







摘要
程序合成致力于生成一个计算机程序,作为对给定问题规范的解决方案,该规范通过输入输出示例或自然语言描述来表达。大型语言模型的普及推动了程序合成领域的最新进展,尽管有限的训练资源和数据阻碍了对此类模型的开放访问。为了普及这一技术,我们在自然语言和编程语言数据上训练并发布了一系列多达161亿参数的大型语言模型,称为CODEGEN,并开源了训练库JAXFORMER。我们通过展示该模型在HumanEval上的零样本Python代码生成任务中与之前的最新技术相媲美,来证明其效用。我们进一步研究了程序合成的多步骤范式,其中单个程序被分解为指定子问题的多个提示。为此,我们构建了一个开放的基准测试,多轮编程基准测试(MTPB),包含115个多样化的问题集,这些问题集被分解为多轮提示。我们在MTPB上的分析表明,以多轮方式提供给CODEGEN的相同意图显著优于以单轮方式提供的程序合成。我们将训练库JAXFORMER和模型检查点作为开源贡献提供:https://github.com/salesforce/CodeGen。
1 引言
传统上,创建程序通常需要人工手动输入代码。程序合成的目标是自动化编码过程,并生成满足用户指定意图的计算机程序。有人称之为计算机科学的圣杯(Manna & Waldinger, 1971; Gulwani et al., 2017)。成功的程序合成不仅可以提高经验丰富的程序员的生产力,还可以使更广泛的受众能够进行编程。
在努力实现程序合成时,出现了两个关键挑战:(1)搜索空间的难处理性,以及(2)正确指定用户意图的困难。为了保持表达性的搜索空间,需要一个大搜索空间,这给高效搜索带来了挑战。以前的工作(Joshi et al., 2002; Panchekha et al., 2015; Cheung et al., 2013)利用领域特定语言来限制搜索空间;然而,这限制了合成程序的适用性。相反,虽然通用编程语言(例如C,Python)广泛适用,但它们为可能的程序引入了更大的搜索空间。为了在巨大的程序空间中导航,我们将任务制定为语言建模,学习给定前一个标记的下一个标记的条件分布,并利用变压器(Vaswani et al., 2017)和大规模自监督预训练。这种方法在各种模式中都取得了成功(Devlin et al., 2019; Lewis et al., 2020; Dosovitskiy et al., 2021)。同样,先前的工作已经开发了用于编程语言理解的预训练语言模型(Kanade et al., 2020; Feng et al., 2020)。
为了成功实现程序合成,用户必须采用某种方式向模型传达他们的意图,例如逻辑表达式(指定程序输入和输出之间的逻辑关系)、伪代码、输入输出示例或自然语言中的口头规范。一方面,完整的正式规范享有用户意图的精确规范,但可能需要用户具备领域专业知识并努力将意图转化为这种形式。另一方面,仅基于输入输出示例的规范成本较低,但可能不足以指定意图,导致解决方案不准确。先前的工作已经从各种方法及其组合中受益,作为程序合成模型的输入,包括伪代码(Kulal et al., 2019)、程序的一部分及其文档(Chen et al., 2021)或带有输入输出示例的自然语言段落(Hendrycks et al., 2021)。然而,我们认为真正用户友好的意图形式是自然语言文本。
为了克服这些挑战,我们提出了一种多轮程序合成方法,用户通过逐步提供自然语言规范与合成系统进行通信,同时以合成子程序的形式接收系统的响应,这样用户与系统一起在多个步骤中完成程序。以下两个考虑因素激发了这种方法。
