









High Performance Chiplet and Interconnect Architectures,2022年6月19日,第一届会议(连同第49界ISCA会议)于美国纽约举行,旨在探讨小芯片Chiplet和互联技术对未来计算架构的影响,从而推动工业和学术界加速合作、共建Chiplet生态。
此次HiPChips也是国际上以“小芯片”为主题的研讨会首次登上计算机架构顶会的舞台,因而吸引了包括Google、Meta(Facebook)、Intel、AMD、Nvidia、苏黎世联邦理工(ETH Zurich)、伊利诺伊大学(UIUC)、加州大学洛杉矶(UCLA)、佐治亚理工(Georgia Tech)和印度理工(IIT Bombay) 等领域内顶尖行业专家和学者的参与,议题也广泛覆盖了chiplet架构、芯片设计、互联标准化等最前沿的研究和进展。
第一届会议议程及slice:
HiPChips Chiplet Workshop @ ISCA Conference
主题
- Chiplet-based accelerator level parallelism (ALP)
- Chiplet architecture for large scale system design
- Physical and logical inter-die interface design for heterogeneous architectures
- Coherent and non-coherent data sharing protocols via fast chiplet interconnection
- Chiplet architectures for in-memory computing and other emerging technologies
- ODSA-based 3D architecture for efficient ML acceleration
- Chiplet-based secure computing
- Power evaluation and performance modeling of chiplet architecture
- Software optimization framework with fast inter-chiplet network
- Chiplet topology aware ML optimizations
- Scheduling for massive heterogeneous chiplet-based processors
如何将数据在chiplets间划分,以及为了更高效的并行处理而优化数据迁移成为成功的关键。
芯片架构议题
Memory Centric Computing
系统功耗的62.7%都花在数据迁移上。
Amirali Boroumand, Saugata Ghose, Youngsok Kim, Rachata Ausavarungnirun, Eric Shiu, Rahul Thakur, Daehyun Kim, Aki Kuusela, Allan Knies, Parthasarathy Ranganathan, and Onur Mutlu, "Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks"Proceedings of the 23rd International Conference on Architectural Support for Programming
Languages and Operating Systems (ASPLOS), Williamsburg, VA, USA, March 2018.
* Chiplets Open the World of Collaboration
- Speaker: Bob Brennan (VP, Customer Solutions Engineering, Intel Foundry Services )
多种因素推动着Monolithic向chiplet发展
-
大芯片制造成本
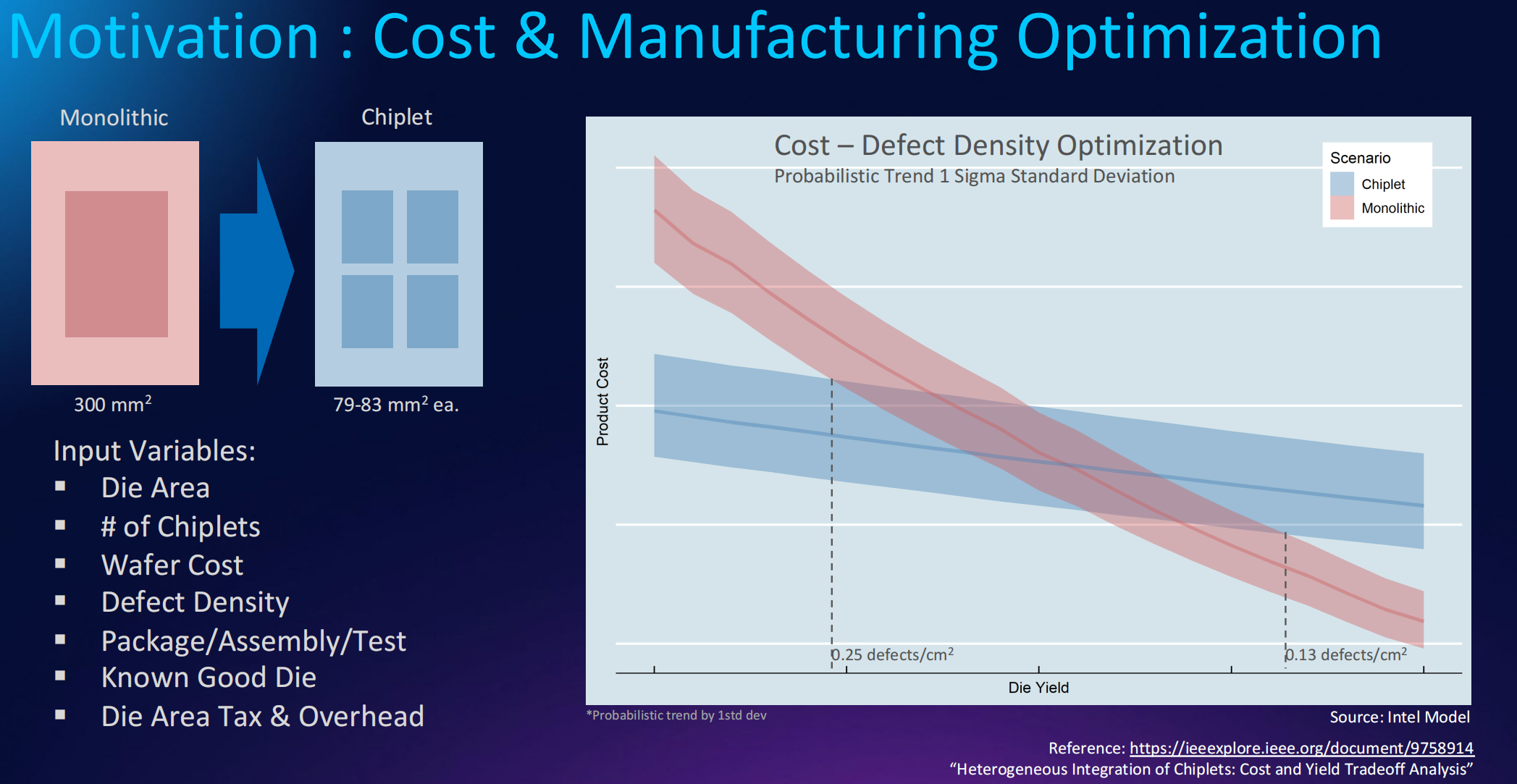
-
不同芯片对工艺的要求不同
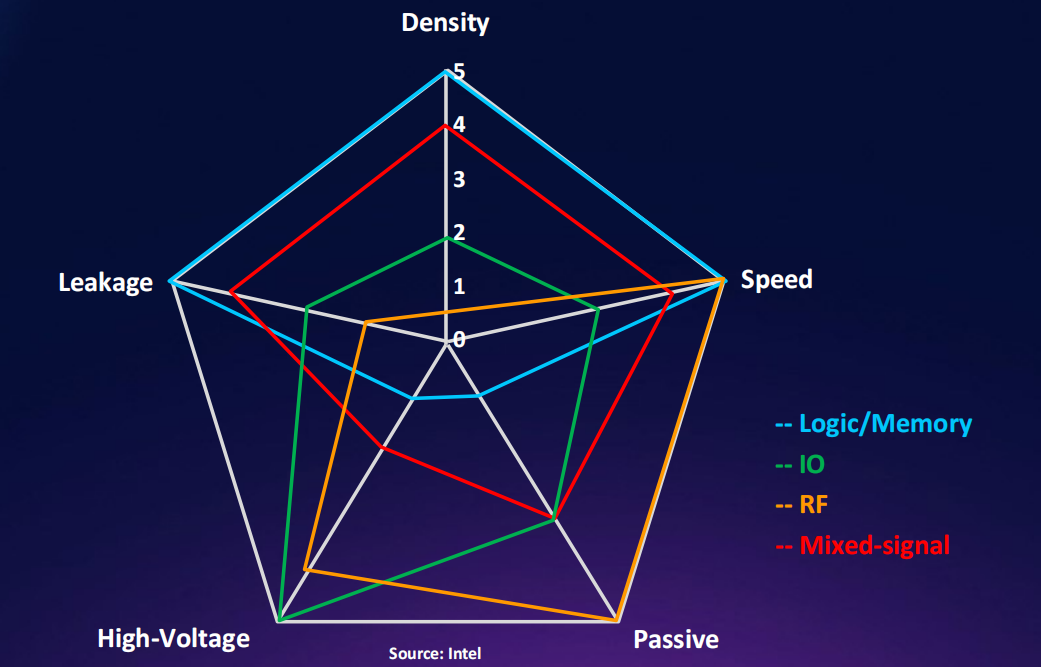
-
AI运算的带宽和供电缺口
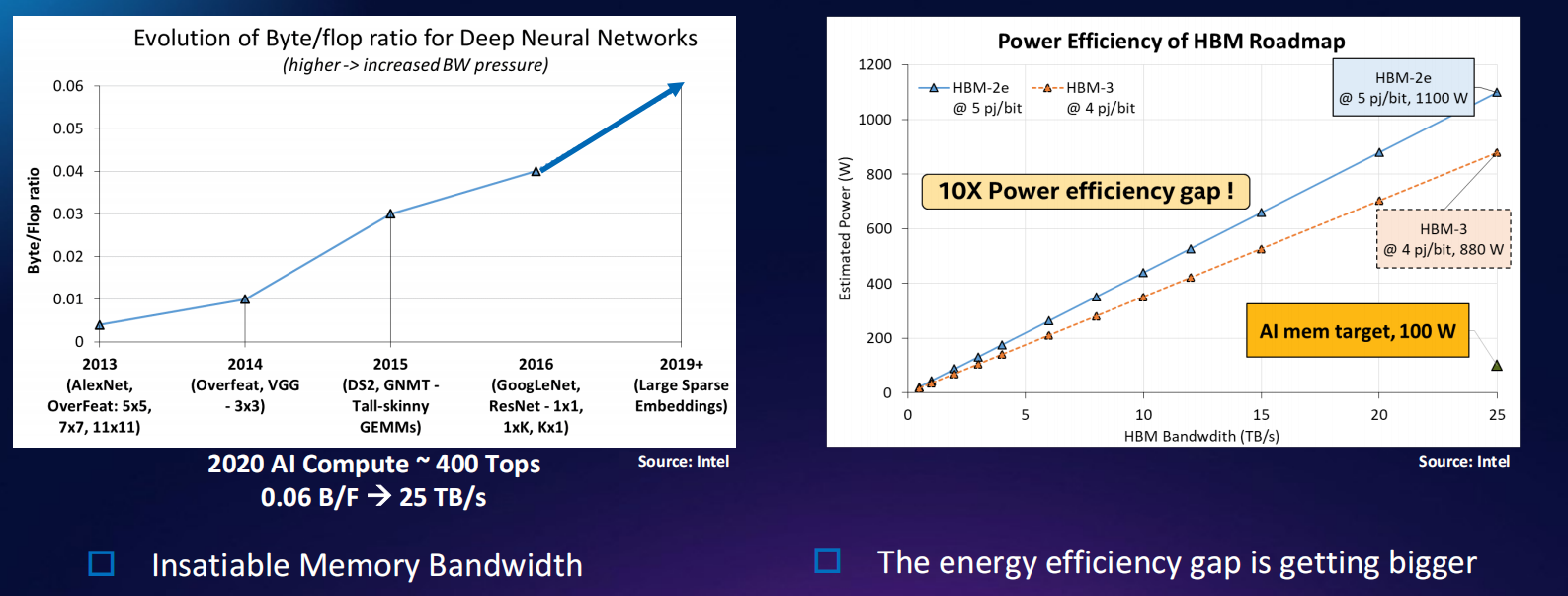
-
先进工艺下芯片设计成本和产品上市速度
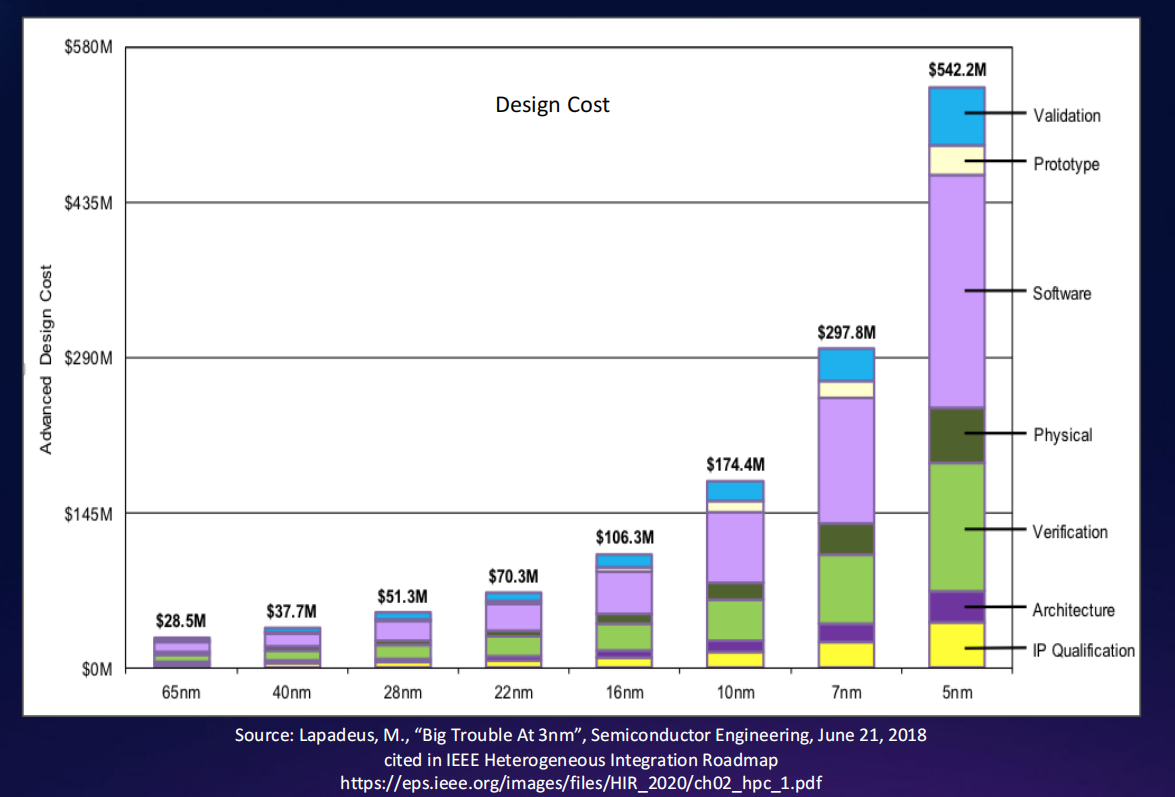
-
系统级高速IO接口的优化
单芯系统向多芯系统发展:标准接口、接口协议、软件栈

