







1 Neural Networks and Deep Learning 吴恩达-Coursera课程
Week - 1
Quiz
1.What does the analogy “AI is the new electricity” refer to?
Similar to electricity starting about 100 years ago, AI is transforming multiple industries.
2.Which of these are reasons for Deep Learning recently taking off? (Check the three options that apply.)
We have access to a lot more computational power
Deep learning has resulted in significant improvements in important applications such as online advertising, speech recognition, and image recognition.
We have access to a lot more data
3.Recall this diagram of iterating over different ML ideas. Which of the statements below are true? (Check all that apply.)
Being able to try out ideas quickly allows deep learning engineers to iterate more quickly.
Faster computation can help speed up how long a team takes to iterate to a good idea.
Recent progress in deep learning algorithms has allowed us to train good models faster (even without changing the CPU/GPU hardware).
4.When an experienced deep learning engineer works on a new problem, they can usually use insight from previous problems to train a good model on the first try, without needing to iterate multiple times through different models. True/False?
False
解释:No. Finding the characteristics of a model is key to have good performance. Although experience can help, it requires multiple iterations to build a good model.
5.Which one of these plots represents a ReLU activation function?
看图,z轴负半轴a轴值保持0,正半轴是线性增加
6.Images for cat recognition is an example of “structured” data, because it is represented as a structured array in a computer. True/False?
False
7.A demographic dataset with statistics on different cities’ population, GDP per capita, economic growth is an example of “unstructured” data because it contains data coming from different sources. True/False?
False
8.Why is an RNN (Recurrent Neural Network) used for machine translation, say translating English to French? (Check all that apply.)
It can be trained as a supervised learning problem.
It is applicable when the input/output is a sequence (e.g., a sequence of words)
9.In this diagram which we hand-drew in lecture, what do the horizontal axis (x-axis) and vertical axis (y-axis) represent?
·x-axis is the amount of data.
·y-axis (vertical axis) is the performance of the algorithm.
10.Assuming the trends described in the previous question’s figure are accurate (and hoping you got the axis labels right), which of the following are true? (Check all that apply.)
Increasing the training set size generally does not hurt an algorithm’s performance, and it may help significantly.
Increasing the size of a neural network generally does not hurt an algorithm’s performance, and it may help significantly.
Week - 2
Quiz
1.What does a neuron compute?
A neuron computes a linear function followed by an activation function
2.Which of these is the “Logistic Loss”?
L
i
(
y
^
i
,
y
i
)
=
−
(
y
i
l
o
g
(
y
^
i
)
+
(
1
−
y
i
)
l
o
g
(
1
−
y
^
i
)
)
L^i(\hat y^i ,y^i)=-(y_ilog(\hat y^i)+(1-y^i)log(1-\hat y^i))
Li(y^i,yi)=−(yilog(y^i)+(1−yi)log(1−y^i))
3.Suppose img is a (32,32,3) array, representing a 32x32 image with 3 color channels red, green and blue. How do you reshape this into a column vector?
x
=
i
m
g
.
r
e
s
h
a
p
e
(
(
32
∗
32
∗
3
,
1
)
)
x=img.reshape((32*32*3,1))
x=img.reshape((32∗32∗3,1))
4.Consider the two following random arrays “a” and “b”:
a = np.random.randn(2, 3) # a.shape = (2, 3)
b = np.random.randn(2, 1) # b.shape = (2, 1)
c = a + b
What will be the shape of “c”?
c.shape=(2,3)
5.Consider the two following random arrays “a” and “b”:
a = np.random.randn(4, 3) # a.shape = (4, 3)
b = np.random.randn(3, 2) # b.shape = (3, 2)
c = a*b
What will be the shape of “c”?
The computation cannot happen because the sizes don’t match. It’s going to be “Error”!
6.Suppose you have
n
x
n_x
nx input features per example. Recall that
X
=
[
x
(
1
)
x
(
2
)
.
.
.
x
(
m
)
]
X=[x^{(1)}x^{(2)}...x^{(m)}]
X=[x(1)x(2)...x(m)]. What is the dimension of X?