首先,我们推测将潜在的长而复杂的规范分解为多个步骤将有助于模型的理解,从而增强程序合成。在多轮方法中,模型可以专注于与一个子程序相关的规范,并避免艰难地跟踪子程序之间的复杂依赖关系。这除了指定用户意图的便利性之外,还有效地减少了搜索空间。确实,我们的推测在我们的实验中得到证实,通过多轮方法合成了更高质量的程序。
其次,代码展示了一种交错的自然语言和编程语言的弱模式,这可能是可利用的。这种模式由程序员形成,他们用注释解释程序的功能。通过语言建模目标,我们假设这种交错模式为模型提供了一个监督信号,以在多个轮次中生成给定自然语言描述的程序。这个信号非常嘈杂或弱,因为只有一部分数据会展示这种模式,注释可能不准确或信息不足,其中一些甚至可能放置在无关的位置。然而,扩大模型和数据规模可能会克服这种弱监督,使模型能够发展多轮程序合成能力。这使得用户意图可以以多轮方式表达,即意图可以分解并逐步实现,而每一轮都可以轻松地用自然语言表达。
在这项工作中,我们开发了一个多轮编程基准测试,以衡量模型的多轮程序合成能力。要解决基准测试中的问题,模型需要与用户一起在多个步骤中合成程序,用户在每一轮中以自然语言指定意图。请参见图1中的示例,其中模型合成了一个程序来提取电子邮件地址的用户名。基准测试的性能通过专家编写的测试用例的通过率来衡量。据我们所知,这是第一个多轮程序合成基准测试,它允许对多轮程序合成进行定量分析。随着大型语言模型中多轮程序合成能力的出现,有利于问题解决,我们相信这个基准测试将促进程序合成的未来研究。
我们的贡献 我们的工作与最近和同时期的努力(Chen et al., 2021; Austin et al., 2021; Li et al., 2022)共享了采用语言模型进行程序合成的基本思想,这些努力使用单轮用户意图规范。此外,我们在以下四个方面做出了贡献:
• 我们研究了在扩展定律下自回归模型中出现的多轮程序合成。
• 我们利用这种能力引入了一种多轮程序合成范式。
• 我们用一个新颖的多轮编程基准测试定量研究了其特性。
• 我们将开源模型检查点和自定义训练库:JAXFORMER。
对于程序合成,没有与Codex竞争的大规模模型可作为开源使用。这阻碍了进步,因为训练这些模型所需的昂贵计算资源只有有限数量的机构可以访问。我们的开源贡献允许广泛的研究人员研究和推进这些模型,这可能会极大地促进研究进展。
2 模型训练
为了评估在扩展定律下多轮编程能力的出现,我们采用了标准的基于变压器的自回归语言模型,变化(1)模型参数的数量 ( 350 M , 2.7 B , 6.1 B , 16.1 B ) (350\mathbf{M},2.7\mathbf{B},6.1\mathbf{B},16.1\mathbf{B}) (350M,2.7B,6.1B,16.1B)和(2)训练语料库中编程语言的标记数量。为了扩展训练,开发了一个用于TPU-v4硬件的自定义库JAXFORMER,并将作为开源发布,包括训练好的模型权重。
2.1 数据集
CODEGEN模型系列依次在三个数据集上进行训练:THEPILE、BIGQUERY和BIGPYTHON。
自然语言数据集THEPILE是一个825.18 GiB的英语文本语料库,由Gao等人(2020年)为语言建模收集(MIT许可证)。该数据集由22个不同的高质量子集构成,其中一个是从GitHub仓库收集的编程语言数据,这些仓库拥有超过100颗星,占数据集的 7.6 % 7.6\% 7.6%。由于THEPILE的大部分是英语文本,因此生成的模型被称为自然语言CODEGEN模型(CODEGEN-NL)。