IO案例研究:分离的PCIe和内存
服务器案例研究:Multi-core uServer
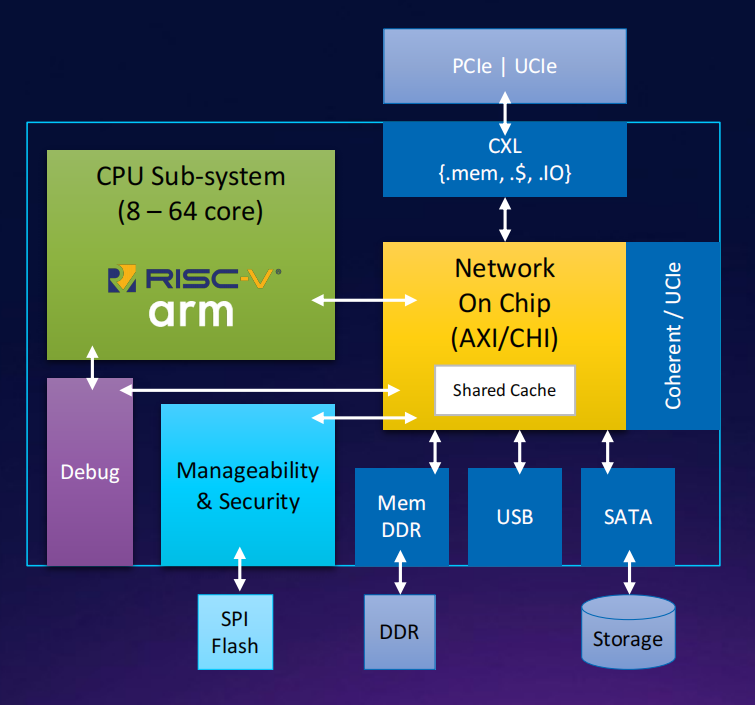
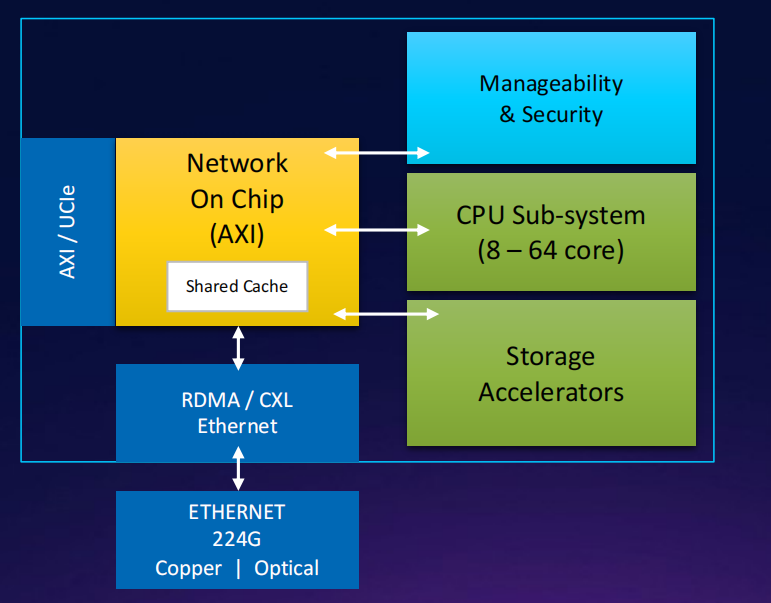
互联网络/存储案例研究:IPU/DPU
多协议架构
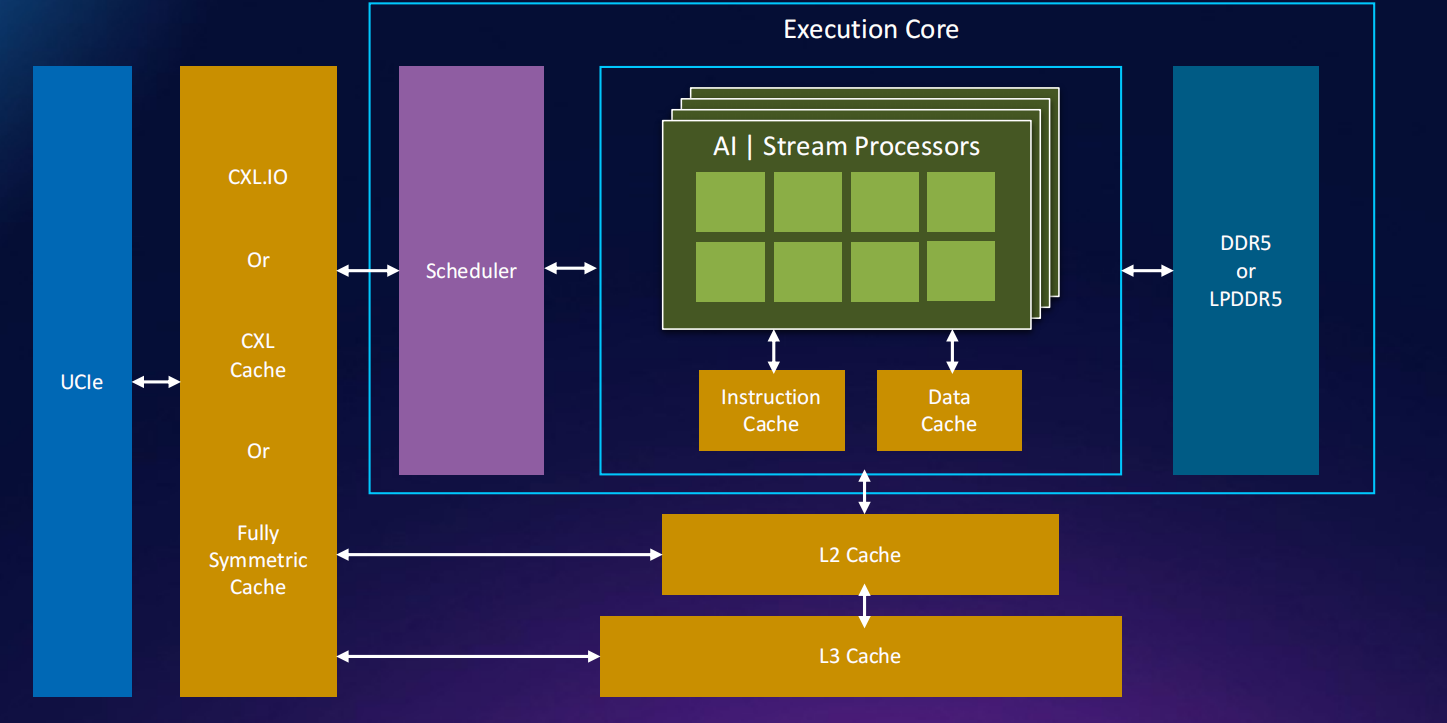
AI案例研究: 缓存推理架构
- 评
chiplet开启了世界性的合作。Intel的报告展示了其对行业内芯片架构有monolithic向chiplet发展的信心,其展示了多个邻域的应用案例,但然表示当前chiplet发展还面临一些挑战,需要生态内的各方合作解决。
Hyperscale use cases, challenges and case study for heterogenous integration
Speaker: Dharmesh Jani ( Open Ecosystem Lead, @ Meta) , Ravi Agarwal (Technical Sourcing Manager)
通常的人类行为场景
- 认知,认识世界并构建认知模型,需要大量的训练
- 挖掘,在各种类型的数据中寻找目标,需要推理
- 综合创造,创造出新的事物
AI应用场景的挑战
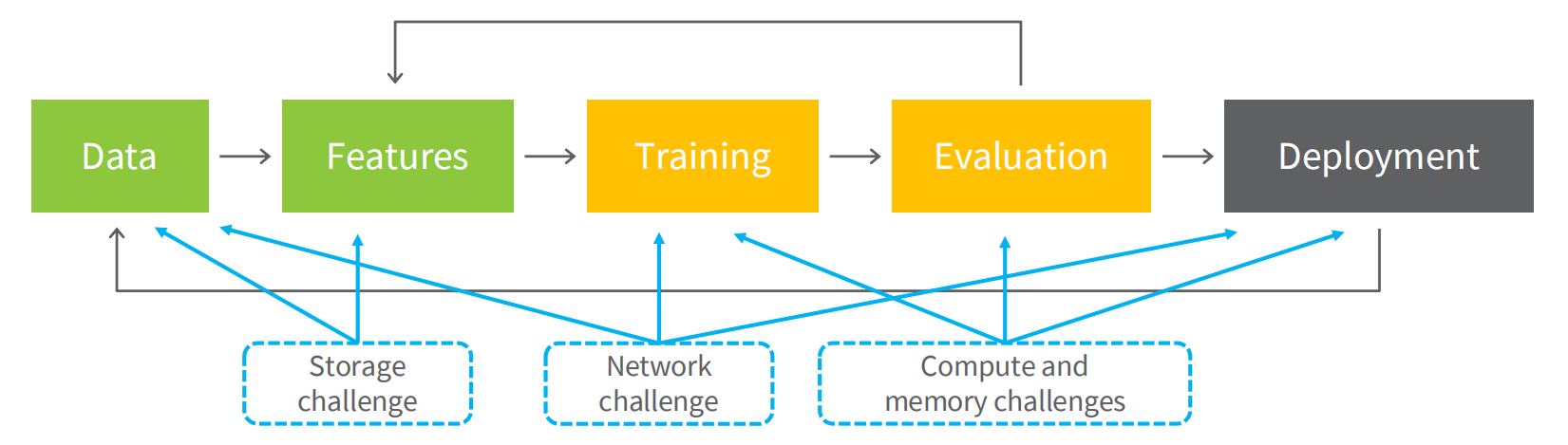
- 评
对于异构集成的超大规模芯片的使用场景、挑战和案例研究。该报告说明了AI计算面临的计算平台的困境,指出通过陷阱封装技术突破该困境。
The Road to Data Center Power Efficiency
- Speaker: Tawfik Rahal-Arabi & Anshuman Mittal (@ AMD)
摩尔定律在失效但数据中心算力需求仍在增长

客户端和数据中心的功耗管理对比

通过chiplet技术可以对芯片的功耗发送和管理
chiplet技术天生的可以进行细粒度的功耗划分和管理。
如图两种场景对比,chiplet的应用可以节约25%的功耗,但如何划分cores是一个问题

不同的方式进行电源分布
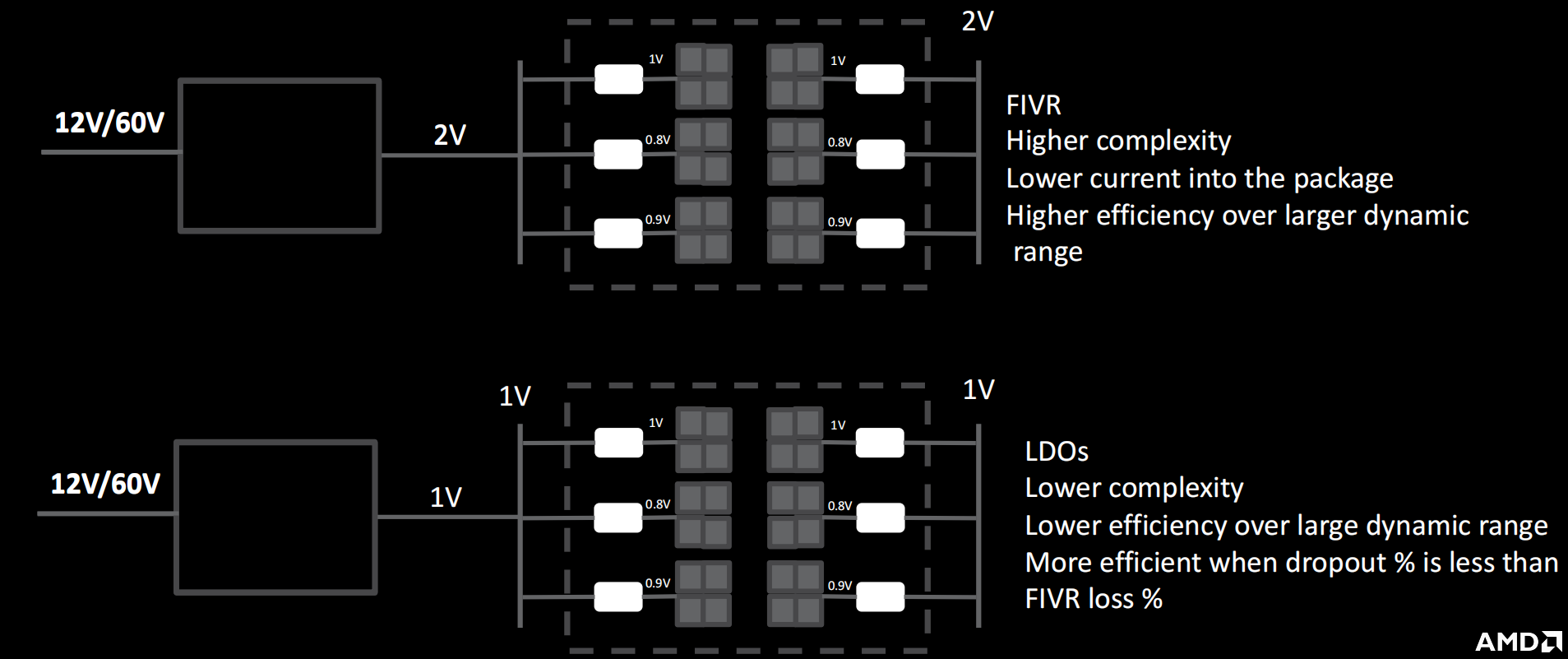
通过一些算法对功耗进行管理

- 评
通往数据中心高功效之路。AMD从产品的功耗角度对chiplet架构的构建展开菲尼,认为chiplet可以帮助软硬件更好的划分功耗和进行功耗管理。
Chiplet-based Waferscale Computing
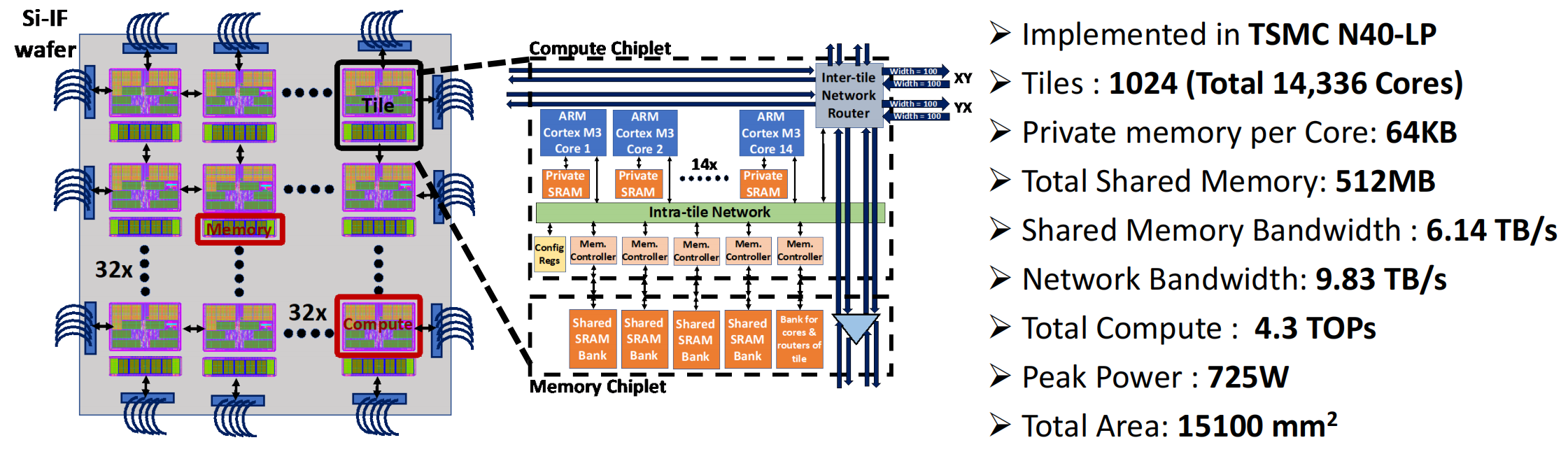
Speaker: Rakesh Kumar (@ University of Illinois Urbana-Champaign)
晶圆级计算的演变
以前的晶圆级芯片目标是将monolithic坐在一个晶圆上,成本较高

