







摘要
现代层次化视觉 transformer 在追求监督分类性能的过程中,加入了多个特定于视觉的组件。虽然这些组件提高了准确性并且使 FLOP 计算具有吸引力,但它们增加的复杂性实际上使得这些 transformer 比其原始 ViT 对应物更慢。本文认为,这些额外的负担是没有必要的。通过使用一个强大的视觉预训练任务(MAE),我们可以在不失去准确性的情况下,去除所有“花里胡哨”的部分,简化当前的多阶段视觉 transformer。在这个过程中,我们创建了 Hiera,这是一种极其简单的层次化视觉 transformer,它比之前的模型更准确,同时在推理和训练过程中显著更快。我们在多个图像和视频识别任务上评估了 Hiera。我们的代码和模型可以在 https://github.com/facebookresearch/hiera 上获取。
1. 引言
自从 Dosovitskiy 等人(2021)几年前首次提出 Vision Transformers(ViTs)以来,ViT 在计算机视觉的多个任务中占据了主导地位。尽管 ViT 在架构上简单,但其准确性(Touvron 等,2022)和扩展能力(Zhai 等,2021)使得它仍然是今天的热门选择。此外,它们的简单性解锁了强大的预训练策略,例如 MAE(He 等,2022),这使得 ViT 在训练时具备了计算和数据效率。
然而,这种简单性是有代价的:由于在整个网络中使用相同的空间分辨率和通道数,ViT 并未高效地利用其参数。这与之前的“层次化”或“多尺度”模型(例如,Krizhevsky 等,2012;He 等,2016)形成了对比,这些模型在早期阶段使用较少的通道和较高的空间分辨率,特征较简单,而在模型后期使用更多的通道和较低的空间分辨率,特征较复杂。
许多特定领域的视觉 transformer 被提出并采用了这种层次化设计,例如 Swin(Liu 等,2021)或 MViT(Fan 等,2021)。然而,在追求使用 ImageNet-1K 上的完全监督训练来实现最先进的结果(这是 ViT 历史上表现不佳的领域)时,这些模型变得越来越复杂,添加了许多专用模块(例如,CSWin 中的交叉形窗口(Dong 等,2022),MViTv2 中的分解相对位置嵌入(Li 等,2022c))。虽然这些变化使得模型在 FLOP 计算上更具吸引力,但其内部的复杂性却使得这些模型总体上变得更慢。
我们认为,很多这种复杂性实际上是没有必要的。由于 ViT 在初始的 patchify 操作后缺乏归纳偏置,后续许多视觉特定 transformer 提出的改变实际上是在手动添加空间偏置。但为什么要通过减慢我们的架构来添加这些偏置呢?如果我们可以训练模型自己去学习这些偏置,为什么不呢?特别是,MAE 预训练已经证明是一个非常有效的工具,能够教会 ViT 空间推理,使得纯视觉 transformer 在检测任务中获得良好结果(Li 等,2022b),这一任务以前是由像 Swin 或 MViT 这样的模型主导的。此外,MAE 预训练是稀疏的,速度是普通监督训练的 4 到 10 倍,使得它不仅仅在准确性上具有吸引力,也是许多领域中已经可取的替代方法(He 等,2022;Feichtenhofer 等,2022;Huang 等,2022b)。
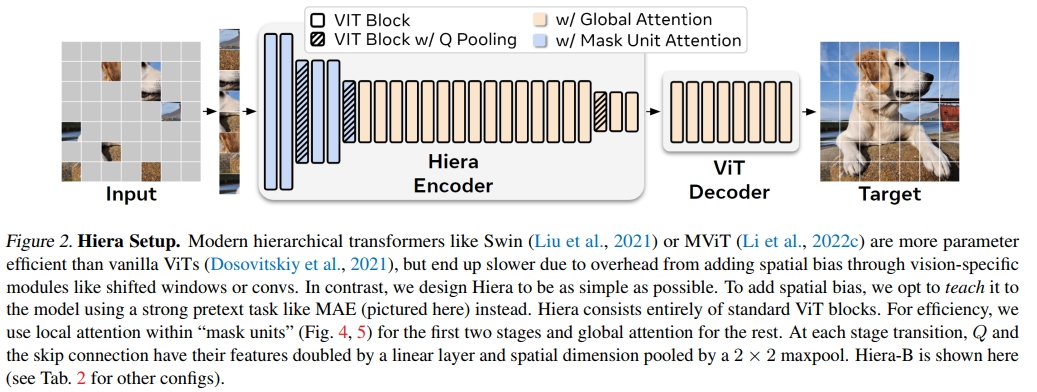