多语言数据集BIGQUERY是Google公开可用的BigQuery数据集的一个子集,该数据集包含多种编程语言的代码(在开源许可证下)。对于多语言训练,选择了以下6种编程语言: C , C + \mathbb{C},\mathbb{C}+ C,C+,Go, Java, JavaScript和Python。因此,我们将BıGQUERY上训练的模型称为多语言CODEGEN模型(CODEGEN-MULTI)。
单语言数据集BIGPYTHON包含大量Python编程语言的数据。我们于2021年10月从GitHub编译了公共的、非个人信息,包括宽松许可的Python代码。因此,我们将BIGPYTHON上训练的模型称为单语言CODEGEN模型(CODEGEN-MONO)。
预处理遵循以下步骤:(1)过滤,(2)去重,(3)标记化,(4)洗牌,和(5)连接。有关THEPILE的详细信息,我们参考Gao等人(2020年)。对于BIGQUERY和BIGPYTHON,我们参考附录|A表[5]总结了训练语料库的统计信息。
2.2 模型
CODEGEN模型采用自回归变压器形式,以预测下一个标记的语言建模作为学习目标,训练数据包括自然语言语料库和从GitHub精选的编程语言数据。这些模型以不同的规模进行训练,参数数量分别为350M、2.7B、6.1B和16.1B。前三种配置允许与在文本语料库上训练的开源大型语言模型GPT-NEO(350M、2.7B)(Black等人,2021年)和GPT-J(6B)(Wang & Komatsuzaki,2021年)进行直接比较。模型规格详见附录A中的表6。
CODEGEN模型在数据集上按顺序进行训练。首先,CODEGEN-NL在THEPILE上进行训练。接着,CODEGEN-MULTI从CODEGEN-NL初始化并在BIGQUERY上进行训练。最后,CODEGEN-MONO从CODEGEN-MULTI初始化并在BIGPYTHON上进行训练。
程序合成能力的出现,依赖于自然语言描述,可能源于模型和数据的大小、训练目标以及训练数据本身的特性。这种现象被称为“涌现”,因为我们没有明确地在注释-代码对上训练模型。类似的现象在广泛的自然语言任务中也被观察到,其中大规模的无监督语言模型能够以零样本的方式解决未见过的任务(Brown等人,2020年)。涌现现象或令人惊讶的零样本泛化通常归因于模型和数据的巨大规模。
虽然我们的重点不是揭示为什么程序合成能力会从简单的语言建模中涌现的潜在机制,但我们尝试根据我们的建模方法和训练数据的特性提供一个解释。数据包括来自GitHub的常规代码(未经手动选择),其中一些数据展示了自然语言和编程语言交错的模式,我们认为这种模式为程序合成能力提供了噪声监督信号,这是由于下一个标记预测的训练目标。然而,我们强调这种数据模式非常嘈杂且弱,因为只有一部分数据展示这种模式,例如,注释可能不准确或信息不足,有些甚至可能放置在无关的位置。
因此,我们认为两个主要因素促成了程序合成能力:1)模型大小和数据大小的巨大规模;2)训练数据中的噪声信号。
这种大型语言模型的扩展需要数据和模型并行。为了满足这些需求,开发了一个训练库JAXFORMER(https://github.com/salesforce/jaxformer),用于在Google的TPU-v4硬件上进行高效训练。有关技术实现和分片方案的更多详细信息,请参阅附录A。表6总结了超参数。
3 单轮评估