UCLA的晶圆级硅互联技术

晶圆级GPU架构
互联架构良率对比:
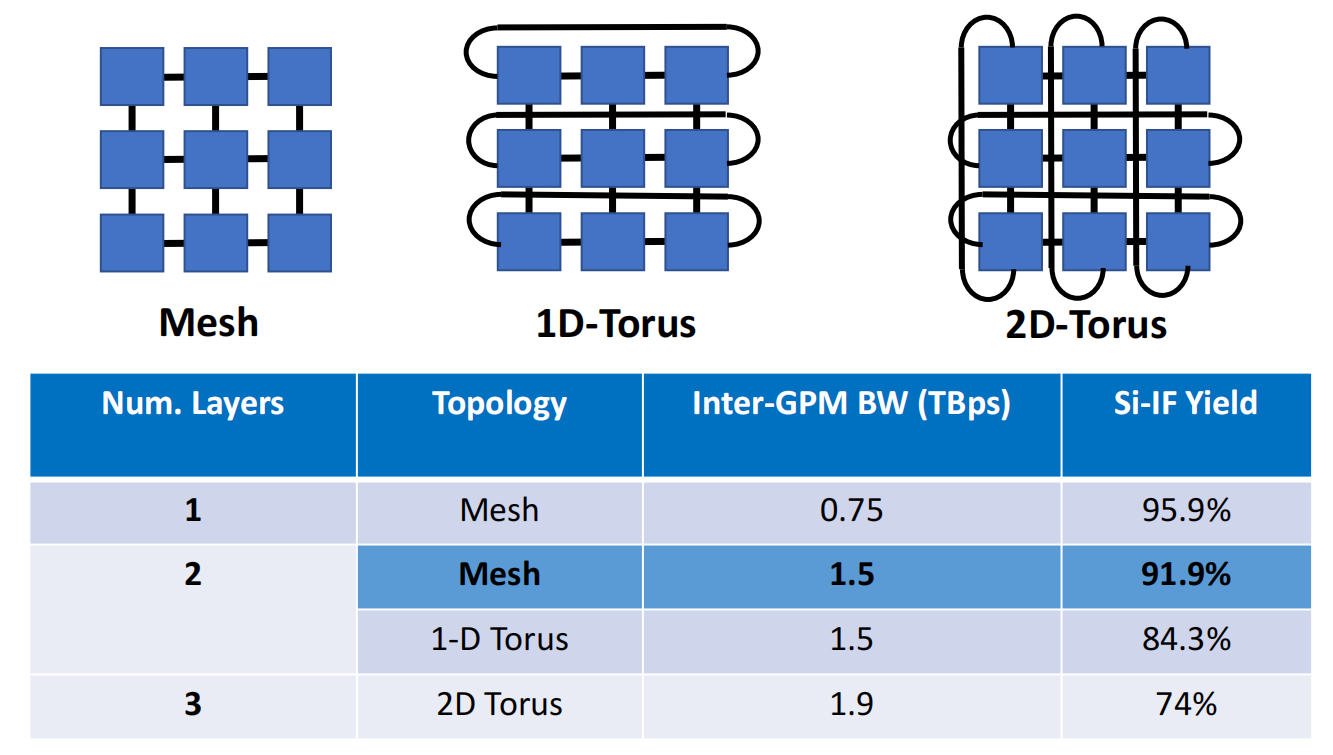
线程块和数据布局策略

相关研究
“MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability”, A. Arunkumar et. al., ISCA 2017
- 评
基于Chiplet的晶圆级计算。该报告说明了以前晶圆级芯片的局限性,介绍了芯片晶圆级的连接技术、热设计等,并以晶圆级GPU为例展示了晶圆级计算的优势,但总体感觉跟chiplet关系不大。
Designing a Waferscale Processor Prototype: Challenges and Solutions
Speaker: PUNEET GUPTA (@ UCLA)
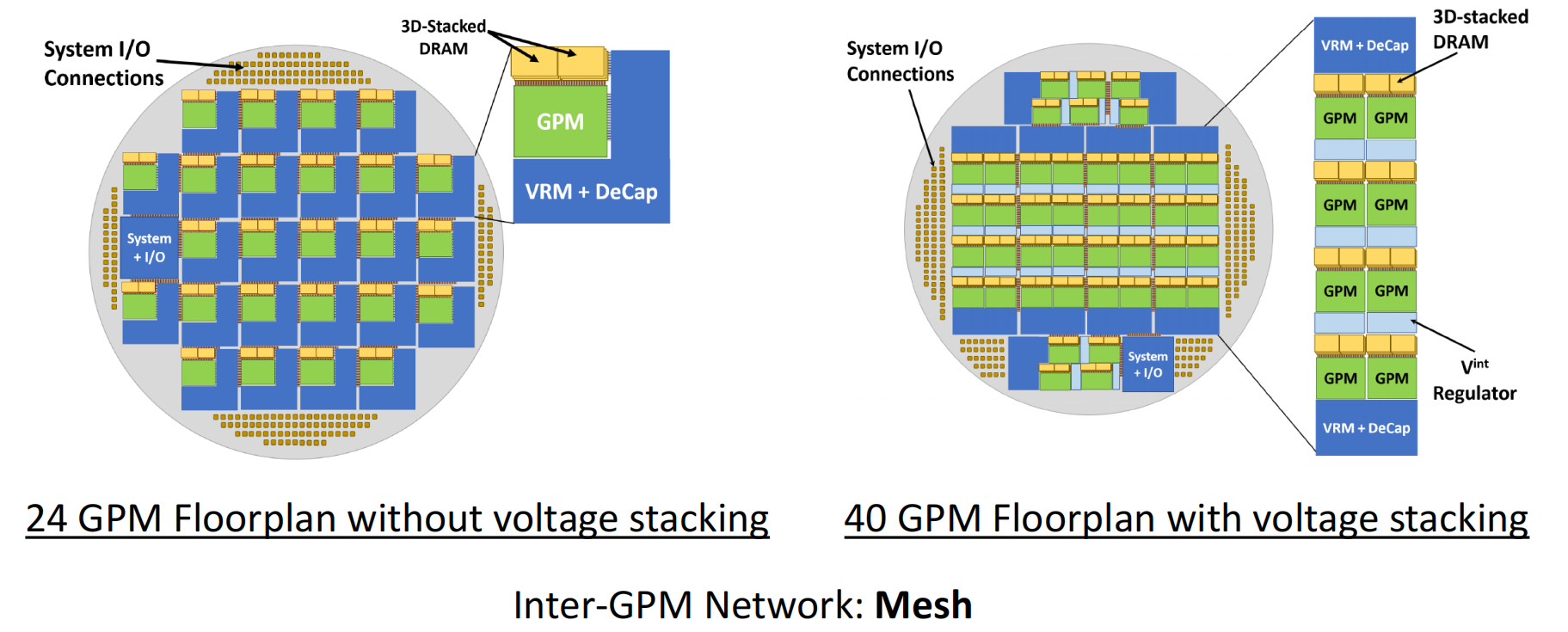
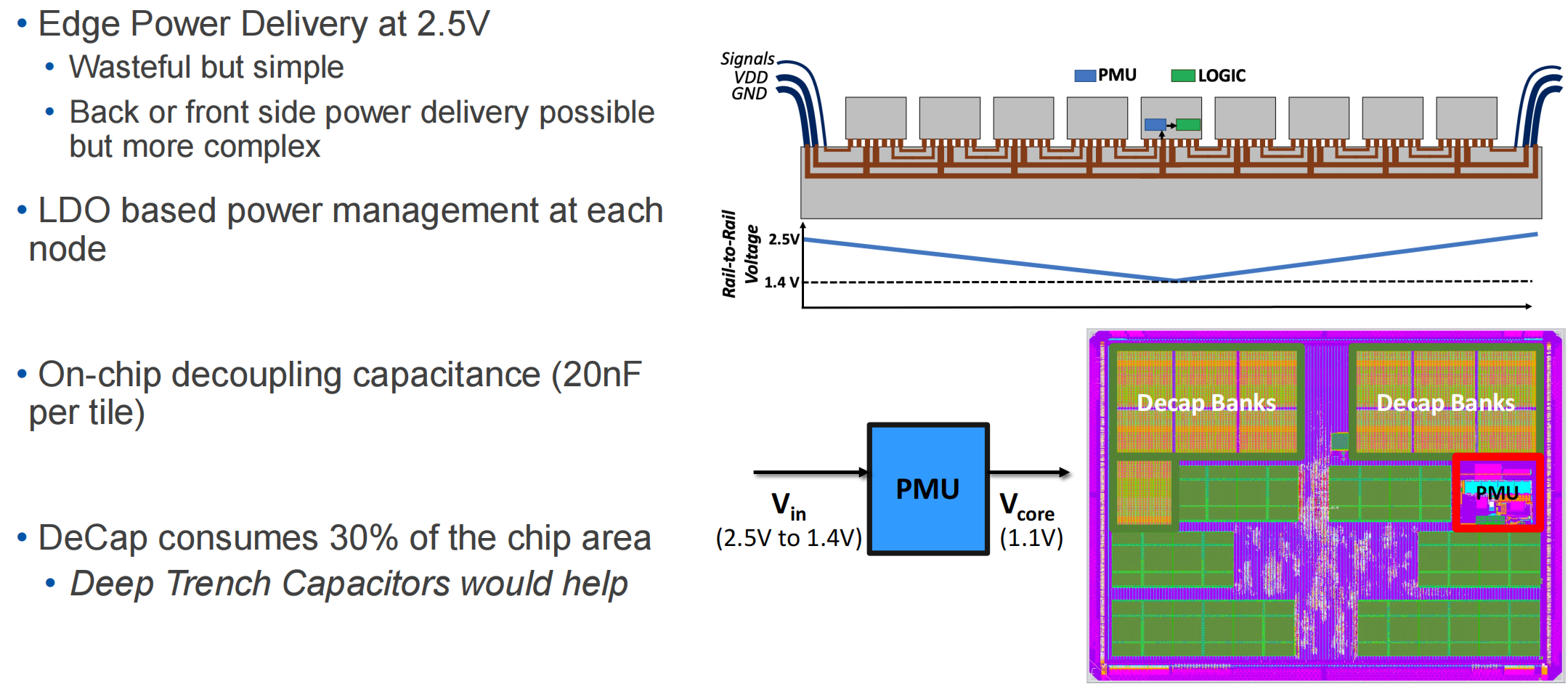
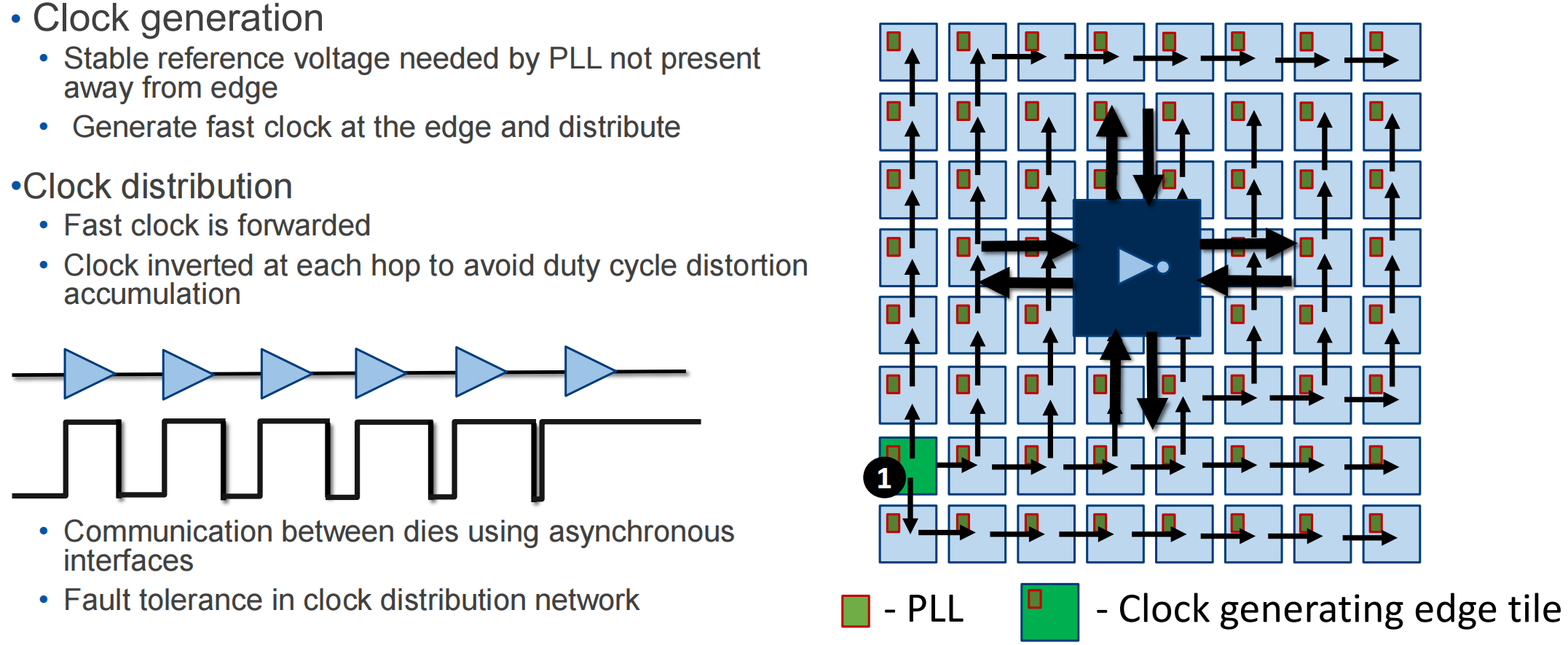
2048个chiplet的架构
晶圆级芯片设计的具体细节
晶圆级设计需要对芯片的电源、时钟、硅前后测试、IO die架构等方面分别考虑
- 评
设计基于chiplet的大规模系统。该报告相较于Chiplet-based Waferscale Computing报告更清晰的描述了芯片的架构,以及晶圆级设计需要解决的电源、时钟、测试等问题。
Heterogeneous Chiplet-based Architecture for In-Memory Acceleration of DNNs
Speaker:

