







本章要回答的问题:
- 云原生网络操作系统的主要需求是什么?
- 什么是 OpenFlow 和软件定义网络? 它们适用什么样的场景?
- 网络解耦中网络操作系统有哪些可能的选择?
- 这些模型与云原生 NOS 的需求相比是怎样的?
网络设备的新需求
云原生时代中网络设备需要满足以下要求:
- 设备具有可编程性
- 提供运行第三方应用程序的能力
- 提供使用同等功能的组件替换供应商提供的组件的能力
- 提供运营人员修复代码错误的能力
换句话说,网络设备不再是长期以来的嵌入式设备或专用设备,而应更像是一个服务器平台。
软件定义网络和Openflow的兴起
how to perform useful research with a vertically integrated switch made up of proprietary switching silicon and a NOS that was not designed to be a platform?
Openflow论文
-
使用大多数数据转发芯片上可用的流表(flow tables)用于决定数据包的处理。研究人员通过流表能够指定新的数据包转发行为。
-
对流表进行分片,运营人员就可以在相同的设备上运行生产和研究数据。这将使研究人员能够在真实网络上测试新的想法,而不会扰乱生产流量。
-
定义一个新协议,允许远程运行的软件对流表进行编程并交换不同信息。这将允许研究人员远程编程流表,无需在交换机本身上运行软件,从而避开了最新的交换机网络操作系统的非平台模型。
thereby sidestepping the nonplatform model of the then-current switch network operating systems.
流表(在大多数交换机文献中通常称为访问控制列表)是在其查找键中至少使用以下字段的查找表(lookup tables):
源和目的IP地址、四层协议类型(传输控制协议 [TCP]、用户数据报协议 [UDP] 等)以及四层源端口和目标端口(TCP/UDP 端口)。
查找的结果可能是以下操作之一:
- 将数据包转发到不同的目的地址,替代IP路由或桥接提供的目的地址
- 丢弃数据包
- 执行其他操作,例如计数、网络地址转换 (NAT, Network Address Translation)等
远程对流表控制的节点称为控制器(controller)。控制器上运行的软件决定了如何对流表进行编程,实现了对Openflow节点的编程。
例如,控制器可以运行传统的路由协议,并将流表设置为仅使用数据包中的目标 IP 地址,从而使单个 OpenFlow 节点像传统路由器一样运行。但是,由于路由协议不是一个分布式应用程序,即在多个节点上运行的应用程序,每个节点独立决定本地路由表的内容,因此研究人员可以在没有交换机供应商支持的情况下创建新的路径转发算法。此外,研究人员还可以尝试与传统IP路由截然不同的全新数据包转发行为。