(
n
x
,
m
)
(n_x,m)
(nx,m)
7.Recall that “np.dot(a,b)” performs a matrix multiplication on a and b, whereas “a*b” performs an element-wise multiplication.
Consider the two following random arrays “a” and “b”:
a = np.random.randn(12288, 150) # a.shape = (12288, 150)
b = np.random.randn(150, 45) # b.shape = (150, 45)
c = np.dot(a,b)
What is the shape of c?
c.shape=(12288,45)
8.Consider the following code snippet:
# a.shape = (3,4)
# b.shape = (4,1)
for i in range(3):
for j in range(4):
c[i][j] = a[i][j] + b[j]
How do you vectorize this?
c = a + b.T
9.Consider the following code:
a = np.random.randn(3, 3)
b = np.random.randn(3, 1)
c = a*b
What will be c? (If you’re not sure, feel free to run this in python to find out).
This will invoke broadcasting, so b is copied three times to become (3,3), and *∗ is an element-wise product so c.shape will be (3, 3)
10.Consider the following computation graph.
What is the output J?
J
=
(
a
−
1
)
∗
(
b
+
c
)
J=(a-1)*(b+c)
J=(a−1)∗(b+c)
Logistic_Regression_with_a_Neural_Network_mindset_v6a
编程方面只放自己一开始写错的,卡住的地方吧
首先是 4.3 - Forward and Backward propagation
Now that your parameters are initialized, you can do the “forward” and “backward” propagation steps for learning the parameters.
Exercise: Implement a function propagate() that computes the cost function and its gradient.
Hints:
Forward Propagation:
- You get X
- You compute A = σ ( w T X + b ) = ( a ( 1 ) , a ( 2 ) , . . . , a ( m − 1 ) , a ( m ) ) A = \sigma(w^T X + b) = (a^{(1)}, a^{(2)}, ..., a^{(m-1)}, a^{(m)}) A=σ(wTX+b)=(a(1),a(2),...,a(m−1),a(m))
- You calculate the cost function: J = − 1 m ∑ i = 1 m y ( i ) log ( a ( i ) ) + ( 1 − y ( i ) ) log ( 1 − a ( i ) ) J = -\frac{1}{m}\sum_{i=1}^{m}y^{(i)}\log(a^{(i)})+(1-y^{(i)})\log(1-a^{(i)}) J=−m1∑i=1my(i)log(a(i))+(1−y(i))log(1−a(i))
Here are the two formulas you will be using:
∂
J
∂
w
=
1
m
X
(
A
−
Y
)
T
(7)
\frac{\partial J}{\partial w} = \frac{1}{m}X(A-Y)^T\tag{7}
∂w∂J=m1X(A−Y)T(7)
∂
J
∂
b
=
1
m
∑
i
=
1
m
(
a
(
i
)
−
y
(
i
)
)
(8)
\frac{\partial J}{\partial b} = \frac{1}{m} \sum_{i=1}^m (a^{(i)}-y^{(i)})\tag{8}
∂b∂J=m1i=1∑m(a(i)−y(i))(8)
请注意这里的计算都是矩阵的乘积,也就是说都是np.dot系列
### START CODE HERE ### (≈ 2 lines of code)
A = sigmoid(np.dot(w.T,X)+b) # compute activation
#print(A.shape)