大数据处理给硬件平台提出了更高的要求。
存内计算(IMC)为缓解冯诺伊曼瓶颈提供了可实现的方法。
基于crossbar的架构为深度学习网络的计算提供了很好的平台。
IMC加速器使用了一种权重值固定在片上的架构。因此IMC大芯片将因为更大的面积导致更多的功耗,因此2.5D封装的chiplet设计将是一个替代选项。
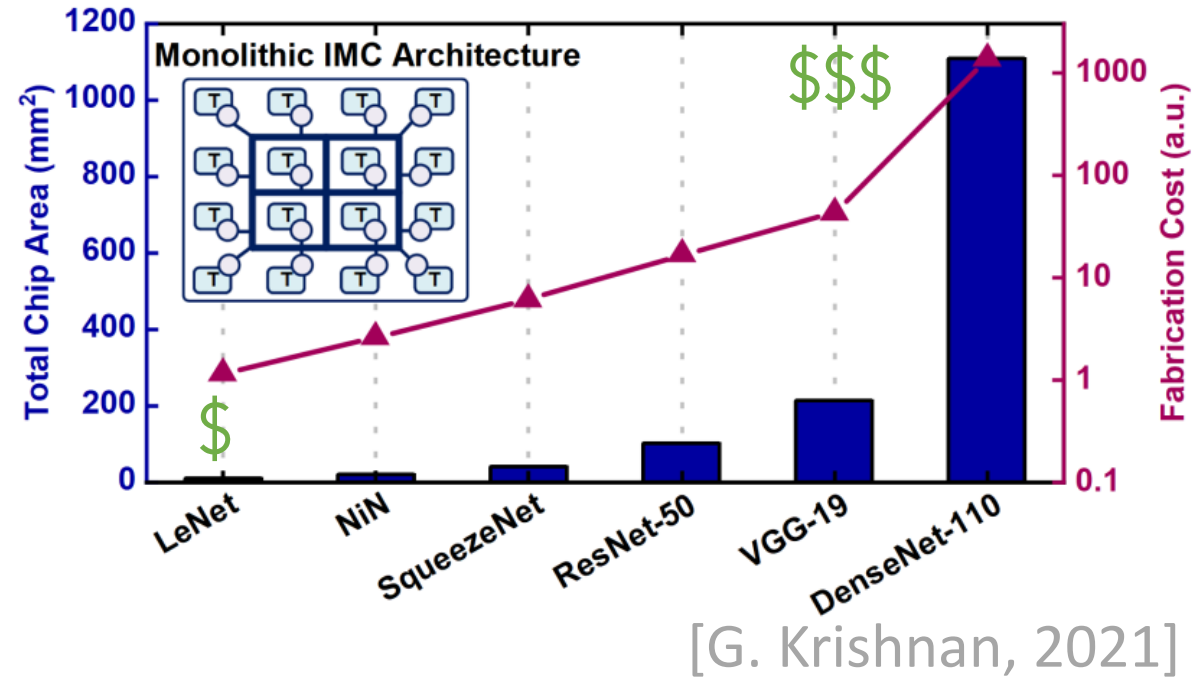
RRAM/SRAM的实践已经为基于chiplet的IMC架构进行了探索。
用户可以调试参数来对架构进行调整,包括映射、架构划分、IMC单元特征等。
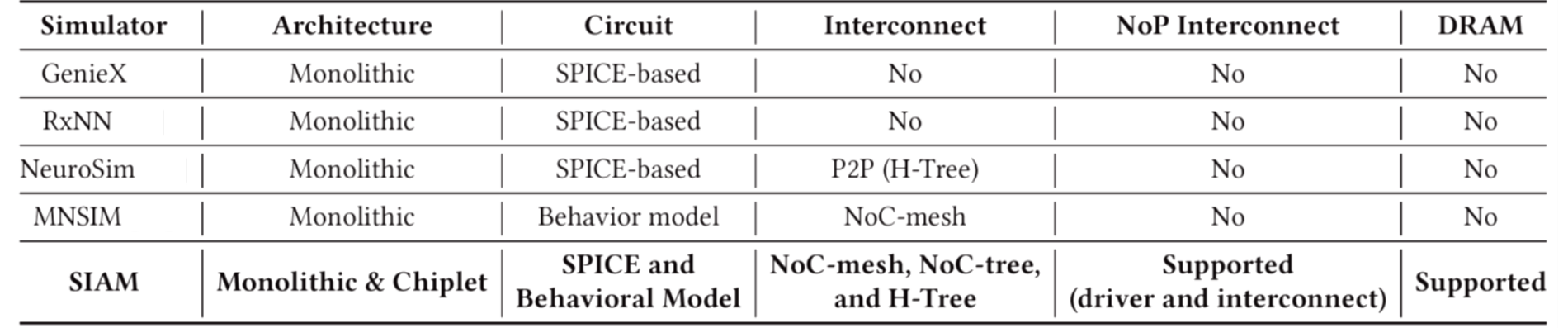
工作流程
将DNN参数、架构参数输入进SIAM,SIAM进行参数与资源的映射,包括片上互联和板级互联,并构建计算平台。评估工具对整体架构进行性能、延迟等特征评估。
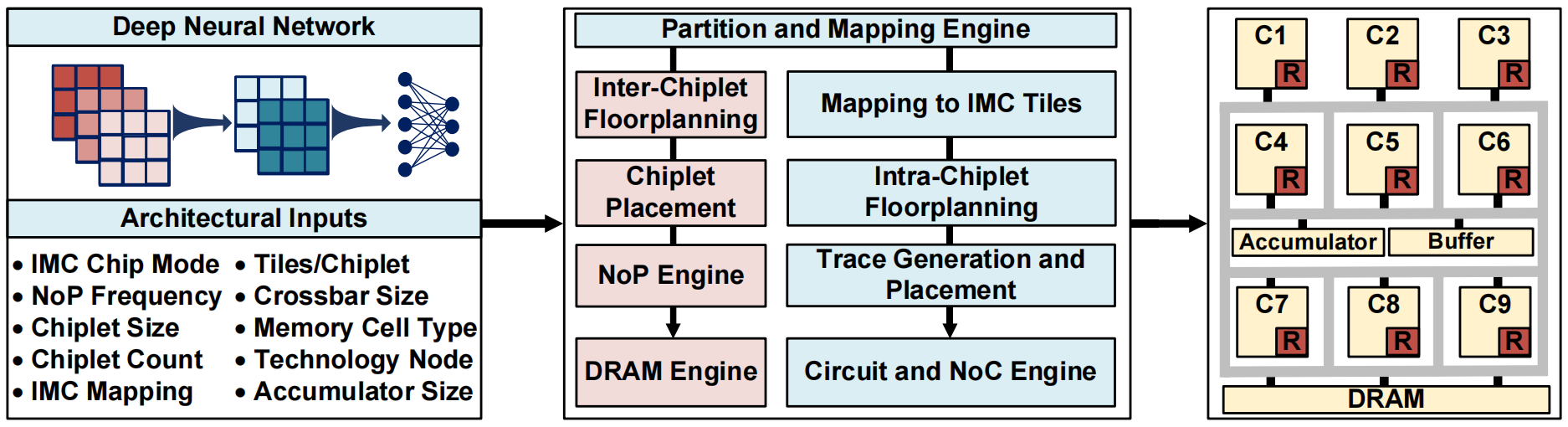
SIAM的输入包括
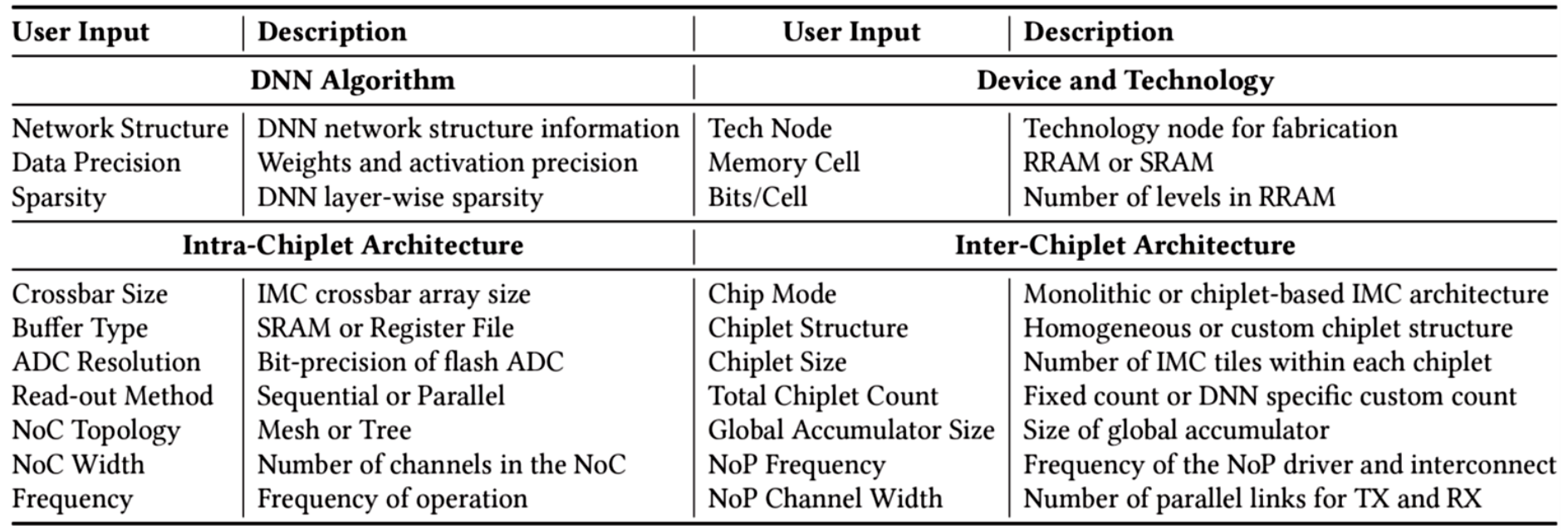
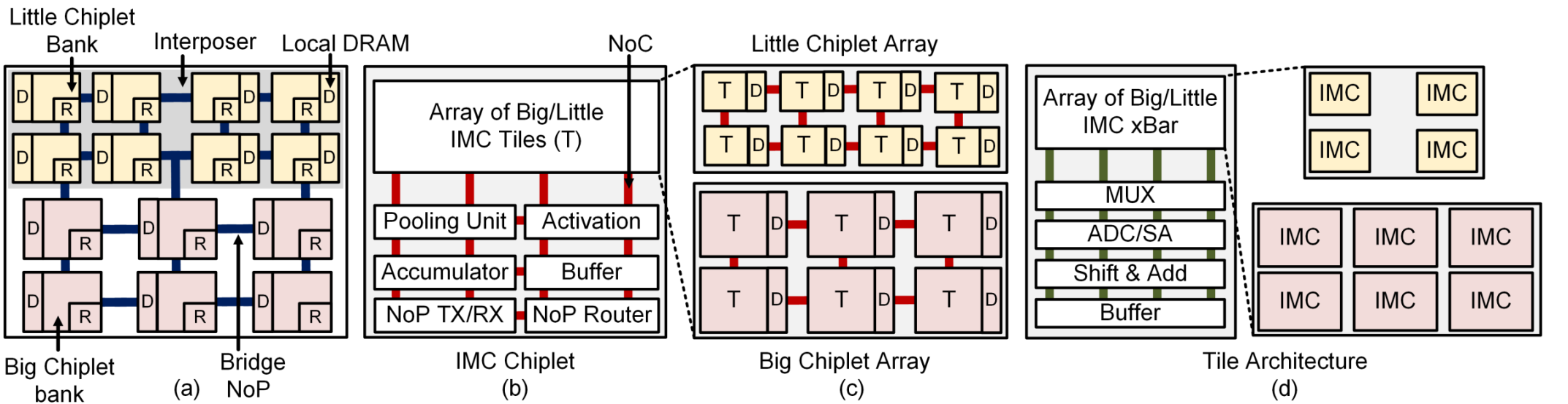
SIAM的计算架构如下:
组件颗粒可细化到具体的IMC cell,层次跨度较广。
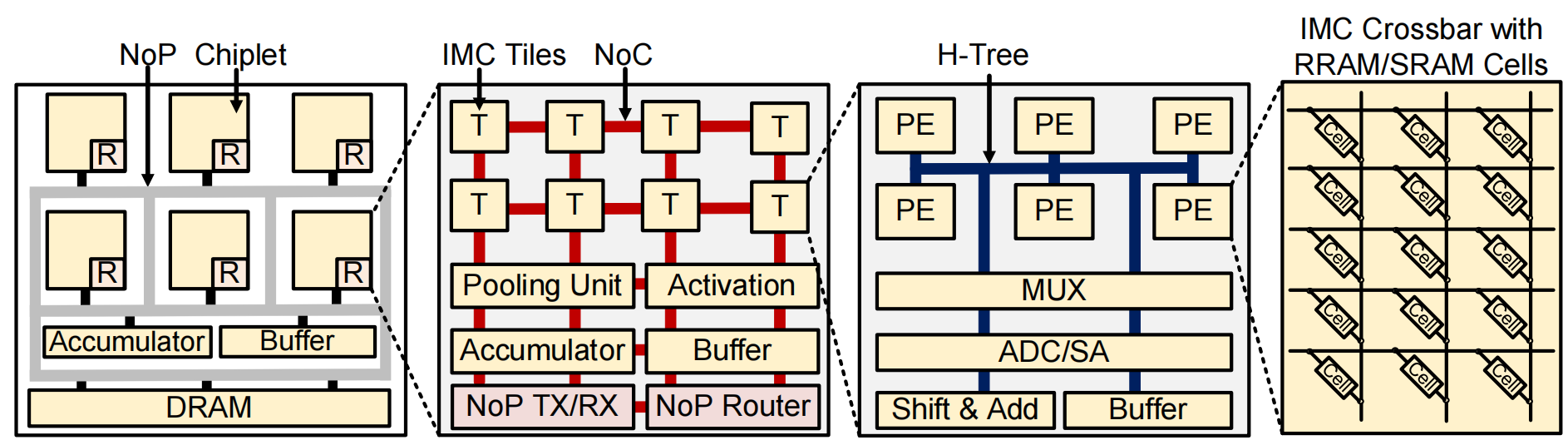
数据流
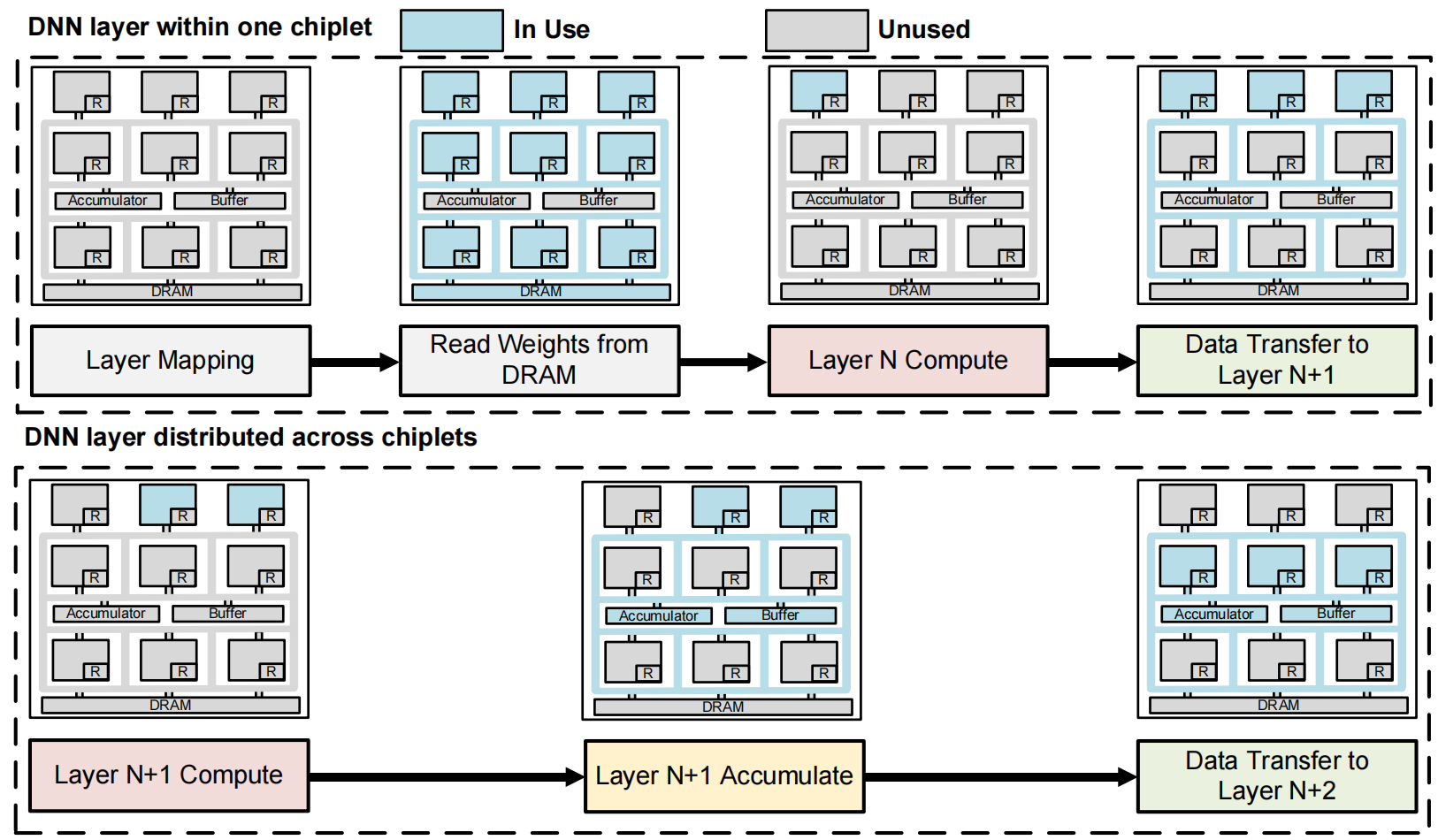
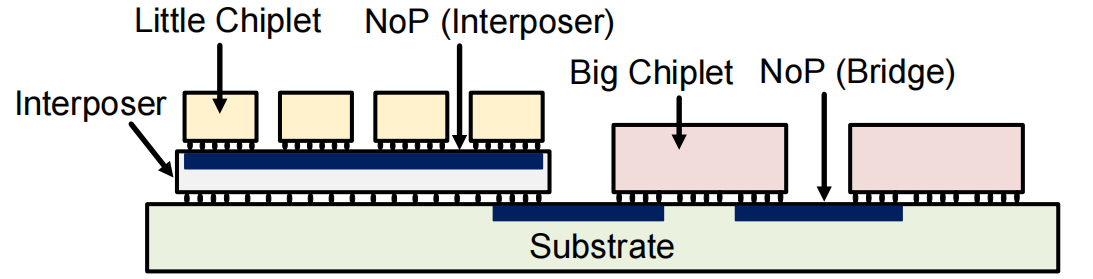
大小chiplet混合的架构
DNN网络的特征:固有的非线性权重和激活分布,这些给IMC的使用率带来了消极影响,导致需要更多的硬件资源和功耗,也影响了整体系统的成本。
算法映射指在最大化IMC的使用率
集成较小IMC的小芯片群用于初始化或较小layer的计算,比较适合大数据迁移的场景;集成较大IMC的大芯片群用于更大更深的layer计算,比较适合小数据迁移的场景。