决定数据包转发行为的数据平面,与控制数据包转发的流表的控制平面之间的分离,允许研究人员在服务器操作系统中对控制平面进行更改。网络操作系统NOS 将仅管理设备的本地资源。根据控制平面程序发送的协议命令,本地网络设备上的 NOS 将更新流表。
这种集中式控制平面和分布式数据平面的网络模型称为软件定义网络(sofware-defined networking, SDN)
流表是内置在交换芯片硬件上的通用的软件抽象的转发行为。这是一种打破网络特定于供应商的新方法。
SDN 和 OpenFlow 更多详细信息
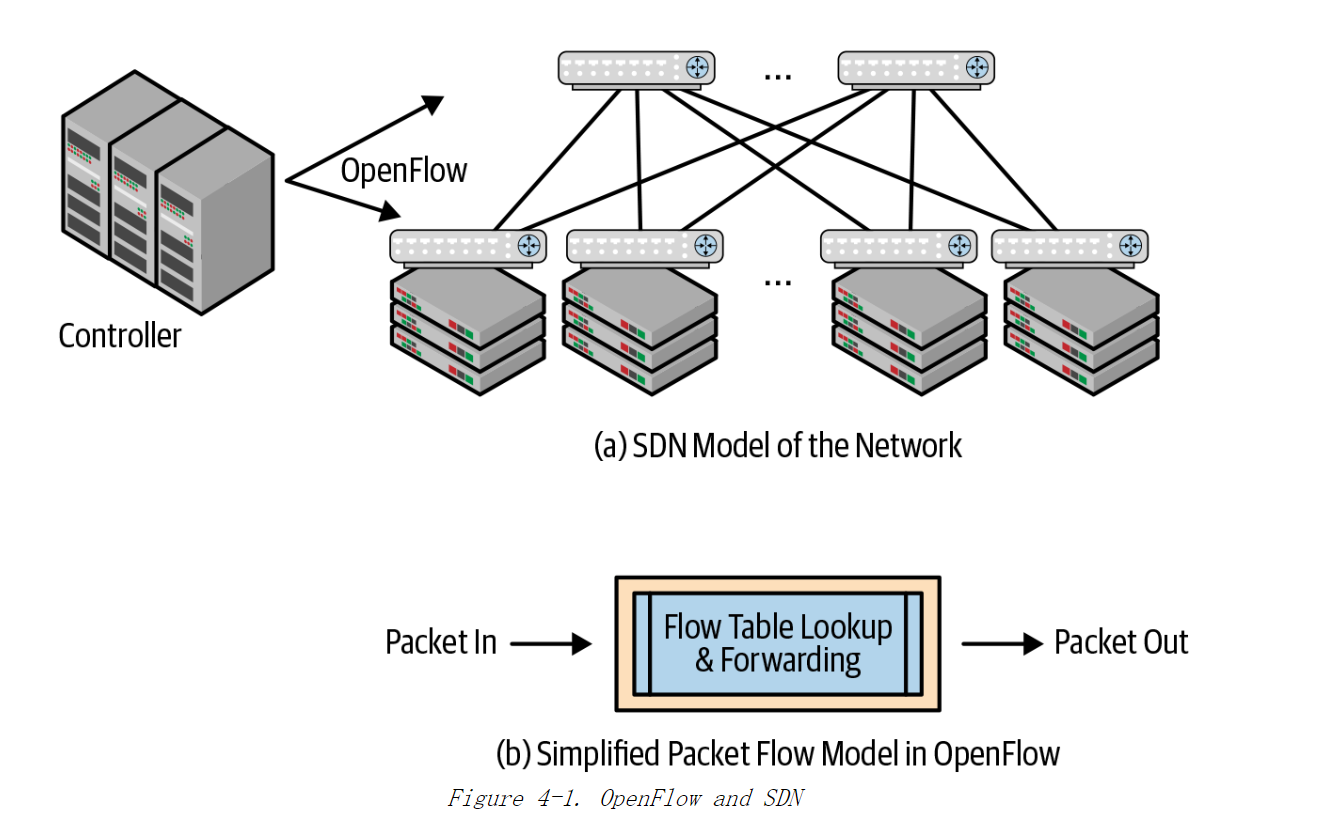
图 4-1 展示使用 SDN 的交换机的两个核心组件。
图(a)展示了Openflow如何管理网络设备,图(b)展示了流表控制数据包转发行为的网络设备
图 4-1(a)展示中央控制平面对网络设备进行配置和监控。网络运营人员通过控制平面可以管理整个网络。
图4-1(b)展示使用 OpenFlow 的交换芯片是相当简单。最初的流表仅包含很少几个字段。为了满足一些需求,OpenFlow 倡导者提出流表的查找键要非常通用:取数据包头部所有字段到特定长度作为查找键,例如:前 40 或 80 个字节。这种方法可以自动支持新的数据包头,例如:新的隧道协议的数据包头部。隧道协议的数据包头部是在原有的数据包头部(IP头部) 之前插人了新的数据包头。因为查找键包含数据包头部所有字节,且保持某个长度,只要编写程序识别这些字节,流表查找就能够处理隧道协议的数据包头部或其他新协议的数据包头部。
与路由表或桥接表相比,内置在传统交换芯片上的流表是非常小的。如果流表非常大,交换芯片的制造费用会非常昂贵。因此,OpenFlow 论文中不建议预填写流表而是将流表当缓存一样使用。如果在流表中没有找到与数据包匹配的转发规则,则会将数据包发送至控制器。中央控制器将参考本地的软件表项来决定数据包的转发行为,并生成转发流表,以便这条数据流后续的数据包不会被上送到中央控制器。
Openflow面临的问题
- OpenFlow 企图一次解决多个问题。用户渴望的可编程性是对设备进行配置和指标统计的构造。为了解决这个问题,OpenFlow 使用了完全不同的抽象,需要重新创造太多的内容。
- 与路由表和桥接表相比,关于流表的芯片实现无法通过低成本的方式进行扩展。数据中心运营操作人员不会关心如下研究问题:TTL 数值为 62 或 12 的数据包与其他数据包不同,是否转发所有这些数据包? 如何结合 IPV4 地址的 32 位与MAC 地址的低 12 位来执行流表查找?
