







cache是小容量、高速缓冲存储器,由SRAM组成,速度几乎和CPU一样快。一般将cache和主存的存储空间都划分为若干大小相同的块
1. cache工作原理
根据时间局部性和空间局部性,当处理器访问一块数据时,它很可能再次访问这块数据或者访问此存储位置附近的数据,因此cache可以在从内存中提取一个字时,也可以提取多个相邻的字,从而提高程序的访问效率。这样的一组字被称为高速缓存块或高速缓存行。
- 分块
主存中分成大小相同的块——主存块,cache中也分成大小相同的块——cache块;当CPU需从内存中读写数据时,发送主存地址cache中查看有没有相应块,若没有则需要从内存中查找并替换cache中某块,再读取,此时便会造成缺失。
cache中存放一个主存块的对应单位为行(line)或槽(slot)或项或块,每个块包括有效位,块地址标记标记(Tag),索引值,Data。
块的大小决定了块偏移,主存中块的数量(组内)决定了Tag,对于直接映射和组向量映射来说,组号决定了索引值的位数。
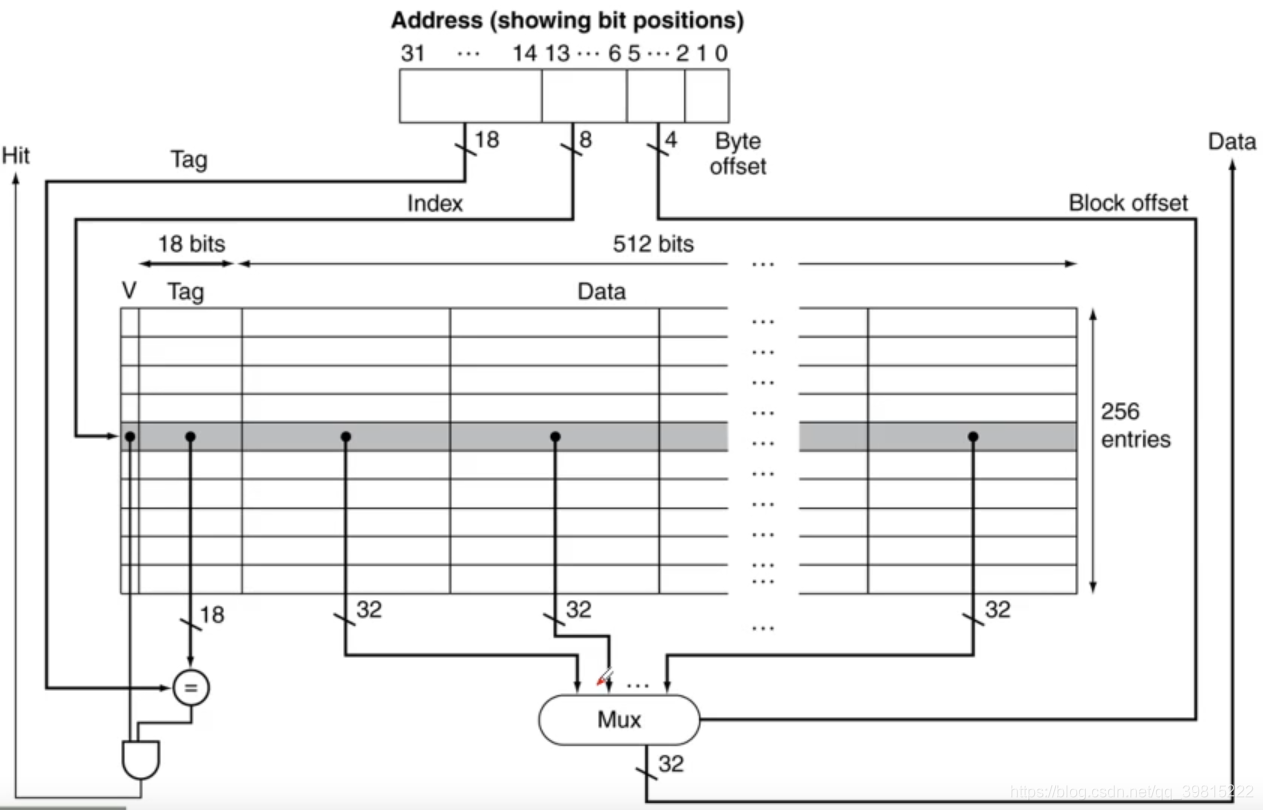
如图所示为某cache的存储阵列,{Tag,索引值,块偏移}共同组成了主存地址,CPU发出内存地址后会根据地址中的tag和cache中的tag是否相等、Valid是否为1首先确定是否命中,若命中则根据索引和偏移找出所需要的数据。
cache块号 = 主存块号 mod 关联度
- 有效位
系统上电后,cache内无有效信息,当信息从主存复制到cache中时,cache中信息有效,此时需要给每个TAG域增加一个有效位。
该有效位置位的原则是:
- 命中的cache,有效位置1
- 开机或复位时,置0
- 第一次被替换时,置1
- 操作系统加载程序前,若触发Flush信号,置0
2. 多级cache
- 多级cache中,L1 cache通常在片内,L2、 L3 cache可以在片内,也可以在片外。
- 分立cache(即指令cache和数据cache分开)有利于流水线处理器的实现
- 通常L1 cache是分立的,因为L1 cache的命中时间比命中率更重要,减少命中时间以获得较少的时钟周期
3. cache和主存间的地址映射方式
参考文献1深入浅出的讲解了cache的原理和地址组织方式
cache地址=cacheline号/组号+块内地址
1 直接映射
把主存中的每一块映射到一个固定的cache行中。即每个主存地址对应于高速缓存中的唯一地址也称模映射。
在该映射方式中,新块的位置是预先设定好的,因此在缓存块出现竞争时无须替换策略。
主存物理地址=标记+cacheline号+块内地址
内存中的块会存到取模后的cache中的对应块,即 cache line号= (主存block号) mod (cache line总数)
特点:该方式易实现、命中时间短,但不灵活,cache存储空间不能充分利用,命中率低容易造成cache抖动
2 全相联映射
主存块可装到cache任一行/槽中,因此如果要找一个指定的块,需要检索cache中所有的项。该过程是由一个与cache中每个项相关的比较器并行完成。