NoP用于将大数据传递到每个芯片群内。
同类型芯片相比
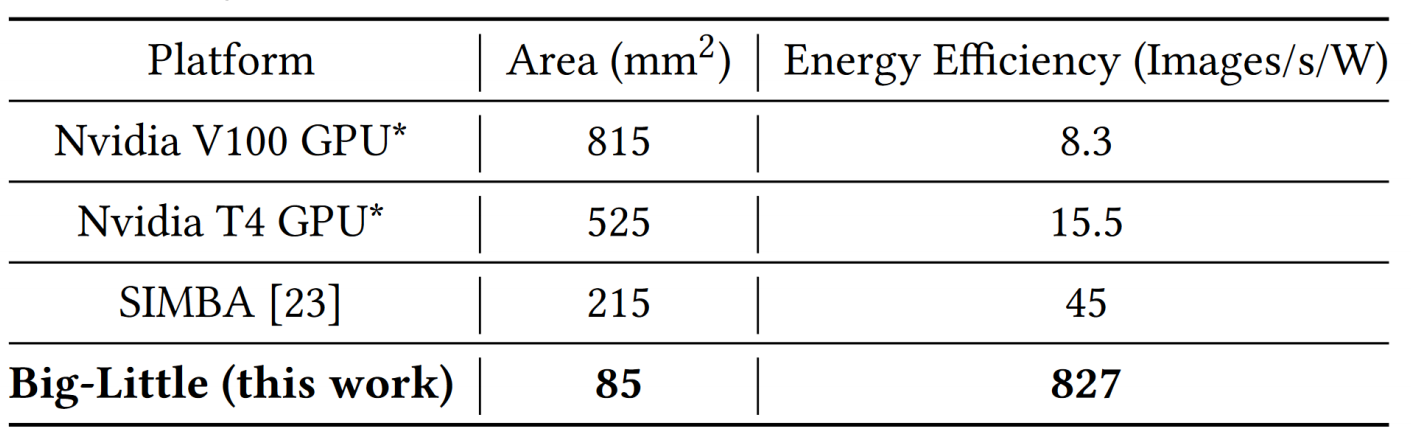
- 能效和面积
相关工作
- 评
用于DNN存内计算加速的异构chiplet架构。针对加速深度学习网络的计算,提出了一个新的chiplet架构——大小IMC核混合的异构,并就该架构构建了一套软件模拟环境SIAM,并集成了性能、面积评估工具。
该架构相对于GPU等加速器,该架构为 DNN 模型提升了10倍性能和~100倍的功耗效率。
Cost-Aware Exploration for Chiplet-Based Architecture with Advanced Packaging Technologies
Speaker: Tianqi Tang, Yuan Xie (@ University of California)
chiplet成本构成
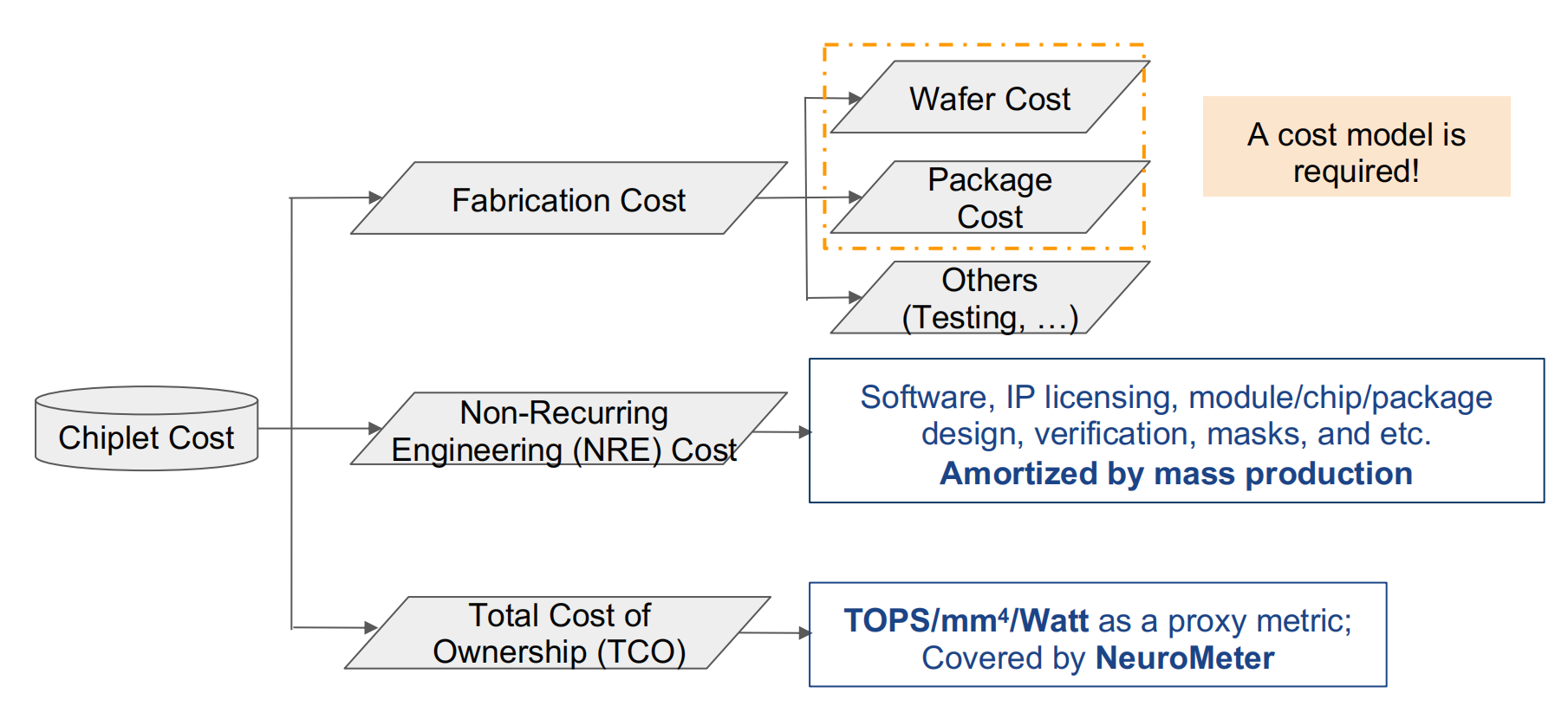
成本建模
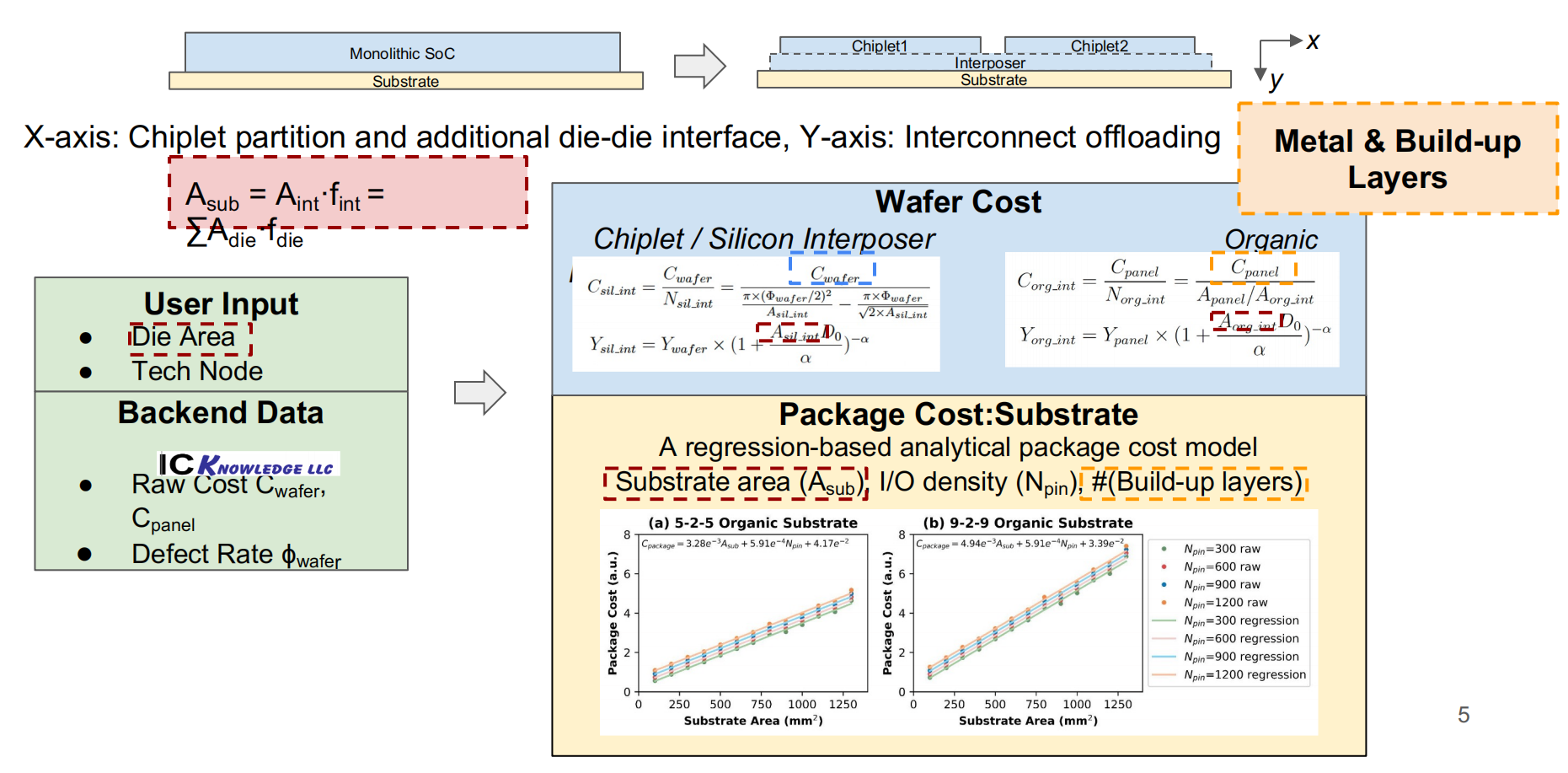
- 评
先进封装下的chiplet架构的成本探索。该报告对chiplet的制造成本构建了数学模型,并对同构和异构的chiplet系统进行了案例研究,chiplet在不同应用上成本各异。
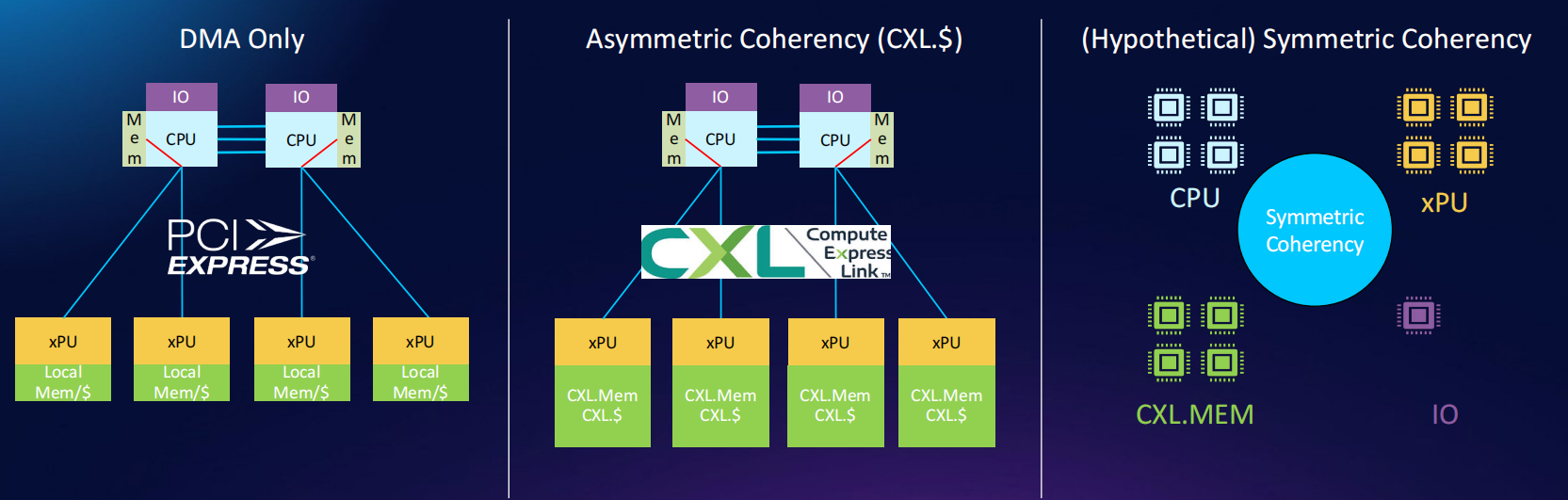
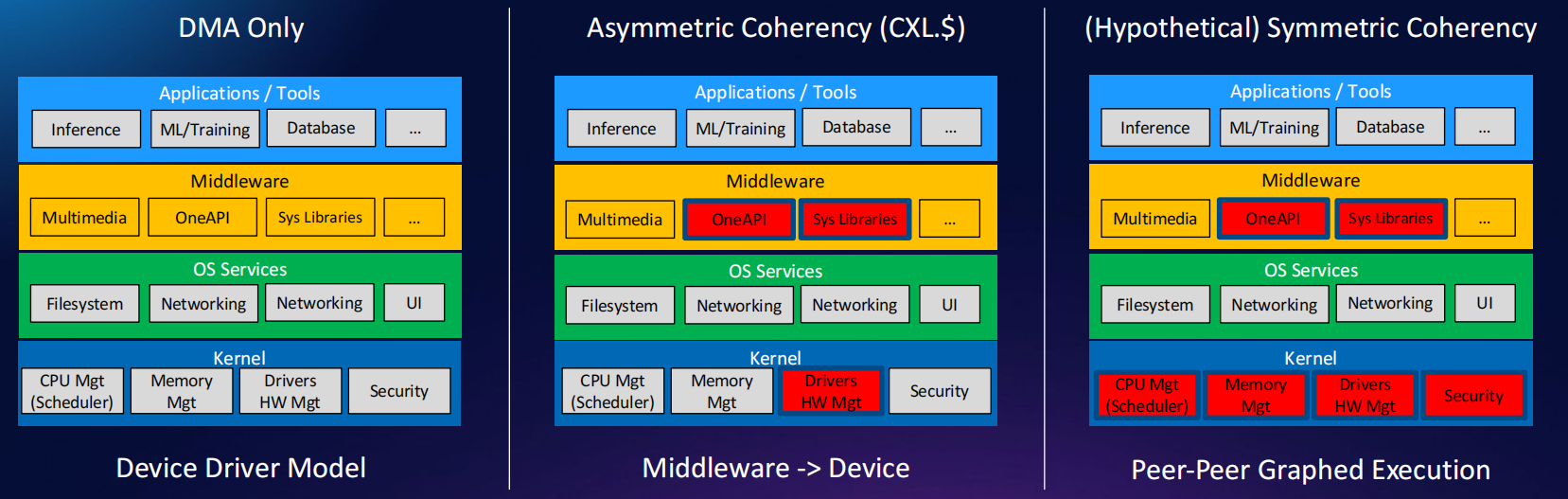
Redefining Computing Architecture Boundaries with Off Package Chiplets
Speaker: Allan Cantle (@ NALLASWAY)
封装内和封装外内存配置的架构性能对比
- 传统的本地内存和RDMA