- OpenFlow 抽象模型的定义或过于局限,或过于宽松。OpenFlow 会考虑融合其他模型行为,例如:SNMP,这就最终导致与更多的供应商绑定,而不是期待的更少的绑定。两种不同的 SDN 控制器对 OpenFlow 流表的编程模式会有很大的不同。结果,在选择一个控制器供应商之后,将无法轻松地切换其他供应商。
- 最后,人们意识到 OpenFlow 与传统路由和桥接网络模型是截然不同。与传统模式相比,OpenFlow 成熟度较低。Internet 是世界上最大的网络,尽管仍然存在一些问题,但是目前已经运行良好。虽然无法对交换机进行编程访问,但是分布式路由协议已经工作正常,人们并没有看到使用 OpenFlow 换掉它们的益处。
OVS
开放虚拟交换机 Open Virtual Switch (OVS) 是Linux上备受好评的开源OpenFlow交换机。
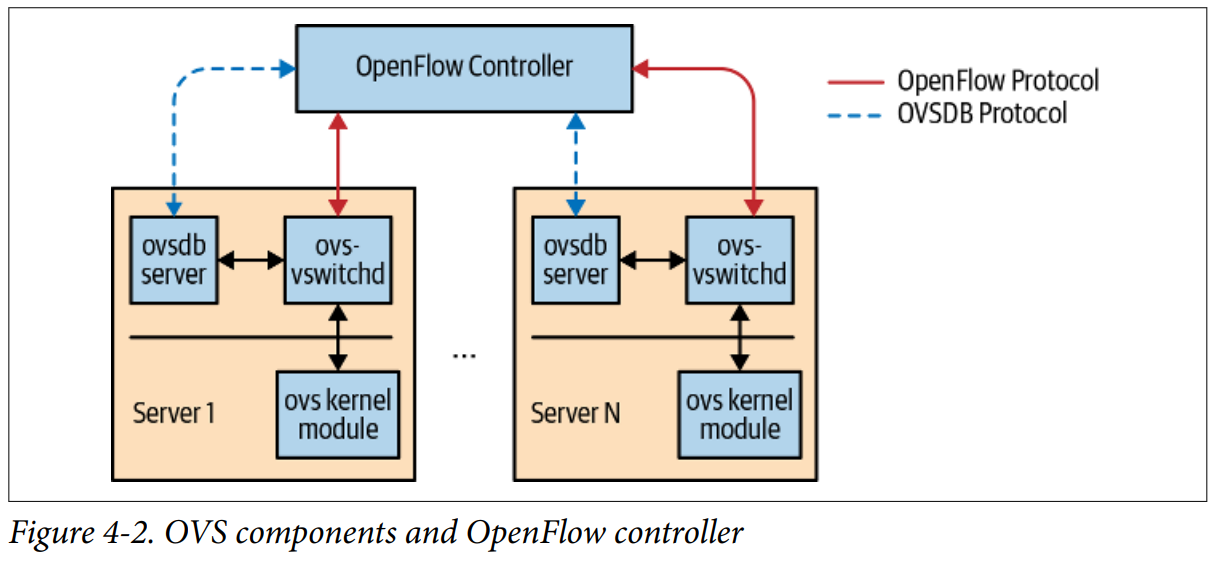
你可以配置 OVS 支持Intel的数据链路开发组件 Data Path Development Kit (DPDK),使其在用户空间内可以执行高速数据包处理。
NOS设计模型
现代网络操作系统的两个共同元素:
-
Linux
Linux 几乎是所有 NOS 的基本操作系统。这里的基本操作系统是指进程管理内存管理以及非网络设备 I/O(主要是存储)的部分。
-
Intel X86/ARM处理器
新网络解耦的 NOS 和传统数据中心交换机都包含以上两种元素。
操作系统充当资源与使用这些资源的程序之间的”中间人“。
每个操作系统都有用户空间和内核空间,主要通过受保护的内存空间来进行区分。
- 内核空间(除设备驱动程序外)的程序可以完全访问所有硬件和软件资源。
- 用户空间每个进程只能访问其自己的私有内存空间,其他任何操作都需要请求内核。
这种分离是通过 CPU自身的保护环或 CPU 的提供域来强制实现的。操作系统还提供了标准的API(Application Programming Interface,应用编程接口),允许应用程序请求使用和释放资源。
无论是网络解耦交换机,还是其他交换机,CPU都会连接数据转发芯片、管理以太网端口、存储等。
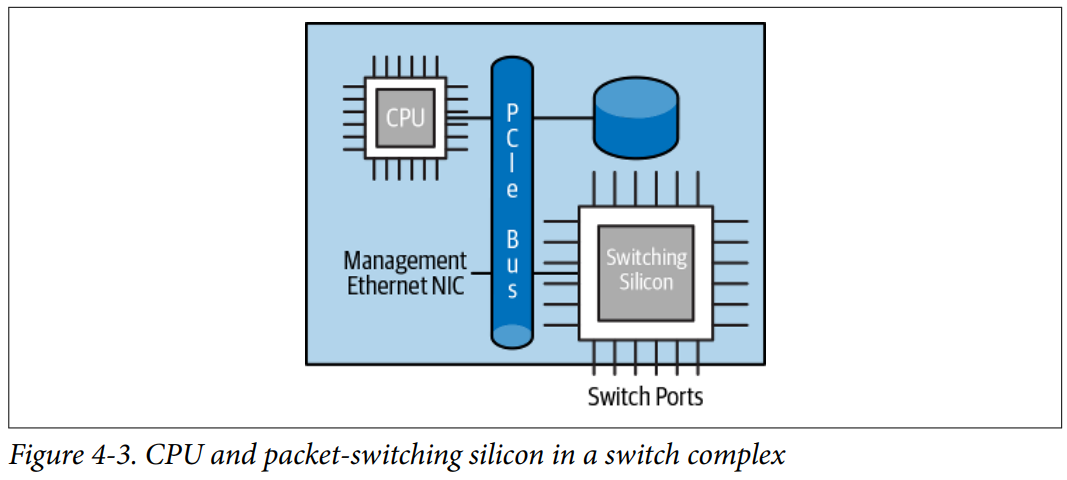
数据转发芯片通过外围输入/输出总线 PCIe(Peripheral Component Interconnect express)连接到CPU。数据转发芯片和CPU之间的互联带宽仅占交换芯片带宽总量的一小部分。
NOS的主要任务是运行控制和管理协议,维护额外状态(例如计数器)、设置数据转发芯片转发数据包。 除了使用OpenFlow之外,交换机的NOS并不在数据包转发路径上。NOS只需要处理少量发送到交换机自身的流量。发往交换机的数据包通常是控制平面数据包(控制平面根据路由协议或桥接协议发送的数据包)。NOS 看到的另一种数据包为包含错误的数据包组成,它必须为其生成错误消息数据包(error message packets)。
因此,交换机上NOS的流量占数据转发芯片支持的总带宽的百分比很小。 例如,NOS 每秒最多可以处理 150,000 个数据包,而交换芯片每秒将处理超过 50 亿个数据包。NOS可以采用策略来对命中流量进行限流,优先转发控制协议的流量。这样确保NOS不会因为发送大量的数据包而无法工作。
交换机网络状态的存储位置