我们首先使用现有的程序合成基准测试HumanEval(MIT许可证)(Chen等人,2021年)评估我们的CoDEGEN。HumanEval包含164个手写的Python编程问题。每个问题提供了一个提示,描述了要生成的函数、函数签名以及以断言形式提供的示例测试用例。模型需要根据提示完成一个函数,使其能够通过所有提供的测试用例,从而通过功能正确性来衡量性能。由于用户意图在单个提示中指定并一次性提供给模型,我们将HumanEval上的评估视为单轮评估,以区别于我们在下一节中介绍的多轮评估。根据Chen等人(2021年)的方法,我们采用核采样(Holtzman等人,2020年)和top- p p p,其中 p = 0.95 p=0.95 p=0.95。
3.1 HUMANEVAL性能随模型大小和数据大小的变化而变化
我们将我们的模型与Codex模型(Chen等人,2021年)进行比较,后者在HumanEval上展示了最先进的性能。此外,我们的模型还与开源的大型语言模型GPT-NEO(Black等人,2021年)和GPT-J(Wang & Komatsuzaki,2021年)进行了比较。这些模型在THEPILE(Gao等人,2020年)上训练,因此在训练数据和模型大小方面与我们的CoDEGEN-NL模型相似。所有模型在温度 t ∈ { 0.2 , 0.6 , 0.8 } t\in\{0.2,0.6,0.8\} t∈{
0.2,0.6,0.8}下进行评估,我们计算每个模型的pass@ k k k,其中 k ∈ { 1 , 10 , 100 } k\in\{1,10,100\} k∈{
1,10,100}。为了直接与Chen等人(2021年)的结果进行比较,我们选择为每个 k k k产生最佳性能pass@ k k k的温度。

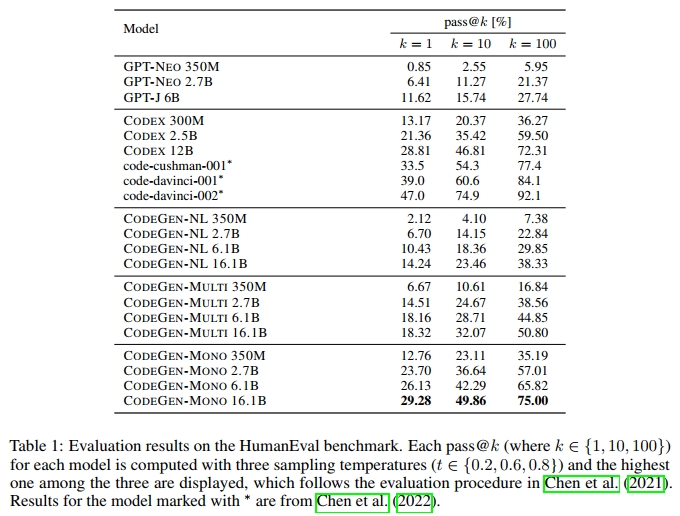
我们的模型和基线模型的结果总结在表1中。我们的CODEGEN-NL模型(350M、2.7B、6.1B)优于或与相应的GPT-NEO和GPT-J模型表现相当。
在多语言编程语言数据(BIGQUERY)上进一步训练CODEGEN-NL,得到CODEGEN-MULTI。多语言CODEGEN模型大幅优于在THEPILE上训练的模型(GPT-NEO、GPT-J、CODEGEN-NL)。然后,我们在仅包含Python的数据集(BIGPYTHON)上对CODEGEN-MULTI进行微调,得到CODEGEN-MONO。程序合成能力得到了显著提升。因此,随着Python训练数据量的增加,Python程序合成能力也得到了增强。对于几乎所有模型,正如预期的那样,增加模型的大小可以提高整体性能。
我们的Python单语言CODEGEN模型与当前最先进的模型Codex相比,具有竞争力或更好的性能。当 k = 100 k = 100 k=100时,CODEGEN-MONO 2.7B表现不如CODEX 2.5B,但当 k ∈ { 1 , 10 } k \in \{1, 10\} k∈{ 1,10}时表现更好。虽然其大小仅为一半,我们的CODEGEN-MONO 6.1B的pass@ k k k得分接近表现最佳的Codex模型CODEX 12B。我们最大的模型CODEGEN-MONO 16.1B根据 k k k的不同,具有竞争力或优于CODEX 12B。
3.2 更好的用户意图理解带来更好的合成程序
程序合成系统的成功在很大程度上取决于其对用户意图的理解程度。当系统基于语言模型时,问题提示的困惑度可以作为系统理解用户意图规范的代理。模型下意图规范的低困惑度表明该意图规范与模型从训练数据中学到的知识兼容。我们研究了更好的提示理解(以较低的提示困惑度为代理)是否会导致功能更准确的程序。