- 通过CXL互联的共享内存

- 通过共封装光学技术连接的共享CXL内存

- 通过OIF-VSR的chiplet接口连接的本地内存

- 共封装光学、CXL共享内存、本地内存、OIF-VSR接口互联

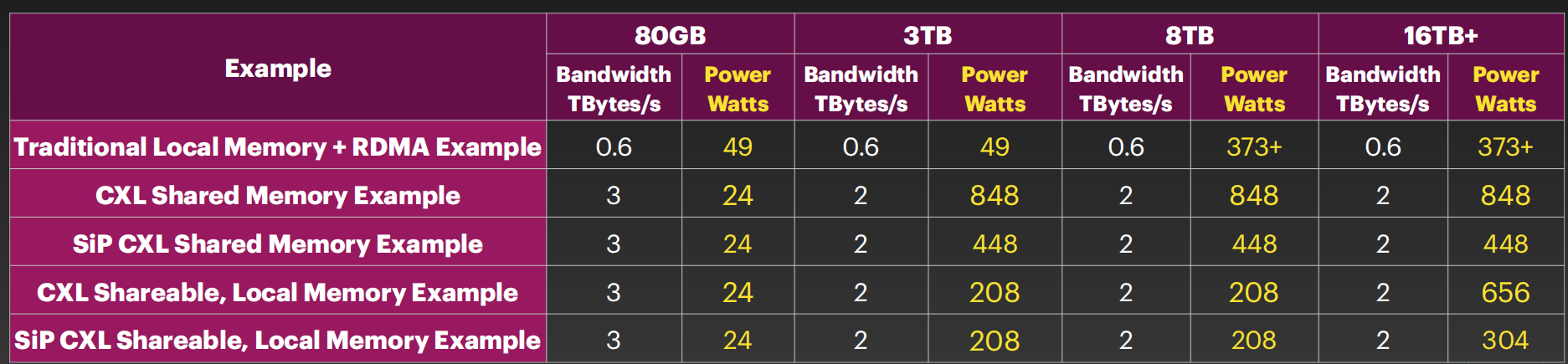
通过对比,可得到如下结论:
- 硅光互联的架构功耗更低
目标的chiplet架构
- on-package架构
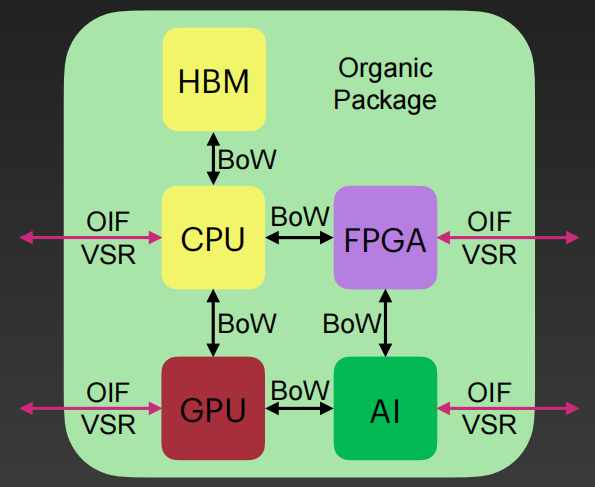
- off-package架构
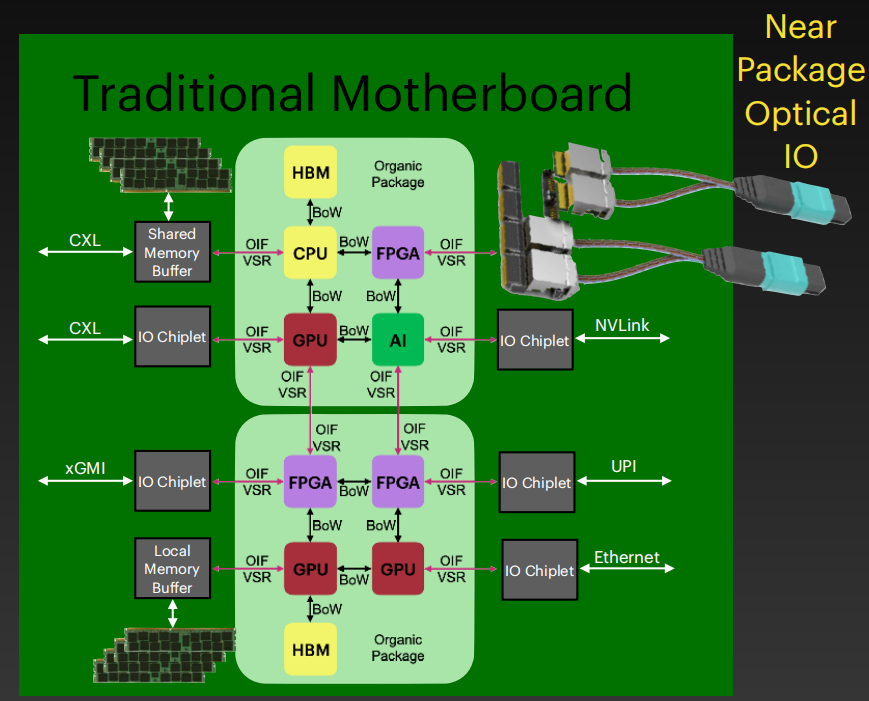
- 评
用封装外的chiplets重新定义计算架构边界。改报告通过几种封装内和封装外组合的架构性能和功耗对比,提出了未来目标的架构必定是on-package和off-package混合的架构。
芯片封装议题
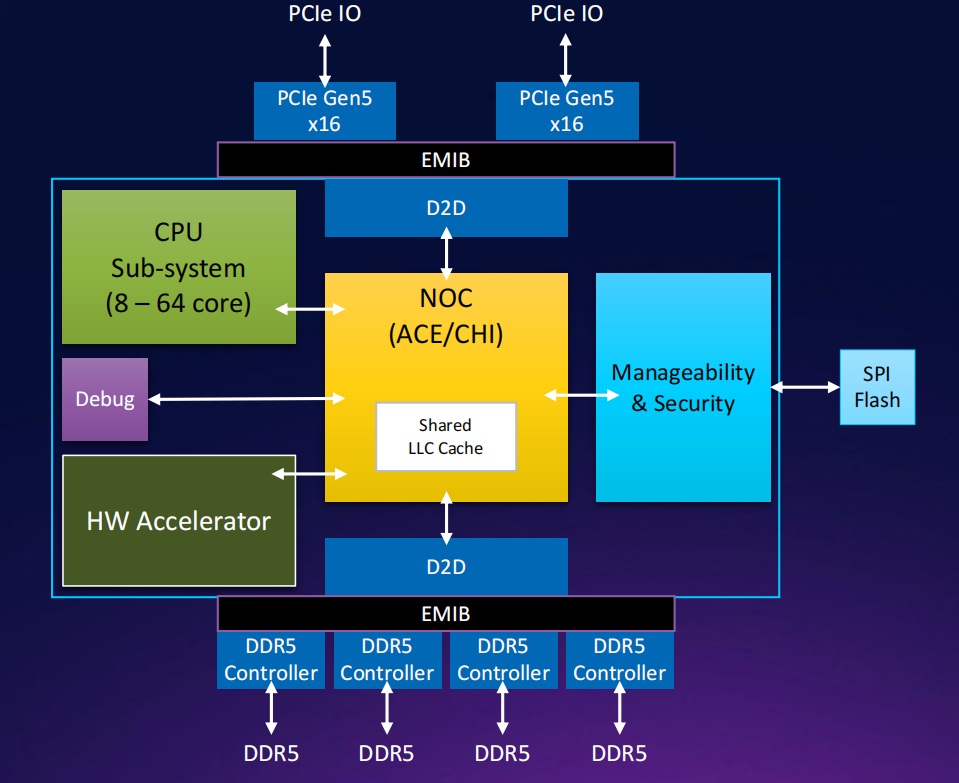
AI & HPC system opportunity with integrated photonics chiplets
Speaker: Edi Roytman, Ajaya Durg, Thomas Liljeberg, Ling Liao, Robert Munoz (all @ Intel Corporation)
从HBM/DDR的特征到AI/HPC节点的理想系统内存
- 所有的计算、通信类型可直接访问
- 模块化、可组合的、可扩展的
- 共享的、可池化的
- 类似HBM的带宽
- 类似DDR的容量、延迟、ECC校验
- LPDDR的功效
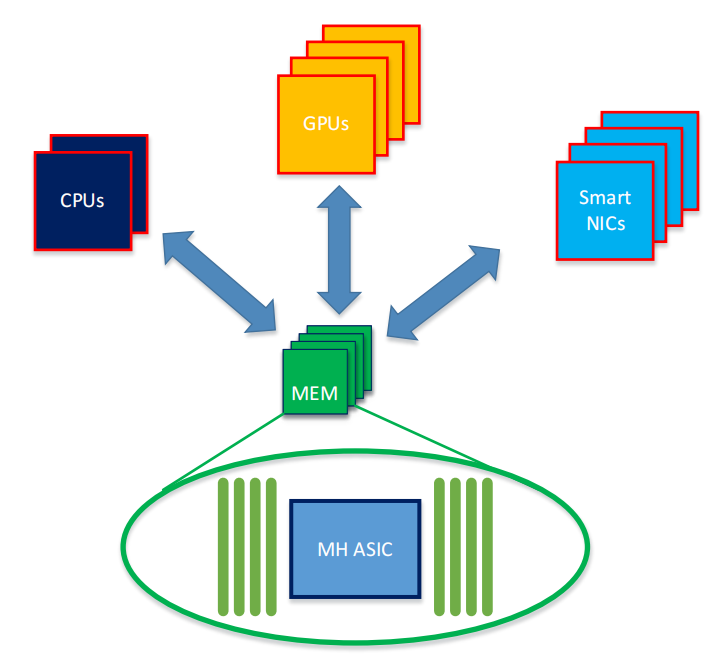
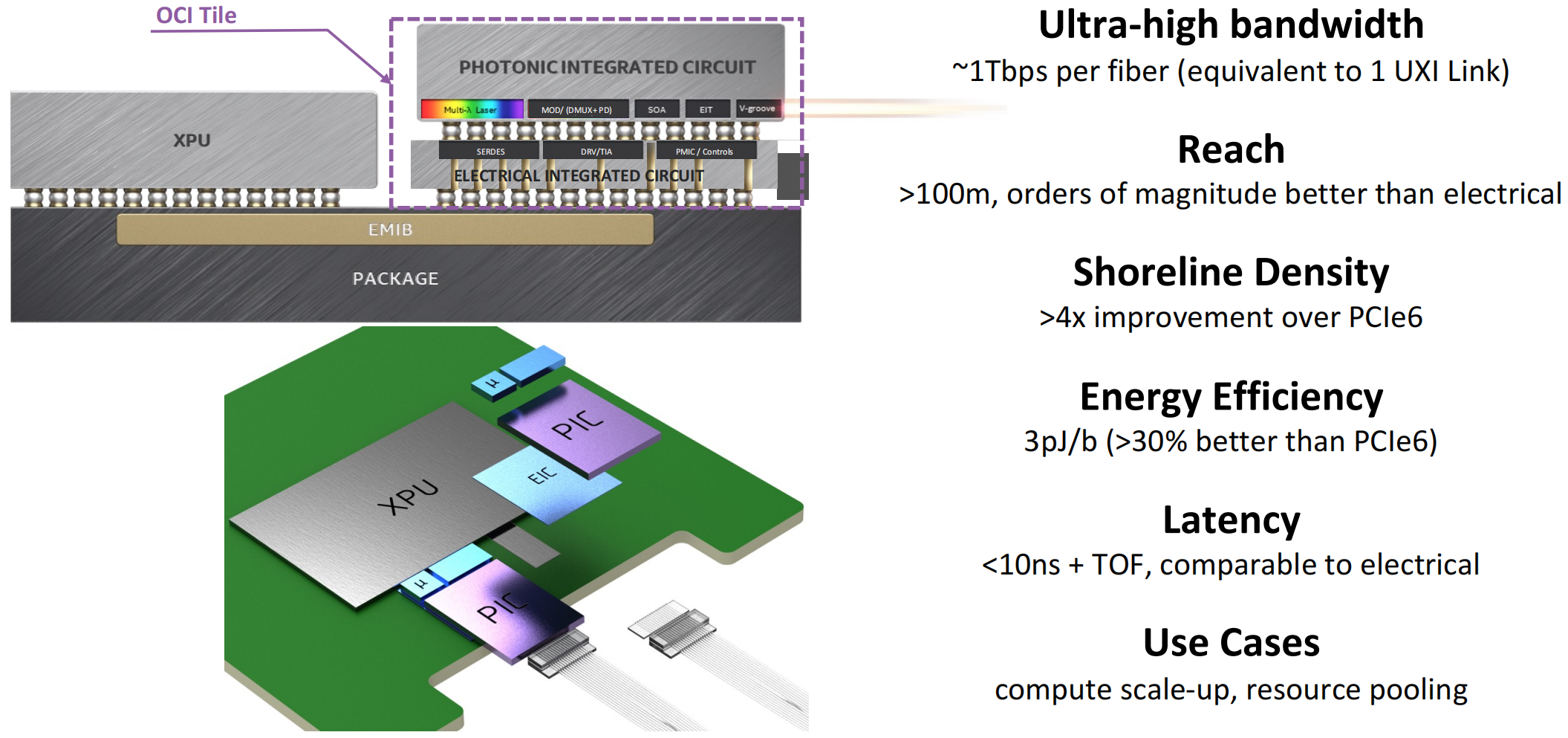
Intel的光计算互联解决方案
光模块集成芯片及封装示意图:
内存访问架构图:
直接内存访问 ----》 共节点的内存 ----》共享/池化的内存和IO设备
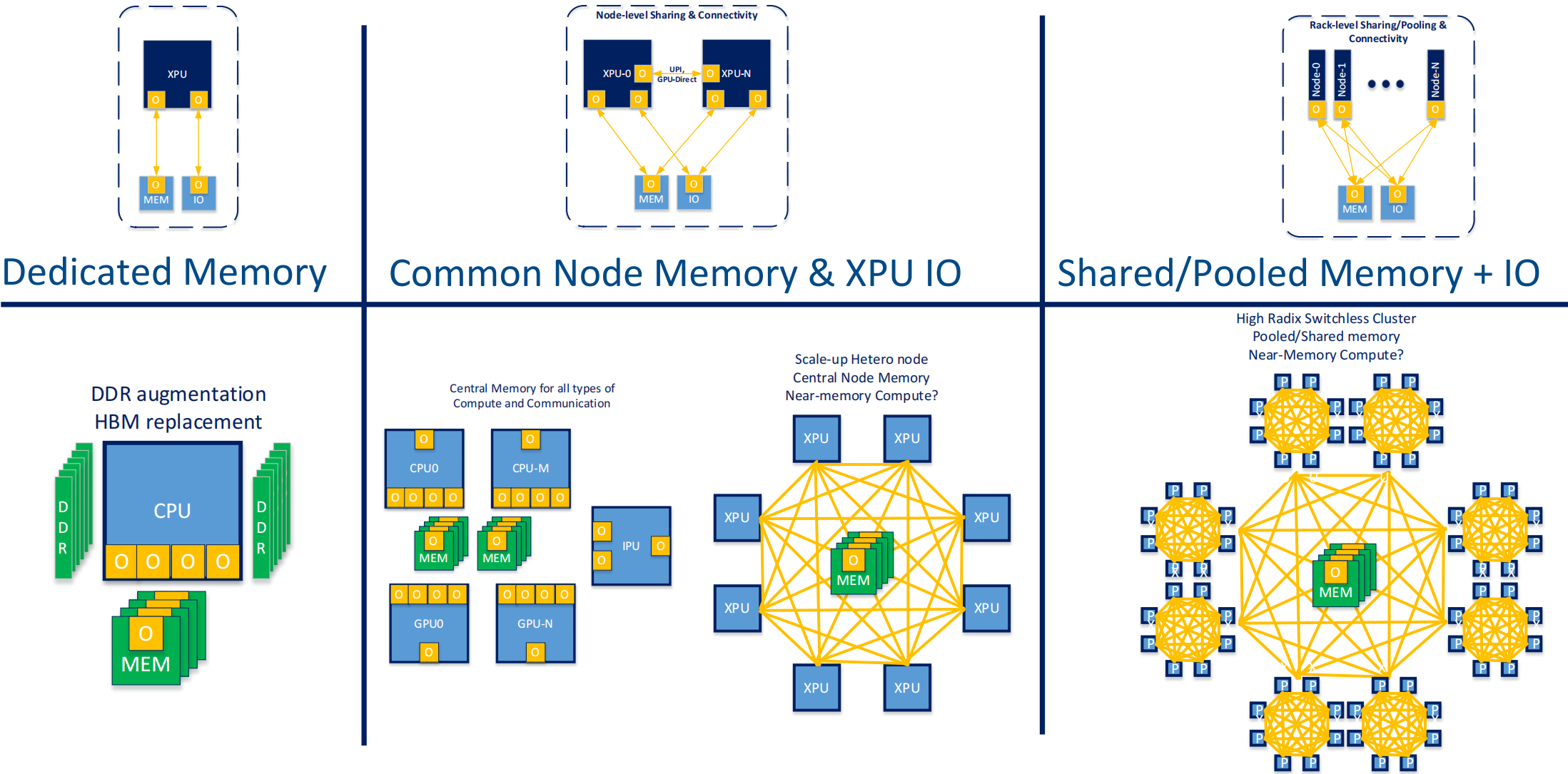
先进的内存架构可以获得更好的性能
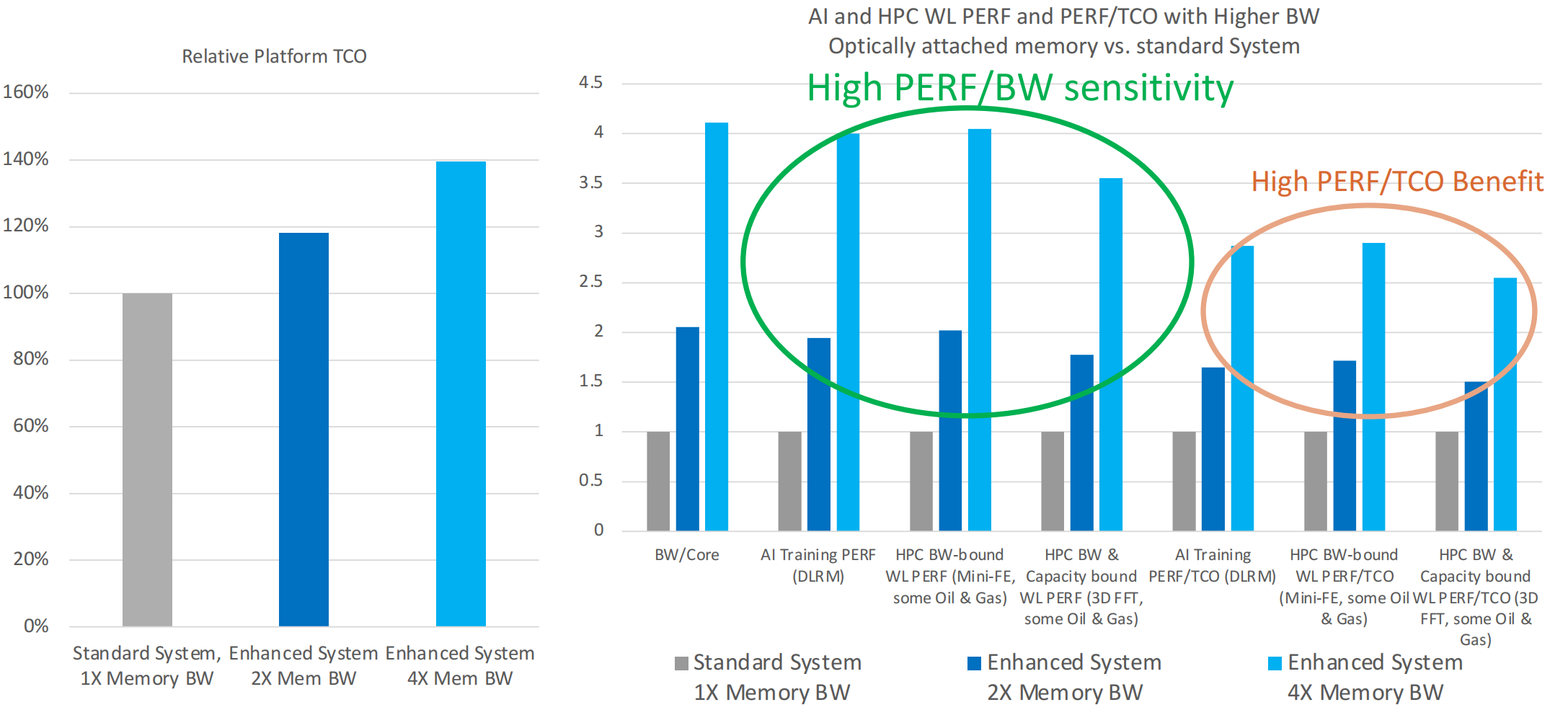
是否应该使用光互联技术
光互联技术在计算节点较多,功耗较大的场景需求更大。
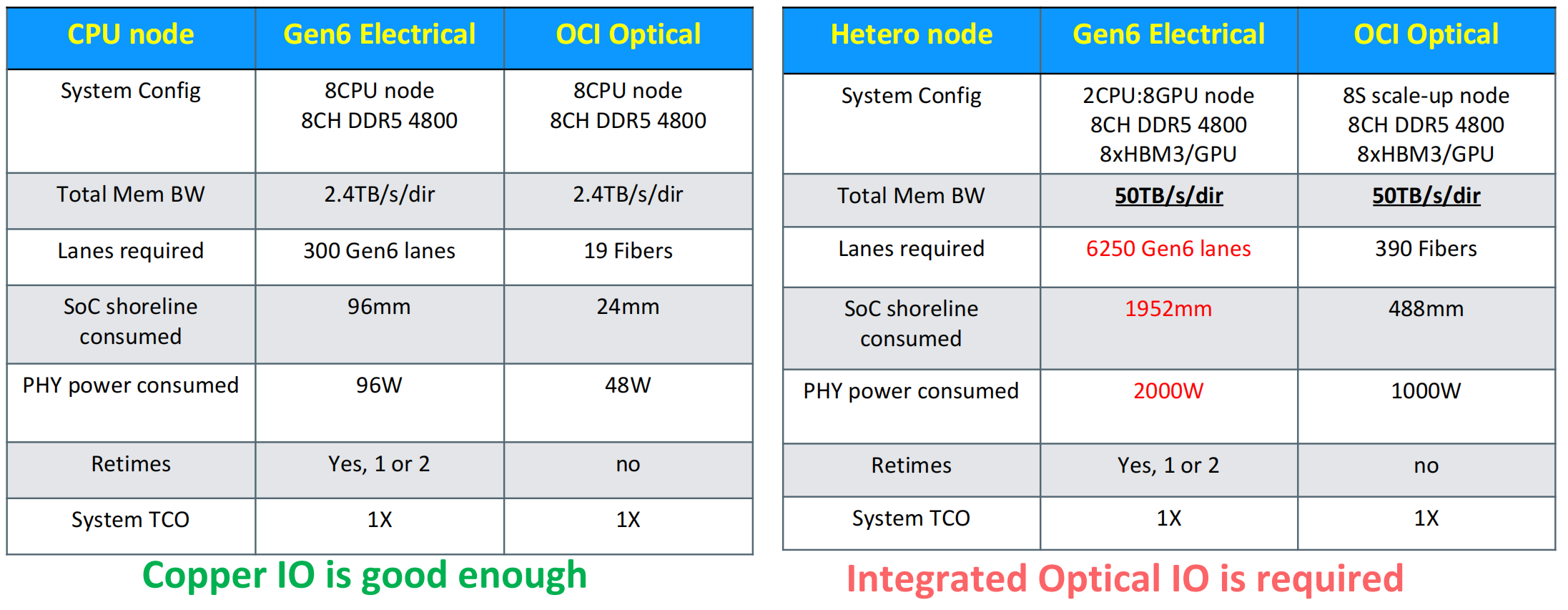
- 评