交换机网络状态表示在交换机上与数据包转发相关的所有信息,包括:查找表,访问控制列表ACL及计数器。
主要有三种模型:
特定于供应商的用户空间模型
网络状态被存储在用户空间的NOS供应商特定的软件中。
供应商提供控制协议栈将网络状态直接写入供应商特定的数据存储区。
思科的NX-OS和基于DPDK的网络操作系统都是基于该模型实现的。
混合模型
混合模型是第一个模型的变体。与第一个模型相同,混合模型中网络状态信息的最终来源是供应商特定的用户空间栈。
但是,NOS 也会将此状态的某些部分与内核中的等效状态进行同步。
混合模型中,只是一部分状态与内核同步。例如,有些 NOS 会同步除桥接状态以外的所有状态。有些 NOS 仅同步接口和IP 路由状态,包括 ARP/ND
状态,其余的状态不会与内核进行同步。大多数情况下,供应商还会与内核保证同步更改:内核中相应数据结构发生任何更改,也会同步到供应商用户空间专有栈。
那么为什么这些状态同步,而其他状态不同步呢?
不同 NOS 供应商给出了不同的原因。例如:一些 NOS 供应商将交换芯片作为系统中唯一的数据包转发器。当 CPU 将数据包发送到交换芯片时,芯片就好像从交换芯片端口接收到的数据包一样,可以正常处理此数据包,并在硬件中转发该数据包。 相反方向也是如此。这种情况下,唯一需要同步的状态是保证其工作正常的那些状态。在这种情况下,使用的唯一的数据包转发模型是交换芯片模型。再比如.有些大型网络运营人员仅使用路由功能,在 NOS 上编写自己的应用程序,供应商用户空间的程序在一定程度上会与内核状态同步,主要是为了保留(或获取) 这些大型网络运营人员编写的程序。
上面两种情况下,供应商提供的应用程序 (例如: 控制协议套件) 都是直接从供应商自己在用户空间的程序中更新状态,而不是从内核中更新状态。
完全的内核模型
使用Linux内核的数据结构作为网络状态信息的最终来源。
如今,内核支持与数据中心网络基础设施相关的几乎所有关键结构,例如 IPv4、IPv6、网络虚拟化和逻辑交换机。因为数据包转发行为发生在交换芯片,这种模型需要芯片的计数器和其他状态与内核等效状态进行同步。在此模型中,NOS供应商不会使用任何非标准的Linux API调用执行所需的功能。Cumulus Linux是该模型的主要NOS供应商。
内核模型使用标准的Linux API与任何应用程序一起工作,基于标准的Linux API可以保证内核修改不会影响现存的用户空间应用程序,虽然应用程序可能需要重新编译,但是代码几乎可以保证在未来版本的内核上正常工作。对于混合模型,如果第三方应用程序仅依赖于内核同步(例如IP路由),那么它可以使用标准的Linux API,否则,它必须使用特定于供应商的API。
交换芯片的编程
NOS上有本地网络状态之后,这个状态如何写入交换芯片上呢?
交换芯片是像以太网网卡或磁盘一样的设备,写入交换芯片需要设备驱动。
跟传统设备驱动一样,设备驱动可以在Linux内核中实现,也可以在用户空间实现。
最常见的模型是在用户空间实现驱动。 原因如下:
- 交换供应商只提供用户空间实现的驱动。
- 直到现在 Linux 内核都没有提供数据转发芯片的抽象或模型。内核提供了许多设备的抽象,例如: 块设备、字符设备、网络设备等,但是内核没有提供数据转发芯片的等效抽象。
- 很多人认为在用户空间中编写驱动要比在内核中编写驱动要简单。
用户空间驱动如何获得交换机网络状态信息并写入交换芯片?