我们将所有问题分为通过和未通过两类。通过问题是指至少有一个样本(从200个样本中)通过所有测试用例的问题,而未通过问题是指200个样本中没有一个通过所有测试用例的问题。我们基于CODEGEN-MONO模型的样本计算通过问题提示的平均困惑度和未通过问题提示的平均困惑度。结果如表2所示(有关CODEGEN-NL和CODEGEN-MULTI的结果,请参见附录F)。通过问题的提示困惑度低于未通过问题的提示困惑度。这一发现表明,当模型更好地理解用户意图规范时,程序合成更有可能成功。事实上,一些训练数据包含自然语言注释和程序的交错序列,其中注释描述了后续程序的功能。因此,我们推测与这种模式类似的用户意图规范会被模型更好地理解,从而带来更好的程序合成。受这种模式的启发,我们建议以多轮方式指定用户意图,使模型每次专注于部分问题,从而使模型更容易理解用户意图。
4 多轮评估
在本节中,我们提出并研究了一种多步骤程序合成范式,其中程序合成分解为多个步骤,系统在每一步合成一个子程序。为了检验这种范式,我们首先开发了一个多轮编程基准测试(MTPB)。MTPB由专家编写的115个问题组成,每个问题包括自然语言的多步骤描述(提示)。要解决一个问题,模型需要合成功能正确的子程序,(1)遵循当前步骤的描述,并且(2)考虑先前步骤的描述和合成的子程序(例如,正确引用先前步骤中定义的函数和/或变量)。图1展示了一个示例。

4.1 基准测试构建
我们(4位作者)首先定义了一组包含115个问题的集合,这些问题需要广泛的编程知识,包括数学、数组操作、字符串处理、算法、数据科学以及其他知识领域的问题,以确保每个类别中的问题数量大致平衡。对于每个问题,我们构建了一个由多轮提示P、测试用例输入I和测试用例输出O组成的三元组。多轮提示P的设计遵循两个约束条件:(1)问题被分解为3轮或更多轮,(2)单轮提示不能完全解决问题。例如,实现一个线性回归模型可以表述为“对x和y进行线性回归”。由于主要任务在此提示中完全表达,理解此提示足以执行任务。我们通过手动检查避免此类情况,并将问题解决分布在多轮中。除了提示外,我们还要求问题作者准备5组测试用例输入I和输出O,以评估模型输出的功能正确性。为了减少错误奖励那些生成无意义程序但通过测试的假阳性解决方案,我们检查并修订这些情况,以确保测试质量。
与HumanEval不同,模型在HumanEval中需要完成一个部分定义的函数,而MTPB问题仅提供提示,因此模型必须从头生成解决方案。虽然自由形式的生成可能允许更多的潜在解决方案,但缺乏提供测试用例输入的入口点使得在不同测试用例上测试生成的代码具有挑战性。为了克服这一挑战,我们在提示中嵌入测试用例输入。具体来说,提示使用Python的格式化字符串编写,当特定测试用例应用于问题时,输入值将替换变量名。
例如,提示“定义一个名为‘s’的字符串,其值为{var}。”与测试用例输入var = ‘Hello’将格式化为“定义一个名为‘s’的字符串,其值为‘Hello’。”另请参见图1中的示例1。
4.2 执行环境与解决方案评估
在执行过程中,提示和生成的补全对的历史被连接成一个自包含的程序(参见图1中的示例3)。然后,程序在隔离的Python环境中执行,遵循单轮HumanEval基准测试(Chen等人,2021年)。然而,HumanEval中的问题构造方式使得已知的函数签名被补全,因此在一组功能单元测试下调用生成的代码是微不足道的。在我们的多轮案例中,无法保证生成这样的入口点(或返回值)。为了解决缺少返回签名(或值)的问题,MTPB中多轮问题的最后一个提示总是被指定为将结果状态打印到终端。然后,基准测试执行环境重载Python的print(args)函数,并将args存储在堆栈上。如果问题的最后一个提示的采样代码不包含print()语句(这是Python或特别是Jupyter笔记本中打印到终端的有效约定),则生成的代码的抽象语法树(AST)将被修改以注入print()的调用。最后,对args与预定义的黄金输出进行类型宽松的等价检查(例如,列表和元组之间的隐式转换),以确定测试失败或成功。