集成光连接chiplet的AI和HPC机会。该报告强调了光连接的高带宽和大容量的内存架构可以在达到5倍性能,在同一成本下达到2-3倍的性能提升,为此需要在AI/HPC工作负载敏感性研究和光互联参考设计方面进行研究,联合产业界开发适用于XPU和光互联接口的强互操作性、可用的chiplet接口标准。
Glass Interposer Integration of Logic and Memory Chiplets: PPA and Power/Signal Integrity Benefits
Speaker:
Pruek Vanna-iampikul, Serhat Erdogan, Mohanalingam Kathaperumal, Madhavan Swaminathan, and Sung Kyu Lim(@ Georgia Institute of Technology)
Ram Gupta, Ravi Agarwal, (@ Meta)
Praveen Anmula, Kevin Reinbold,(@ Siemens)
一种非TSV的3D堆叠封装方式
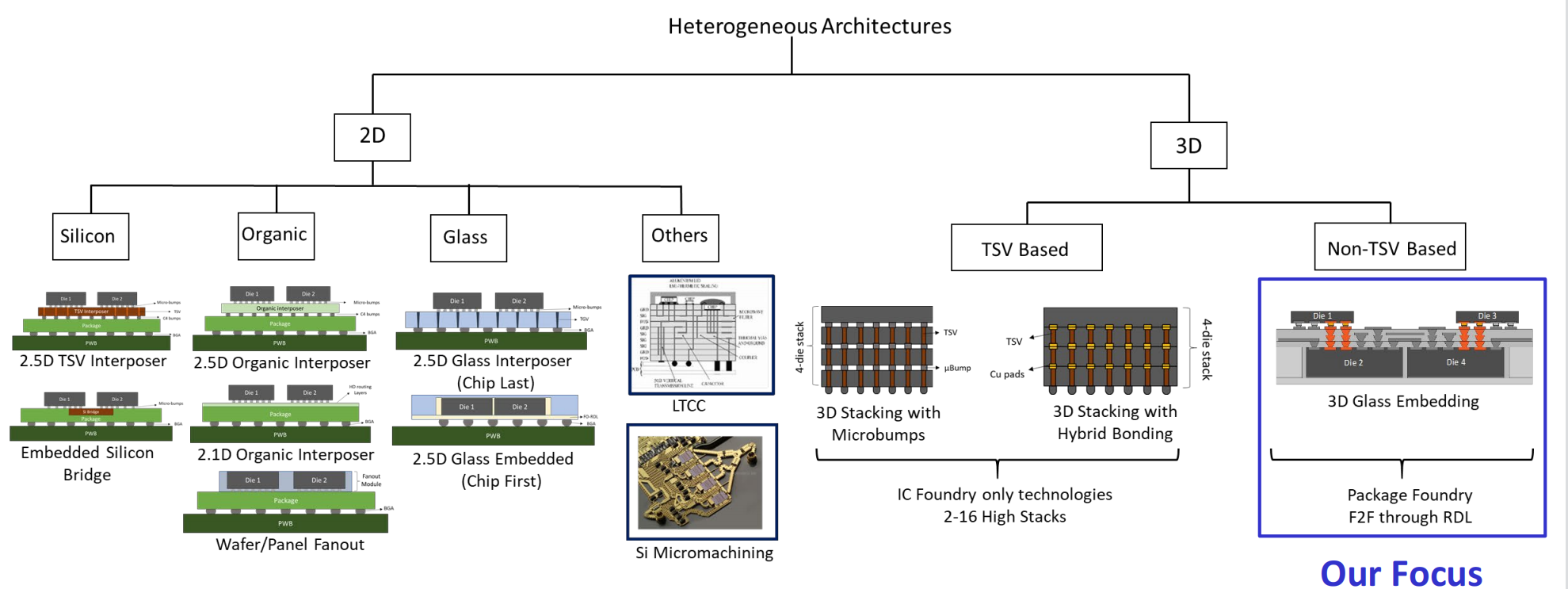
footprint、PPA+SI/PI对比
更小的footprint。
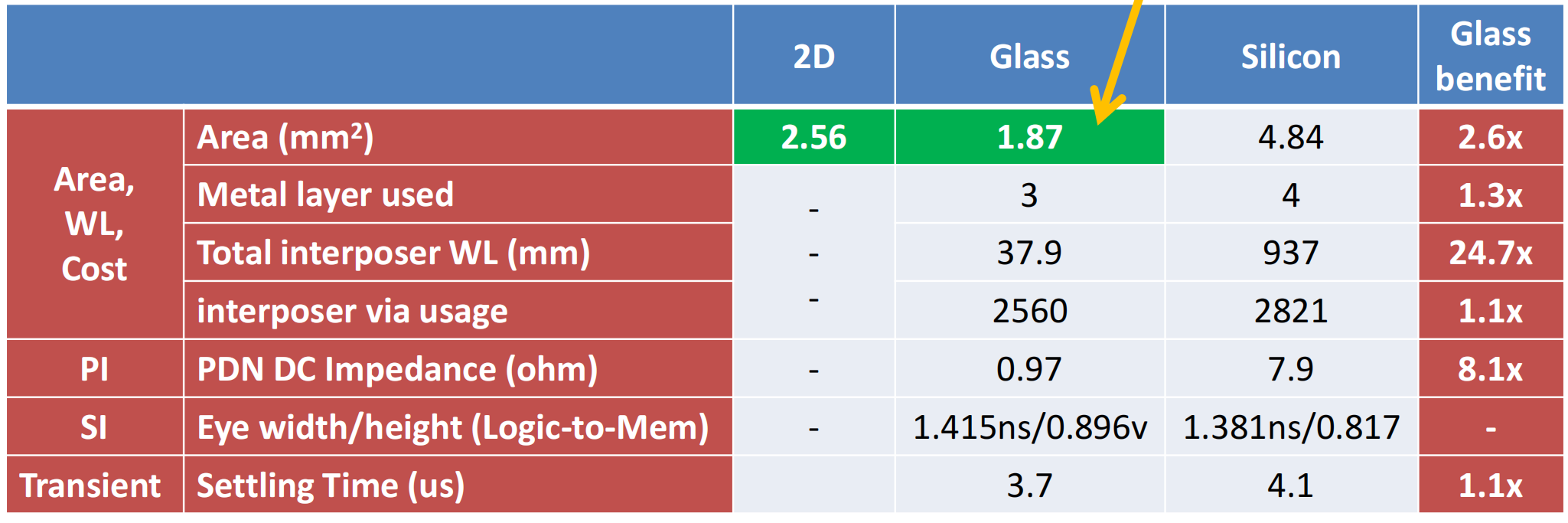
- 评
逻辑和存储chiplet的glass中间介质层的PPA和功耗/信号完整性的优势。GLass中阶层是2.5D和3D封装的一种新的中介介质层材料,通过Glass和Silicon的性能对比,Glass可支持在3D chiplet堆叠的成本更低的解决方案,在PPA和Si/PI方面也有更好的表现。
Chiplets’ march to AMD 3D V-Cache And Beyond
- Speaker:RAJA SWAMINATHAN, JOHN WUU( @AMD Senior Fellow)
- 评
通往AMD 3D Vcache的chiplet之路。AMD Zen3 CPU利用小芯片扩展了L3 V-Cache,从32MB到(32MB+64MB),总体实现了15% 性能提升
芯片测试议题
Using In-Chip Monitoring and Deep Data Analytics for High Bandwidth Die-toDie Reliability
- Speaker: Alex Burlak (VP Test & Analytics @proteanTecs)
异构集成面临着质量和可靠性的挑战