如果网络状态存储在用户空间中,用户空间程序会通知驱动将相关信息写入芯片。如果网络状态存储在内核中,用户空间驱动会打开 Netlink 套接字,从内核中获得网络状态更新成功的通知。之后将这些信息写入交换芯片。图 4-4 展示了这两种模型。
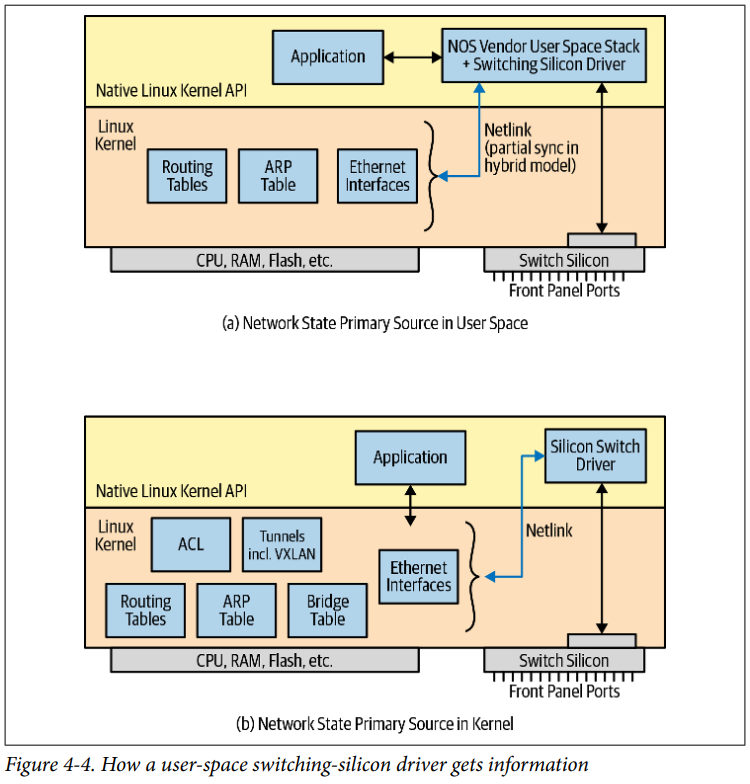
图4-4:显示一个用户空间交换芯片如何获得网络状态信息
Netlink
==用户空间与内核的网络状态进行同步,或将内核的网络状态信息写入交换芯片,这些功能的实现都依赖于 Linux 内核 Netlink 功能。Netlink 提供了可以对内核的网络结构状态进行编程的 API,同时提供发布 - 订阅总线机制。Netlink是 Linux 内核中的一个套接字族:
AF_NETLINK。==用户空间进程可以创建AF_NETLINK套接字,使用套接字 send 方法和 recv 方法与内核中的网络结构进行通信。我们也可以创建多个进程打开AF_NETLINK套接字与内核中的网络结构进行通信。例如:用户空间的路由协议进程向内核路由表添加一条规则,该进程会打开
AF_NETLINK套接字,通过调用内核 API (rt_netlink) 发送带格式的信息如果更新成功,内核会发送路由表更新的 Netlink 消息,通知所有打开Netlink套接字的用户空间进程。该路由协议进程会收到更新通知,同时,还会收到更新成功的通知。用户空间交换芯片驱动也会打开 Netlink 套接字。因此,所有对路由表成功更新的信息也会被用户空间交换芯片驱动接收。之后该驱动会将内核状态写入交换芯片。例如:用户要关闭交换机端口对应的接口,可以使用 Linux 命令:
ip link set down swp1。ip程序属于iproute2模块的命令,它会打开Netlink 套接字,并发送恰当的带格式的信息去要求关闭接口。随后内核关闭相应的接口。同时内核也会发送接口关闭的消息给所有打开 Netlink 套接字的用户空间进程。用户空间交换芯片驱动收到接口关闭的通知后,它会发送适当的命今要求交换芯片关闭芯片上对应的端口。同样,在NOS 的混合模型中,供应商应用程序也会跟内核内部路由表和其他表进行同步。不同进程引起内核表的更改也会同步到程序内部状态中。
Netlink 套接宇提供不同消息类型,允许用户空间进程订阅内核指定的事件。例如: 用户空间进程可以打开 Netlink 套接字,订阅接口状态更改的事件。在这种情景下,内核不会向 Netlink 套接字发送其他类型(如路由表) 更改成功的信息。ifplugd 是一个流行的用户空间的 Linux 工具,用于监视接口状态更改,它的工作原理就是这样的。
==Linux内核的网络状态的可编程性和可通知性都是通过 Netlink 实现的。==Netlink 也是可扩展的。它支持用户自定义消息类型,即用户空间组件和新的内核组件之间的通信可以使用用户自定义消息类型。当用户空间进程没有及时通过 Netlink 套接字发出通知数据包,就会导致这些数据包在内核中被丢弃。如果用户空间进程想要重新同步内核状态,它必须重新打开 Netlink 套接字。为了避免此情景,建议将 Netlink 套接字的缓存大小设置为较大值。