4.3 多步编程能力随模型大小和数据大小扩展
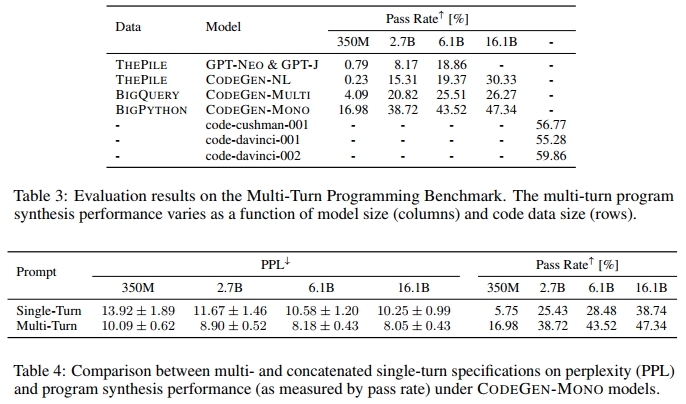
在本分析中,我们研究了模型大小和数据大小如何影响多轮范式中的程序合成能力。在MTPB中,每个问题有5个测试用例,我们为每个测试用例使用每个模型采样40个样本,基于此计算每个问题的通过率。我们的CODEGEN模型、基线模型和OpenAI Codex模型在MTPB上的评估结果(平均通过率)如表3所示。显然,MTPB上的性能随着模型大小和数据大小的增加而提高。这表明多步程序合成能力随着模型大小和数据大小的增加而扩展。这些模型仅通过自回归语言建模目标进行训练。随着模型和数据的扩展,多轮程序合成能力出现,即以多轮方式合成程序的能力。
4.4 通过多轮分解更好地理解用户规范
我们假设多轮分解增强了模型对用户意图规范的理解,从而提高了程序合成能力。为了验证这一假设,我们将多轮规范连接成单轮规范,形成单轮对应版本。如第3.2节所述,我们采用提示困惑度作为用户意图理解的代理。因此,我们比较了多轮提示和连接后的单轮提示在四个CODEGEN-MONO模型下的困惑度。
MTPB中所有问题的平均困惑度(计算细节见附录E)显示在表4的左面板中。对于所有模型,单轮规范的平均困惑度高于多轮规范。这意味着多轮用户规范可以被模型更好地理解。我们注意到,较大模型下的多轮和单轮意图规范的平均困惑度略低于较小模型下的困惑度,表明较大模型比小模型更好地理解用户意图。
我们比较了使用多轮提示和连接后的单轮提示的程序合成通过率。结果如表4的右面板所示。对于所有模型大小,多轮规范的通过率比单轮规范高出接近或超过10个百分点。结合上述困惑度分析,将用户规范分解为多个步骤并利用大型语言模型的能力,使它们更容易消化规范并更成功地合成程序。
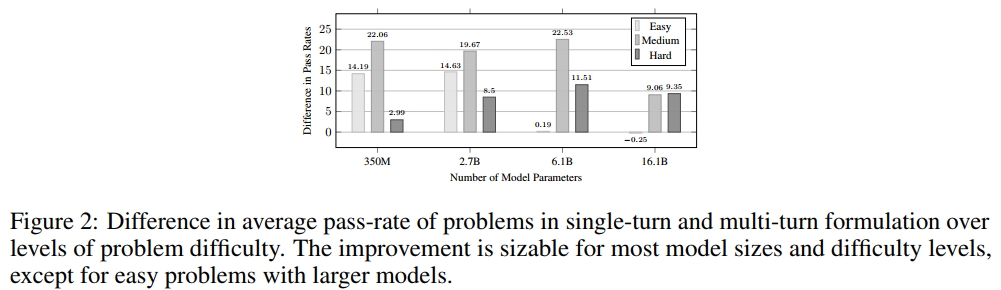
此外,我们根据问题的平均通过率将问题按难度分类(“难”为小于30%,“易”为大于70%),并研究了难度级别和模型大小对多轮分解改进的交互影响。结果见图2。在几乎所有模型大小和难度级别中,多轮提示比单轮提示带来了显著的改进,大多数改进接近或超过10个百分点。有趣的是,较大模型(6.1B和16.1B)在简单问题上对多轮分解不敏感(见图2中的两个短条,0:19%和−0:25%)。这意味着当问题容易被模型理解时(由于问题的简单性和较大模型的高能力的综合作用),分解规范没有必要或益处。这与我们的动机假设一致,即分解复杂规范可以简化问题理解并提高程序合成。
4.5 定性示例
为了进一步理解模型行为在不同模型大小下的差异,我们检查了大模型与小模型表现显著不同的问题。我们特别选择了CODEGEN-MONO 16.1B和CODEGEN-MONO 2.7B表现显著差异的问题。在CODEGEN-MONO 16.1B表现显著较差的问题上,我们观察到较大模型由于字面理解提示而变得不灵活。例如,初始化数字总是导致整数,尽管提示要求转换为字符串(图3),或者提示中的“return”关键字触发了函数定义,而意图是直接生成可执行程序(图4)。然而,总体上,较大规模的模型克服了较小模型由于提示误解而犯的错误,包括同时分配多个变量(图5)或理解任何比较的概念(图6)。