我们通过一个简单的策略来验证这一假设: 使用一些实现技巧(图 4),从现有的层次化 ViT(例如 MViTv2)中小心地去除非必需的组件,同时使用 MAE 进行训练(表 1)。在调整 MAE 任务以适应这种新架构后(表 3),我们发现实际上可以简化或去除所有非 transformer 组件,同时提高准确性。结果是一个极其高效的模型,没有“花里胡哨”的部分:没有卷积,没有平移或交叉形状的窗口,没有分解的相对位置嵌入。只是一个纯粹、简单的层次化 ViT,它在多个模型规模、领域和任务上都比之前的工作更快、更准确。
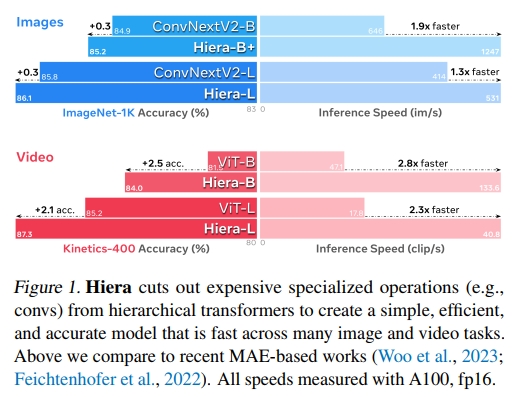
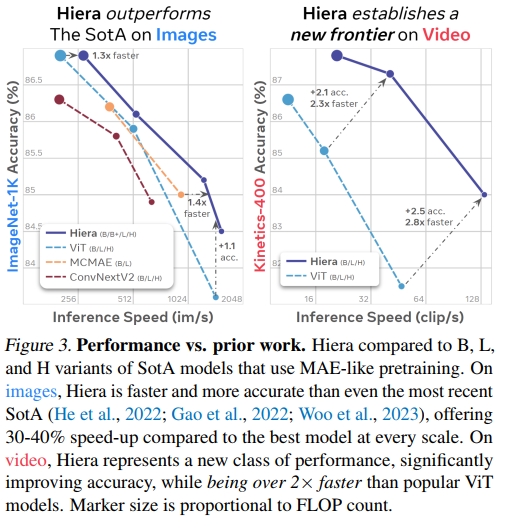
我们的简单层次化视觉 Transformer(Hiera)在图像任务上超越了当前最先进的技术,并且在视频任务上远超以往的工作,同时在每个模型规模(图 3)上都明显更快(图 1),并且在广泛的数据集和任务上表现优秀(第 5 和第 6 节)。
2. 相关工作
视觉 transformer(ViT)因其在多个视觉任务上的巨大成功而引起了关注,包括图像分类(Dosovitskiy 等,2021)、视频分类(Fan 等,2021;Arnab 等,2021;Bertasius 等,2021)、语义分割(Ranftl 等,2021)、目标检测(Carion 等,2020;Li 等,2022b)、视频目标分割(Duke 等,2021)、3D 目标检测(Misra 等,2021)和 3D 重建(Bozic 等,2021)。
Vanilla ViT(Dosovitskiy 等,2021)和之前的卷积神经网络(CNN)(LeCun 等,1998)之间的主要区别在于,ViT 将图像划分为例如 16×16 像素的非重叠块,并将空间网格展平成 1D 序列,而 CNN 在模型的多个阶段保持该网格,在每个阶段降低分辨率并引入归纳偏置,例如平移等变性。
最近,研究领域对混合方法(Fan 等,2021;Liu 等,2021;Li 等,2022c;Dong 等,2022;Wang 等,2021)表现出越来越多的兴趣,这些方法将 transformer 与类似卷积的操作和先前 CNN 的层次化阶段结构结合起来。这一方向已经取得了成功,并在各种视觉任务上达到了最先进的水平。然而,实际上这些模型比它们的 vanilla ViT 对应物更慢,并且卷积操作与流行的自监督任务(如遮蔽图像建模)不容易兼容。我们在创建 Hiera 时解决了这两个问题。
遮蔽预训练已成为学习视觉表示的一种强大的自监督学习预任务(Vincent 等,2010;Pathak 等,2016;Chen 等,2020;He 等,2022;Bao 等,2022;Xie 等,2022;Hou 等,2022)。在以往的工作中,Masked AutoEncoder(MAE,He 等,2022)利用了 vanilla ViT 的优势,ViT 允许输入的长度不受限制,因此通过利用遮蔽图像的稀疏性来推导出高效的训练方案。这极大地提高了遮蔽预训练的训练效率,但将稀疏训练应用于层次化模型并非易事,因为输入不再以固定的 2D 网格布局。
已有几项工作尝试使层次化 ViT 使用遮蔽预训练。MaskFeat(Wei 等,2022)和SimMIM(Xie 等,2022)将遮蔽的补丁替换为 [mask] token,这意味着大部分计算被浪费在不可见的 token 上,训练非常缓慢。Huang 等(2022a)引入了几种技术,使得网络的每个组件都能够支持稀疏性,最终创造了一个更加复杂的模型,但在准确性上没有显
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1307
1307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