我们不能在远程主机上打开一个 Netlink 套接字。然而,用户可以编写简单的应用程序,作为远程客户端和本地 Netlink 套接字之间的代理程序。
交换机抽象接口
因为交换机芯片驱动是用户空间程序,大多数 NOS 供应商定义了自己的 HAL(Hardware Abstraction Layer,硬件抽象层)和使用芯片供应商驱动的专有芯片部分。通过将逻辑操作映射为专有芯片代码,可以支持多种交换芯片类型。HAL 定义特定于每个 NOS 供应商。
微软和戴尔为数据转发芯片定义了通用的、独立于 NOS 的HAL,称为 SAI (Switch Abstraction Interface,交换机抽象接口)。微软要求在微软 Azure 数据中心的所有交换芯片都支持 SAI,因此许多芯片供应商都宣称支持 SAI,提供特定于交换芯片的映射,以支持 SAI提供的抽象。SAI的最初定义仅支持基础的路由、桥接等很少内容。此后 SAI也在不断持续发展,目前 SAI 已经是 GitHub 上的一个开源项目。
https://github.com/opencomputeproject/SAI
Switchdev
为了解决内核抽象中缺少数据转发芯片的抽象,Cumulus Networks 和Mellanox,及其他一些内核开发者,创建了一种新的 Linux 内核设备抽象模型,称为switchdev。
用户接口
网络运营人员习惯于使用特定于网络设备的命令行。与 Linux 不同,网络设备提供的 CLI (command-line interface,命令行接口) 不是 Linux 上可编的 Shell 工具。
网络设备提供的命令行工具通常是用于特定情景的 CLI,即大多数命令仅在 CLI的特定上下文内有效。例如,neighbor 1.1.1.1 remote-as 65000 仅在配置 BGP上下文中有效。你可以键人一些在前面介绍的命令 (例如“ configure”和“ router bgp 64001”) 来进入上下文。Linux 命令是非特定情景且具有可编程性,可以使用脚本进行编写。网络运营人员习惯于键入? ,不习惯按 TAB 键来补全命令,也不习惯键入--或-来指定命令选项等。
Linux内核可以构建强大复杂的网络操作系统,并不意味着 Bash 是 Linux平台上进行网络交瓦的唯一 CLI。
每个路由套件都有自己的 CLI。本书中使用的路由包 FRR 遵循 Cisco 更熟悉的 CLI模型。BIRD 是另一种流行的开源路由包,它使用类似Junos OS 的语法。对熟悉 Linux 和其他现代 Go 应用程序的人们而言,他们会觉得 goBGP的 CLI 更熟悉。
因此,在 Linux 下没有单一的、统一的开源网络命令接口。Cumulus 推出了开源软件包,例如: ifupdown2,可与基于 Debian 的系统 (例如 Ubuntu) 一起使用,但它不适用基于红帽的系统。FRR的 CLI似乎是最接近于一致。FRR 拥有一个活跃的充满活力的社区,人们一直在为它添加新功能。如果你要配置一个纯的路由网络,FRR 可以作为单一的统一的网络 CLI。如果要进行网络虚拟化,你必须使用本机的Linux 命令或 ifupdown2去配置 VXLAN 和绑定 (port-channel) 接口,尽管FRR正在添加这些功能。