cost = -np.sum(Y*np.log(A)+(1-Y)*np.log(1-A))/m # compute cost
### END CODE HERE ###
# BACKWARD PROPAGATION (TO FIND GRAD)
### START CODE HERE ### (≈ 2 lines of code)
dw = np.dot(X,(A-Y).T)/m
db = np.sum(A-Y)/m
### END CODE HERE ###
后面其实有个地方是有问题的
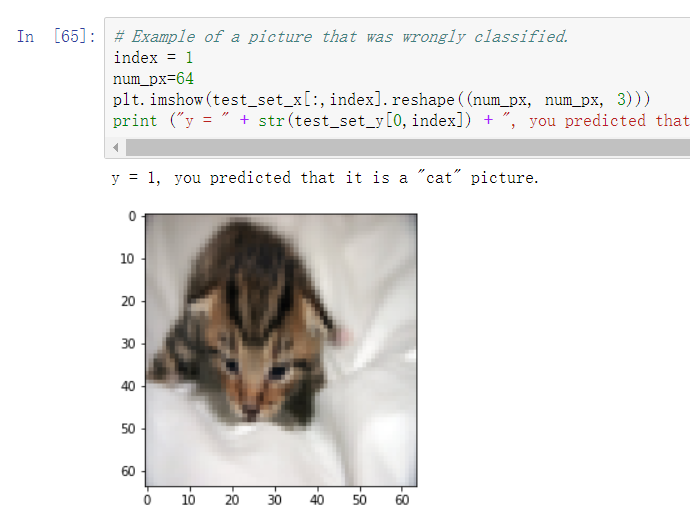
也就是这行代码,直接运行会出现
# Example of a picture that was wrongly classified.
index = 1
plt.imshow(test_set_x[:,index].reshape((num_px, num_px, 3)))
print ("y = " + str(test_set_y[0,index]) + ", you predicted that it is a \"" + classes[d["Y_prediction_test"][0,index]].decode("utf-8") + "\" picture.")
这样子的错误,然后这是为什么呢?
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-61-c6c0e9212ea5> in <module>()
1 # Example of a picture that was wrongly classified.
2 index = 1
----> 3 plt.imshow(test_set_x[:,index].reshape((num_px, num_px, 3)))
4 print ("y = " + str(test_set_y[0,index]) + ", you predicted that it is a \"" + classes[d["Y_prediction_test"][0,index]].decode("utf-8") + "\" picture.")
ValueError: total size of new array must be unchanged
根据错误提示,我们检查一下数据的大小,print(test_set_x.shape)可以得到(12288,50)着这是,num_px是24,那么24x24x3不等于12288,所以没有办法reshape,那怎么办呢?
只需要12288/3,开根,得到64。
直接在前面加一个:,这样我们就能成功运行该行代码了
num_px=64
如下图所示:
Week - 3
Quiz
1.Which of the following are true? (Check all that apply.)
a
[
2
]
(
12
)
a^{[2](12)}
a[2](12) denotes the activation vector of the
2
n
d
2^{nd}
2nd layer for the
1
2
t
h
12^{th}
12th trainingn example.
a
[
2
]
a^{[2]}
a[2] denotes the activation vector of the
2
n
d
2^{nd}
2nd layer.
X
X
X is a matrix in which each column is one training example.
a
4
[
2
]
a^{[2]}_4
a4[2] is the activation output by the
4
t
h
4^{th}
4th neuron of the
2
n
d
2^{nd}
2nd layer.
2.The tanh activation usually works better than sigmoid activation function for hidden units because the mean of its output is closer to zero, and so it centers the data better for the next layer. True/False?
True
3.Which of these is a correct vectorized implementation of forward propagation for layer
l
l
l, where
1
≤
l
≤
L
1 \leq l \leq L
1≤l≤L?
Z
[
l
]
=
W
[
l
]
A
[
l
−
1
]
+
b
[
l
]
Z^{[l]}=W^{[l]}A^{[l-1]}+b^{[l]}
Z[l]=W[l]A[l−1]+b[l]
A
[
l
]
=
g
[
l
]
(
Z
[
l
]
)
A^{[l]}=g^{[l]}(Z^{[l]})
A[l]=g[l](Z[l])
4.You are building a binary classifier for recognizing cucumbers (y=1) vs. watermelons (y=0). Which one of these activation functions would you recommend using for the output layer?
sigmoid
5.Consider the following code:
A = np.random.randn(4,3)
B = np.sum(A, axis = 1, keepdims = True)
What will be B.shape? (If you’re not sure, feel free to run this in python to find out).
(4,1)
6.Suppose you have built a neural network. You decide to initialize the weights and biases to be zero. Which of the following statements is true?
Each neuron in the first hidden layer will perform the same computation. So even after multiple iterations of gradient descent each neuron in the layer will be computing the same thing as other neurons.
7.Logistic regression’s weights w should be initialized randomly rather than to all zeros, because if you initialize to all zeros, then logistic regression will fail to learn a useful decision boundary because it will fail to “break symmetry”, True/False?