5 相关工作
程序合成 尽管程序合成有着悠久的历史,但两个固有的挑战仍未解决:(1)程序空间的难处理性和(2)准确表达用户意图的困难(Manna & Waldinger, 1971; Gulwani et al., 2017)。大量先前的研究尝试通过探索随机搜索技术(Parisotto et al., 2017; Schkufza et al., 2013)和演绎式自上而下搜索(Gulwani, 2011; Polozov & Gulwani, 2015)等方法来应对(1)。然而,这些方法的可扩展性仍然有限。用户意图可以通过多种方法表达:形式逻辑规范、输入输出示例和自然语言描述。完整的形式规范需要太多努力,而像输入输出示例这样的非正式规范往往无法充分说明问题(Gulwani, 2011)。由于大规模模型和数据带来的良好学习的条件分布和语言理解能力,为这两个挑战提供了有效的解决方案。一些研究探讨了将对话意图转换为可编程表示,如SQL(Yu et al., 2019a;b)或数据流图(Andreas et al., 2020)。我们提出的基准测试要求生成Python代码,这更为通用和复杂。
大型语言模型 变压器通过注意力机制捕捉序列元素之间的依赖关系(Bahdanau et al., 2014),并且具有高度可扩展性。它已成功应用于自然语言处理(Devlin et al., 2019; Lewis et al., 2020; Raffel et al., 2020)、计算机视觉(Dosovitskiy et al., 2021)和许多其他领域(Oord et al., 2018; Jumper et al., 2021)。先前的工作,如CuBERT(Kanade et al., 2020)、CodeBERT(Feng et al., 2020)、PyMT5(Clement et al., 2020)和CodeT5(Wang et al., 2021),已将变压器应用于代码理解,但这些工作主要集中在代码检索、分类和程序修复上。最近和同时期的几项研究探索了使用大型语言模型进行程序合成(Chen et al., 2021; Austin et al., 2021; Li et al., 2022; Fried et al., 2022)及其有效性(Vaithilingam et al., 2022)。虽然它们专注于单轮生成代码,但我们提出将规范分解为多轮,并证明这对提高合成质量非常有效。值得注意的是,Austin等人(2021)探索了通过多次迭代改进代码,但这本质上是一种单轮方法,因为每一轮都生成一个完整的程序。通过中间信息提示预训练语言模型以提高任务性能引起了兴趣(Nye et al., 2021; Wei et al., 2022)。我们提出的MTPB还允许模型利用过去的轮次作为上下文。
程序合成基准测试 为了定量评估程序合成模型,已经提出了几种具有不同输入形式的基准测试。流行的输入形式包括同一行中的前导代码(Raychev et al., 2016)、伪代码(Kulal et al., 2019)、文档字符串和函数签名(Chen et al., 2021)或问题描述(Hendrycks et al., 2021)。在大多数情况下,只向模型提供直接相关的输入信息。相比之下,一些先前的工作实例化了基准测试,这些基准测试衡量了在给定目标程序之外的周围程序上下文(如变量和其他方法)(Iyer et al.,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