主存物理地址=标记+块内地址
特点:冲突小,但需要设计较多的比较器,硬件消耗较大,适合块数较小的cache
3 组映射
组内直接映射,组间全映射,即一个cache可以由多个组构成,每个组中有n个块。根据索引域,存储器中每个块对应到cache中唯一的组,并且可以放在这个组中的任一位置。检索时只需检索某组中所有块即可。
地址关系如图所示:地址=标记+组号+块内地址,即同一组内的cacheline的tag是相同的,组内则根据index确定对应的cacheline。
每组两行(2路组相联)较为常用,在较大容量的L2 cache和L3 cache中使用4路以上。
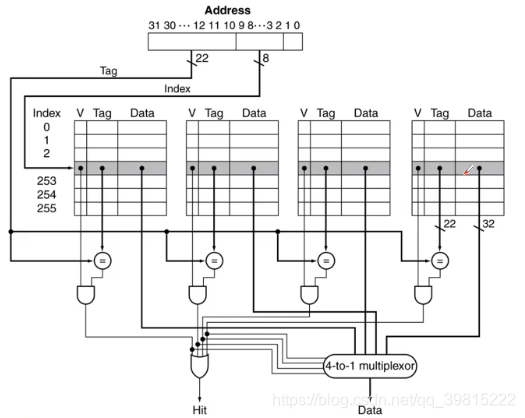
- 特点
- 该方式结合直接映射和全相联映射的特点,当cache组数为1时则为全相联映射,当每组只有一行时则为直接映射。
- 增加关联度可降低cache的失效率,但是会增加命中时间。
- 相关计算:
- 块数量 = cache有效容量/块大小
- Tag:块数量的位数
- 索引:(快数量/相联度)的位数
- 块偏移:块大小的位数
4. cache缓存一致性分析
1 cache不一致的原因
- CPU对cache中的内容更新时而没有对主存中的内容更新
- 当多个设备访问主存时,某些设备不会经过cache而直接对主存进行读写,造成cache和主存数据不一致
- 当多个CPU有各自cache而共享主存时,可能存在某CPU修改了自己的cache,但主存中和其他cache同一地址的内容没有修改
2 解决的方案
考虑的情况分为写命中的情况和写不命中的情况。
- 写命中:
- write through (写直达)
当一个写操作进行时,新值同时写到cache和主存中
为了减少写主存的开销,通常会在cache和主存之间增加write buffer,以便在一个数据等待被写入主存时,先将其存入写缓冲,CPU无需在此等待,只需存储控制器(LSU)在写操作空闲时将buffer中的数据释放。 - write back (写回策略)
当写操作发生时,新值只被写入cache中,而不写入主存中,此时cache和主存内容不一致,需要在每个cache行中增加一个dirty位,如果该位对应的cache行被修改,则该值被置为1,否则为0;当dirty为1时,才需要将该块从cache中替换出去,写回主存中
该方式减少了写主存的方式,降低了对主存带宽的需求,但是
- 写不命中
- allocate-on-miss(写分配)
先将主存块存入cache,再更新cache行中的相应单元。利用了空间局部性 - no-allocate-on-miss(写不分配)
直接写主存,而不把更新后的主存块写入cache中
- 写直达可以写分配或写不分配,写回只能用写分配
5. cache性能评估
1. cache失效分析
- cache的失效类型
cahe失效有三种类型,而容量失效和冲突失效则可能会触发cache抖动。
- 强制失效
首次访问某数据块时,必然引起的cache失效