False
8.You have built a network using the tanh activation for all the hidden units. You initialize the weights to relative large values, using np.random.randn(…,…)*1000. What will happen?
This will cause the inputs of the tanh to also be very large, thus causing gradients to be close to zero. The optimization algorithm will thus become slow.
9.Consider the following 1 hidden layer neural network:
Which of the following statements are True? (Check all that apply).
W
[
1
]
W^{[1]}
W[1] will have shape (4,2)
b
[
1
]
b^{[1]}
b[1] will have shape (4,1)
W
[
2
]
W^{[2]}
W[2] will have shape (1,4)
b
[
2
]
b^{[2]}
b[2] will have shape (1,1)
10.In the same network as the previous question, what are the dimensions of
Z
[
1
]
Z^{[1]}
Z[1] and
A
[
1
]
A^{[1]}
A[1]?
Z
[
1
]
Z^{[1]}
Z[1] and
A
[
1
]
A^{[1]}
A[1] are (4,m)
Week - 4
Quiz
1.What is the “cache” used for in our implementation of forward propagation and backward propagation?
We use it to pass variables computed during forward propagation to the corresponding backward propagation step. It contains useful values for backward propagation to compute derivatives.
2.Among the following, which ones are “hyperparameters”? (Check all that apply.)
learning rate
α
\alpha
α
number of iterations
size of the hidden layers
n
[
l
]
n^{[l]}
n[l]
number of layers
L
L
L in the neural network
3.Which of the following statements is true?
The deeper layers of a neural network are typically computing more complex features of the input than the earlier layers.
4.Vectorization allows you to compute forward propagation in an
L
L
L-layer neural network without an explicit for-loop (or any other explicit iterative loop) over the layers l=1, 2, …,L. True/False?
False
5.Assume we store the values for n [ l ] n^{[l]} n[l] in an array called layers, as follows: layer_dims = [ n x n_x nx, 4,3,2,1]. So layer 1 has four hidden units, layer 2 has 3 hidden units and so on. Which of the following for-loops will allow you to initialize the parameters for the model?
for(i in range(1, len(layer_dims))):
parameter[‘W’ + str(i)] = np.random.randn(layers[i], layers[i-1])) * 0.01
parameter[‘b’ + str(i)] = np.random.randn(layers[i], 1) * 0.01
6.Consider the following neural network.
How many layers does this network have?
The number of layers L is 4. The number of hidden layers is 3.
7.During forward propagation, in the forward function for a layer
l
l
l you need to know what is the activation function in a layer (Sigmoid, tanh, ReLU, etc.). During backpropagation, the corresponding backward function also needs to know what is the activation function for layer
l
l
l, since the gradient depends on it. True/False?
True
8.There are certain functions with the following properties:
(i) To compute the function using a shallow network circuit, you will need a large network (where we measure size by the number of logic gates in the network), but (ii) To compute it using a deep network circuit, you need only an exponentially smaller network. True/False?
True
9.Consider the following 2 hidden layer neural network:
Which of the following statements are True? (Check all that apply).
W
1
W^{1}
W1 has shape
(
4
,
4
)
(4,4)
(4,4)
b
1
b^{1}
b1 has shape
(
4
,
1
)
(4,1)
(4,1)
W
2
W^{2}
W2 has shape
(
3
,
4
)
(3,4)
(3,4)
b
2
b^{2}
b2 has shape
(
3
,
1
)
(3,1)
(3,1)
W
3
W^{3}
W3 has shape
(
1
,
3
)
(1,3)
(1,3)
b
3
b^{3}
b3 has shape
(
1
,
1
)
(1,1)
(1,1)
10.Whereas the previous question used a specific network, in the general case what is the dimension of
W
[
l
]
W^{[l]}
W[l], the weight matrix associated with layer
l
l
l?
W
[
l
]
W^{[l]}
W[l] has shape
(
n
[
l
]
,
n
[
l
−
1
]
)
(n^{[l]},n^{[l-1]})
(n[l],n[l−1])















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