NOS模型和云原生NOS的需求进行比较
| 需求 | 用户空间模型 | 混合模型 | 内核模型 | switchdev模型 |
|---|---|---|---|---|
| 可编程 | 专有API | 专有API | 大多数是开源 | 开源 |
| 能够添加新监控代理程序 | 仅是NOS支持 | 大多数NOS支持 | 大多数支持 | 大多数支持 |
| 能够运行现成分布式应用程序 | 仅是NOS支持 | 大多数NOS支持 | 支持 | 支持 |
| 能够替换路由协议包 | 不支持 | 不支持 | 支持 | 支持 |
| 运营人员能够修复软件错误 | 不支持 | 不支持 | 开源组件支持 | 开源组件支持 |
| 支持新交换芯片 | NOS供应商支持 | NOS供应商支持 | NOS供应商支持 | 交换芯片支持 |
使用ping程序说明混合模型和内核空间模型是如何工作的。
这里我们忽略纯的用户空间模型,因为这种模型下,网络应用程序都必须由供应商提供的,并运行在用户空间内,与内核无关。
(在Arista EOS上执行)
ping 应用程序被用于查看一个IP 地址是否可达,让我们看看运行 ping 应用程序时发生了什么。假设我们ping 10.1.1.2,该地址可通过交换机端口 2 到达。我们假设内核的路由表在两种模型下都包括该路由信息。
首先,无论是内核模式还是混合模型,交换芯片端口在 Linux 内核中作为正常的以太网端口表示,只是名字有所不同。Cumulus 把这些端口命名为 swp1、swp2 等,而 Arista 把它们命名为 Ethernet1、Ethernet2 等。
在任何一种模式下,一些实现选择实现一个专有内核驱动,挂钩在表示交换芯片端口的 netdevs 的后面。另外一种实现是选择使用内核的 Tun/Tap 驱动,这些设备将数据包返回给 NOS 供应商用户空间上处理数据包转发的组件。在 Cumulus 上,专用驱动由交换机所使用的交换芯片供应商提供。在 Arista 上,专有驱动由 Arista 自己提供。
基于原生内核交换芯片的数据包流
交换芯片供应商定义了 CPU 和交换芯片之间进行数据包通信的内部数据包头。内部数据包头指定接收或发送数据包的端口,及交换芯片是否需要进行的额外的数据包处理等。这些内部数据包头只用于交换芯片和 CPU 之间通信,不用于交换机之外。
因为内核驱动负责将数据包发送到交换芯片上,当 ping 命令发生时,会发生下面一系列操作:
1)应用程序ping 打开一个套接字,发送数据包到 10.1.1.2。该步骤和在一台运行Linux的服务器上执行 ping 命令是一样的。
2)内核路由表指向端口 swp2 作为下一跳。交换芯片 tx/rx 驱动发送数据包到交换芯片上,以将数据包发送到下一跳路由器。
3)当 ping 的响应消息到达之后,交换芯片会将数据包发送到内核。交换芯片 tx/rx驱动收到数据包后,将数据包发送到内核,内核会认为是从本地网卡收到数据包对数据包进行处理
4)内核决定将数据包发送到应用程序 ping 的套接字上,应用程序 ping 将接收到数据包。
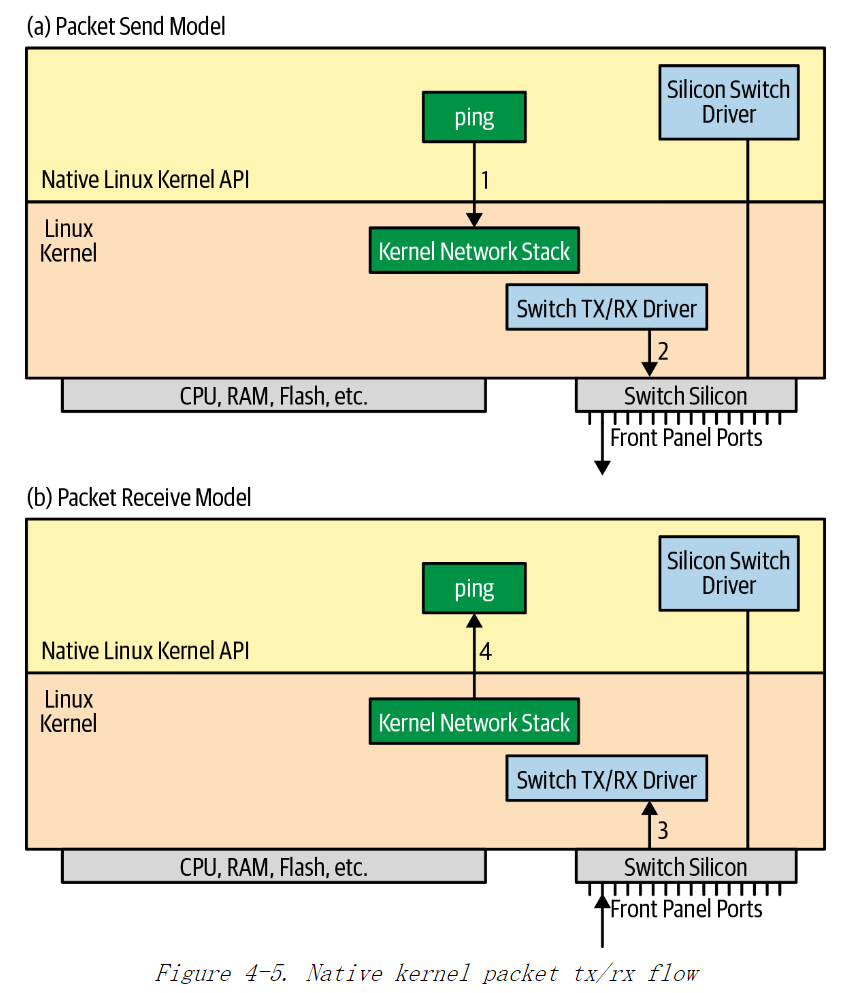