与相联度无关,增加block大小,有利于减少此类不命中 - 容量失效
cache不能存放程序运行所需的所有块,替换后再次被使用的引发的失效
与相联度无关,增加block大小,有利于减少此类不命中 - 冲突失效
映射到同一组内的数据超过组内可容纳的块时,竞争所引起的失效
相联度越小,越容易触发,全相联则不存在此类失效
- cache性能评估——平均访问速度
cache设计中提高性能,即提高平均访问速度的方式为提高命中率和降低时效损失。
平均访问时间=命中时间+失靶率*失靶损失
- 命中率
- 失靶率
1)强制失效:增大block大小
2)容量失效:增大cache大小
3)冲突失效:全相联映射不存在该失效 - 失靶损失(失效开销):cache中没有命中,从主存中加载替换到cache所需的时间,即一个block从主存中传输到cache中的时间
2. cache替换策略
1)过程:
- 不同相联度的cache替换办法
- 直接映射
映射唯一,无条件用新信息替换旧信息 - N路组相联映射
每个主存数据有N个cache行可选择,需考虑替换哪一行 - 全相联映射每个主存数据可放在cache的任意行,需考虑替换哪一行。
2)常用算法
- FIFO
先进先出,总是把最先进入的块替换掉
实现简单,但命中率较低 - LRU
利用时间局限性,总是把最近最少使用的那块替换到。
实现办法:通过给每个cache行设定一个计数器,根据计数值来记录这些主存块的使用情况。每次每一次被访问,则该行清零,其他行加1,每次替换都替换计数值最大的那一行。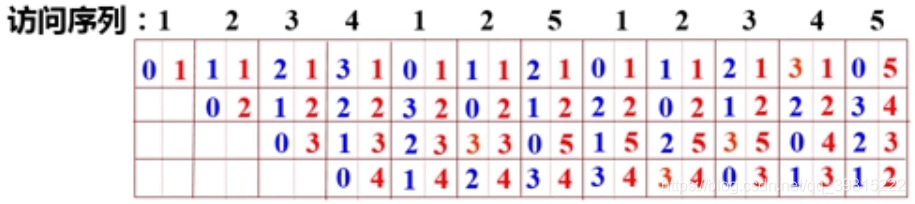
如上图所示,蓝色为计数值,红色为块号。
行越多,命中率越高,该算法较常用 - LFU
较少使用 - 随机替换算法
随机选取一行替换,较少使用
6. cache控制器的设计
下图为cache控制器的FSM转换图:
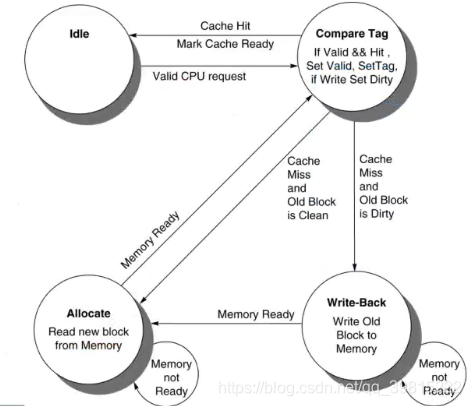
- 设计方案
- 命中时采用写回(write Back)
- 未命中时采用写分配(write allocate)
- 状态机转换
- cache默认处于idle状态,当发生有效CPU读写请求时,则进入compare Tag状态
- 如果Tag比较命中,且valid为1,则返回命中信号,并标记cache准备好
- 如果比较未命中,情况一:cache缺失且旧块干净,则进入Allocate写分配状态,该状态下会从内存中读新的块,若内存准备好则发出ready信号且回到Compare Tag状态,若未准备好则等待内存
- 如果比较未命中,情况二:cache缺失且旧块脏,则进入Write-Back状态,该状态下需要将dirty块写到内存块对应位置,若内存未准备好,将持续尝试写,若内存准备好将完成这次写操作并进入Allocate状态,若内存ready将再次回到compare Tag状态


















 2102
2102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











