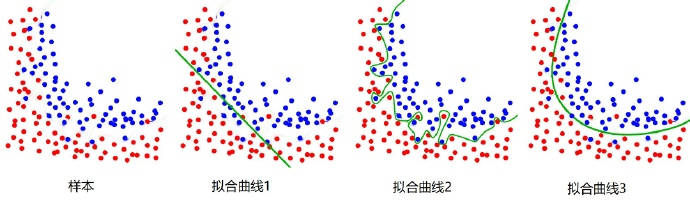
所以,多分类问题其实可以看成二分类的扩展版,同样待预测的label标签只有一个,但是label标签的取值可能有多种情况;直白来讲就是每个实例的可能类别有K种(t1 ,t2 ,...tk ,k≥3):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