图 4-5 展示了内核交换芯片的数据包流。可以看出,此过程不涉及用户空间中的交换芯片驱动程序。
尽管上面相同的命令顺序也会发生在 Arista 交换机上,但 Arista 交换机会请求交换芯片处理这个数据包,数据包像来自交换芯片上的某个端口,交换芯片可以正确地转发此数据包。Arista 交换机请求交换芯片处理是根据之前提到的内部数据包头来决定的。换言之,即使内核已经对数据包做了处理,交换芯片也会重新执行数据包转发。无论数据包是本地起源的,还是通过其他方式接收的,Arista 可以声明所有的数据包都是通过交换芯片以相同的方式转发的。
基于Tun/Tap设备的数据包流
其他一些商业网络操作系统使用 Tun/Tap 虚拟网络设备在内核中创建交换机端口映射到交换芯片端口上。
Tun/Tap 设备
Linux 内核支持两种虚拟网络设备: Tun (Tunnel,隧道)设备和 Tap 设备。Tun 设备驱动支持路由,Tap 设备支持桥接。Tun/Tap 设备都支持用户空间网络栈。在最初的设计中,Tun 设备用于完成 VPN (Virtual Private Network,用户空间虚拟私有网)加密和解密功能。Tun/Tap 设备还用于添加对IP 隧道协议的支持,如:GRE。
Tun/Tap 驱动创建的网络设备为
/dev/tapN(N 是添加的 tap 设备编号)。用户空间程序栈绑定这个设备。如果路由表和桥接表这样的网络查询表,有指向Tap 设备的规则,内核会转发数据包到匹配的接口上,对应的用户空间栈会接收到此数据包。当用户空间栈发送数据包到 Tap 设备上,内核像从正常的网络设备上接收到数据包一样解析和处理此数据包,最后,将此数据包发送给数据包的接收程序。
Tun/Tap 设备的主要行为是将数据包从内核空间返回到用户空间。这样,当用户空间栈程序作为虚拟机运行时,NOS 供应商可以在用户空间栈中完成数据包转发。现在 ping 程序的执行步骤顺序如图 4-6 所示
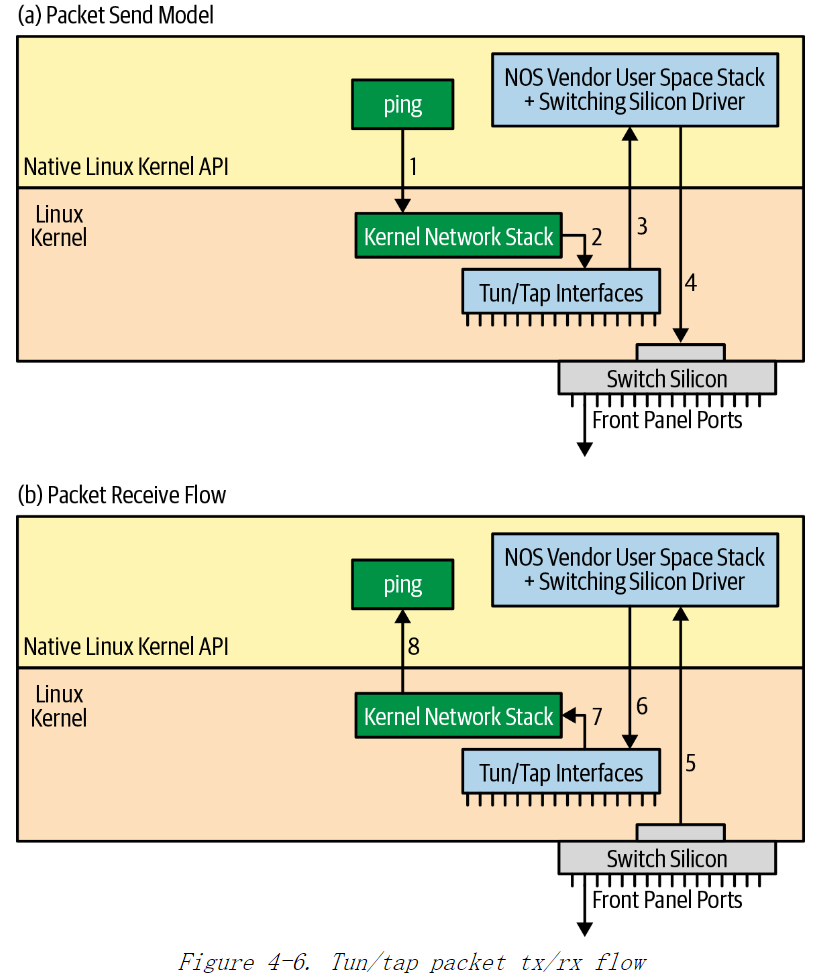
1)应用程序 ping 打开套接字,发送数据包到 10.1.1.2。
2)根据内核路由表规则,内核执行数据包转发,发送数据包到端口 et2
3)端口 et2 是一个 Tun/Tap 设备,数据包将被发送到 NOS 供应商的用户空间栈
4)用户空间栈程序执行任何必要的特定于供应商的处理,然后使用数据包转发芯片的实际驱动,将数据包发送到相应的交换芯片上的端口。
5)当收到 ping 程序回复时,交换芯片发送数据包到用户空间栈。
6)用户空间栈程序处理完数据包,将数据包写入适当的 Tun/Tap 设备上。例如,如果通过交换芯片端口 3 接收回包,那么数据包被写到了对应的 Tun/Tap 端口et3 上。
7)内核收到数据包,像从正常的网络设备 (例如:网卡) 上收到的数据包一样对数据包进行处理。
8)最终,内核将数据包发送给 ping 进程。
上面是 ping 这样的第三方应用程序发送和接收数据包的过程。一些采用混合模型的NOS 供应商在实际交换机上也会使用 Tun/Tap 模型。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