- 评
为高带宽的D2D可靠性进行片内检测和深度数据分析。该报告主要介绍了proteanTecs公司在lane的高分辨率检测、从产品到良率的可视化、先进的特征检测、以及覆盖率驱动的测试优化等方面的工作。
CHiplet接口协议议题
What is the right Die-to-Die Interface? A Comparison Study
-
Speaker: Shahab Ardalan (LMNS), Bapi Vinnikota (BRCM), Tawfik Arabi (AMD), Elad Alon (BCA)
-
评
一种判断D2D接口的比较研究。本报告图片多,但信息较少,初步看出可治是根据单向和双向链路的功效和延迟的分析,得出能效和延迟是很重要的结论。
OCP ODSA’s Bunch of Wire (BoW) Interface for Die to Die Applications
Speaker: Elad Alon (@ Blue Cheetah Analog Design) Bapi Vinnakota (@ Broadcom) Jayaprakash Balachandran (@ Cisco)
BoW是用于D2D并行接口的物理层标准协议
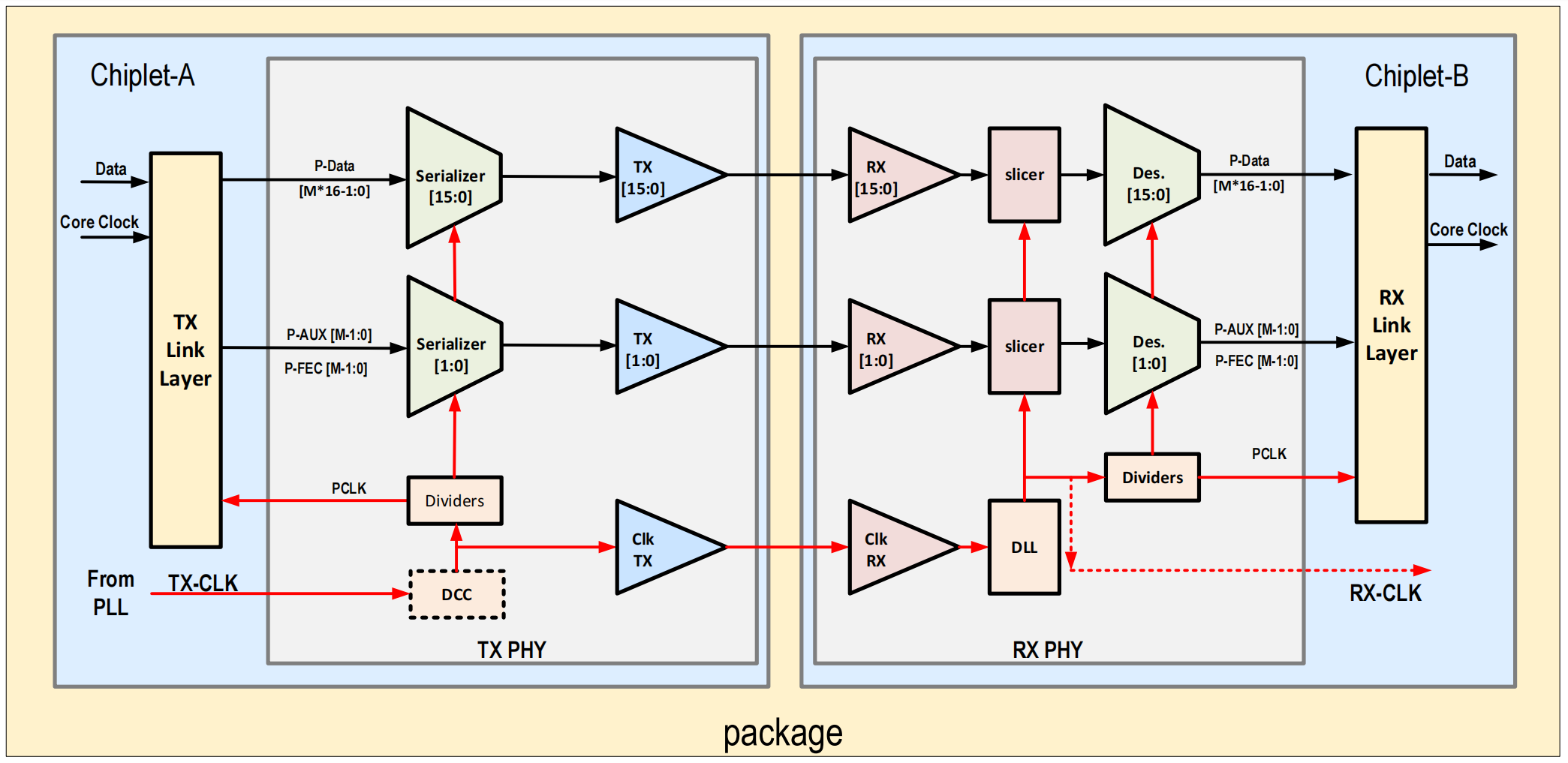
- 评
用于D2D应用场景的BoW接口。本报告相当远ODSA的BoW宣传报告,介绍了BoW在低延迟、时序设计、封装的高互操作性和灵活性、RX/TX通道信号的兼容性等方面的优势,呼吁产业界一起为BoW生态做贡献。
ODSA: Creating Open chiplet ecosystem under open compute project
Speaker: Dharmesh Jani (Open Ecosystem Lead @ Meta, Co-Chair OCP Incubation Committee)
DSA时代的来临
2018年John Hennessy 和 David Patterson预测了DSA时代的来临
ODSA的职责
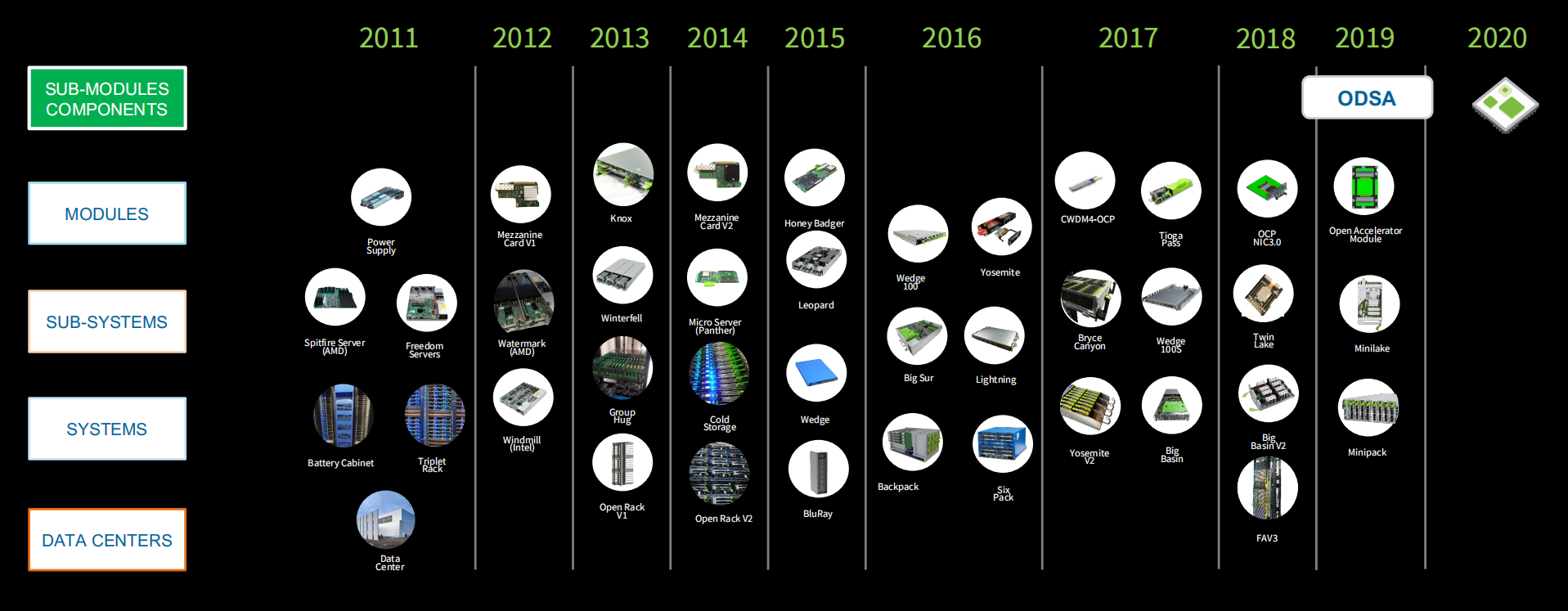
OCP主要在模块级、子系统级、系统级、数据中心展开布局,2019年起将通过ODSA在模块级组件开展工作
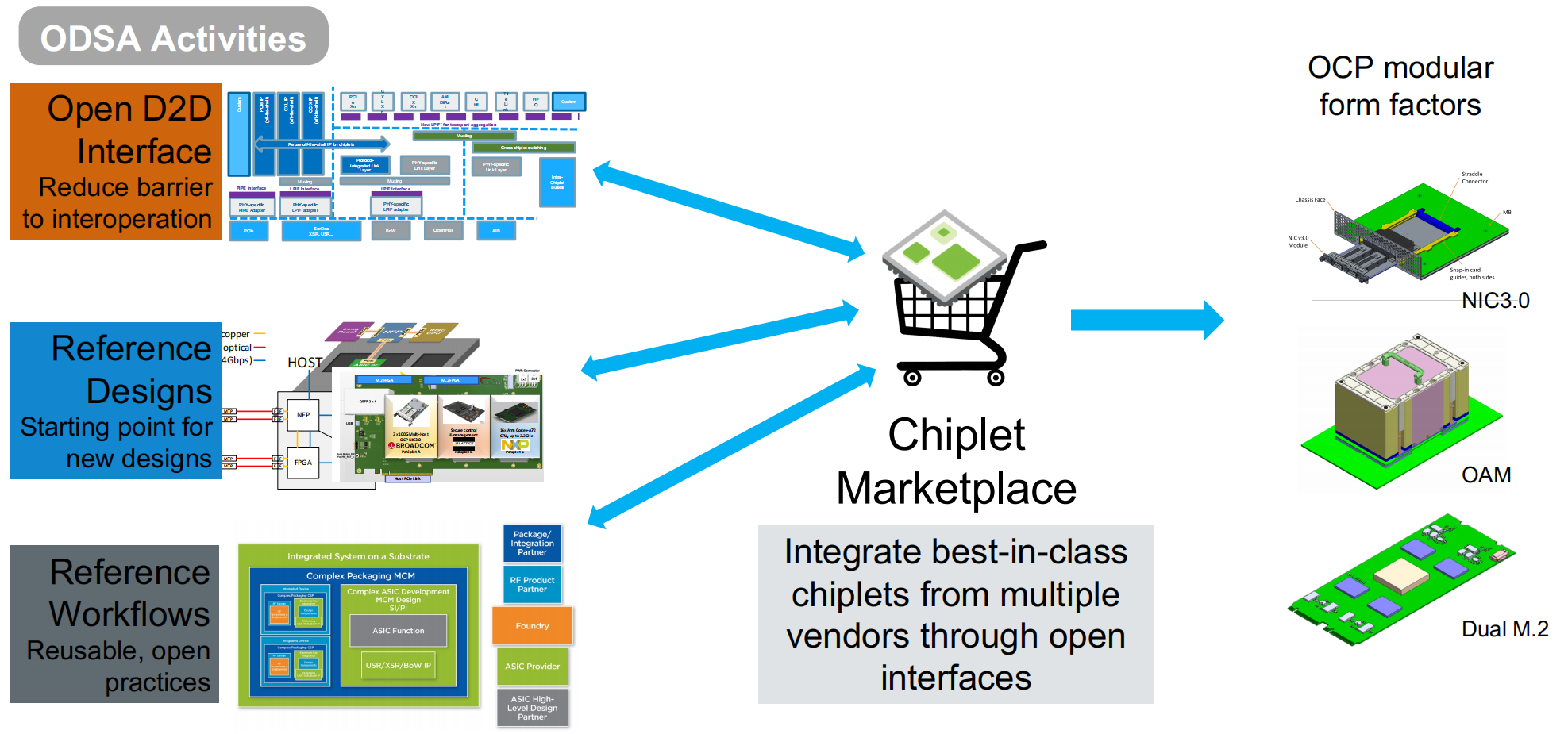
 ODSA将在开放的D2D接口、chiplet参考设计、参考工作流三方面工作推动chiplet市场生态的构建,进而OCP其他业务的发展。
ODSA将在开放的D2D接口、chiplet参考设计、参考工作流三方面工作推动chiplet市场生态的构建,进而OCP其他业务的发展。
ODSA的技术栈
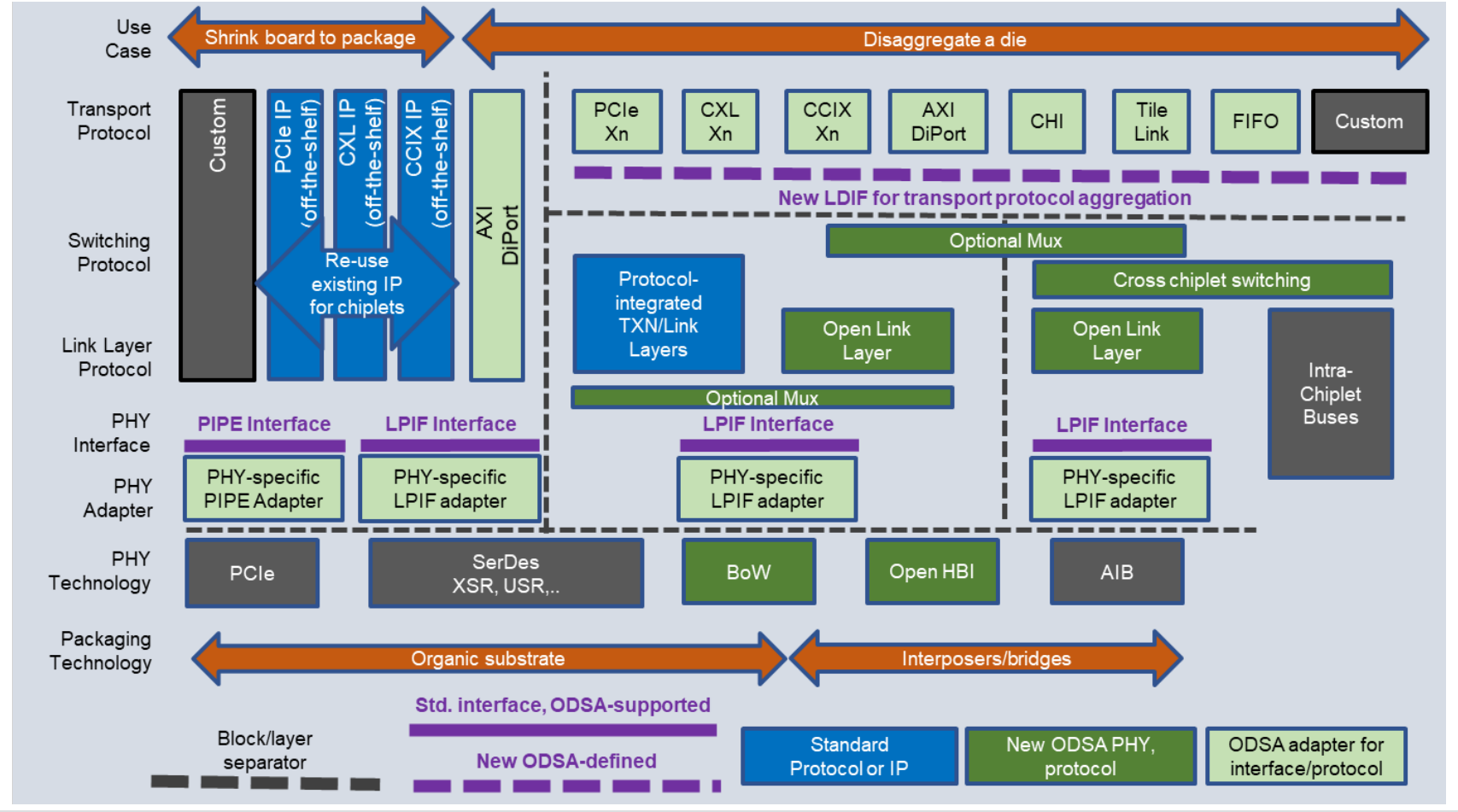
- 评
ODSA,在OCP组织下构建chiplet生态。该报告介绍了OCP组织下的ODSA下属机构,目的在于构建开放的chiplet系统芯片生态,并介绍了ODSA在进行的工作,包括chiplet封装技术、接口协议技术、使用案例等工作。
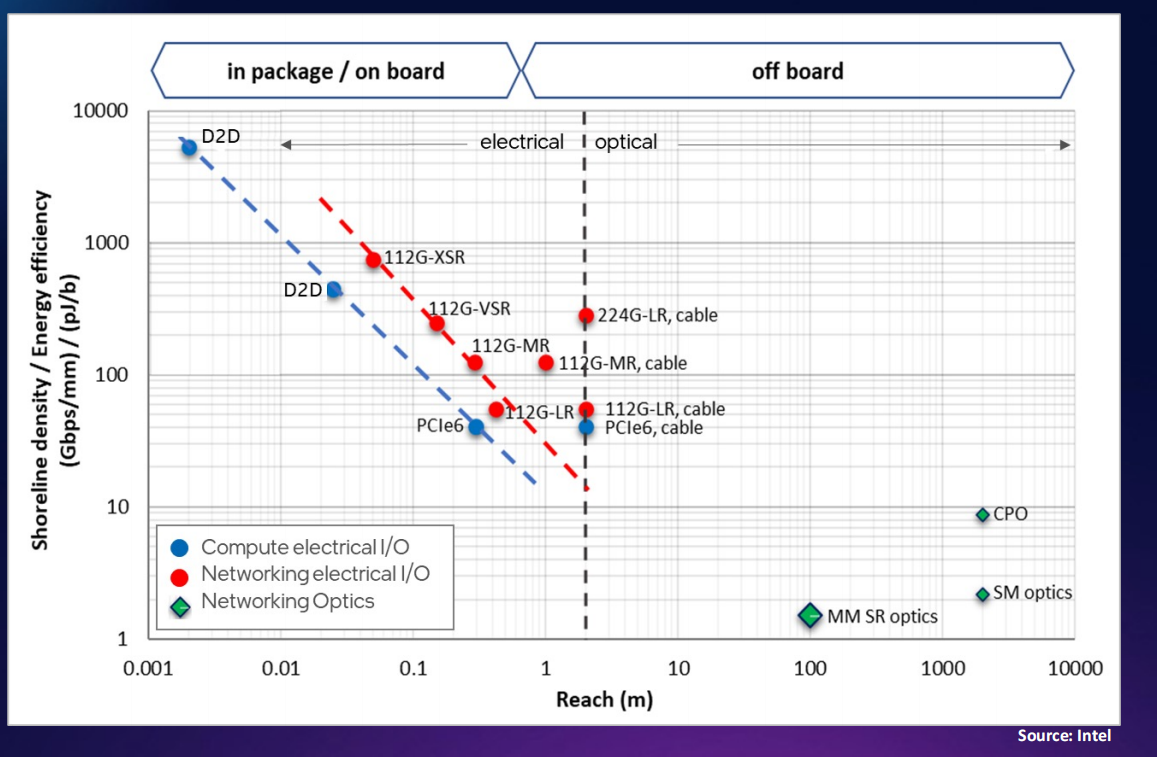
High-Bandwidth Density, Energy-Efficient, Short-Reach Signaling that Enables Massively Scalable Parallelism
Speaker: John Wilson ( Nivida )
计算架构升级的目标:每watt增加的计算性能
封装外带宽的演变:
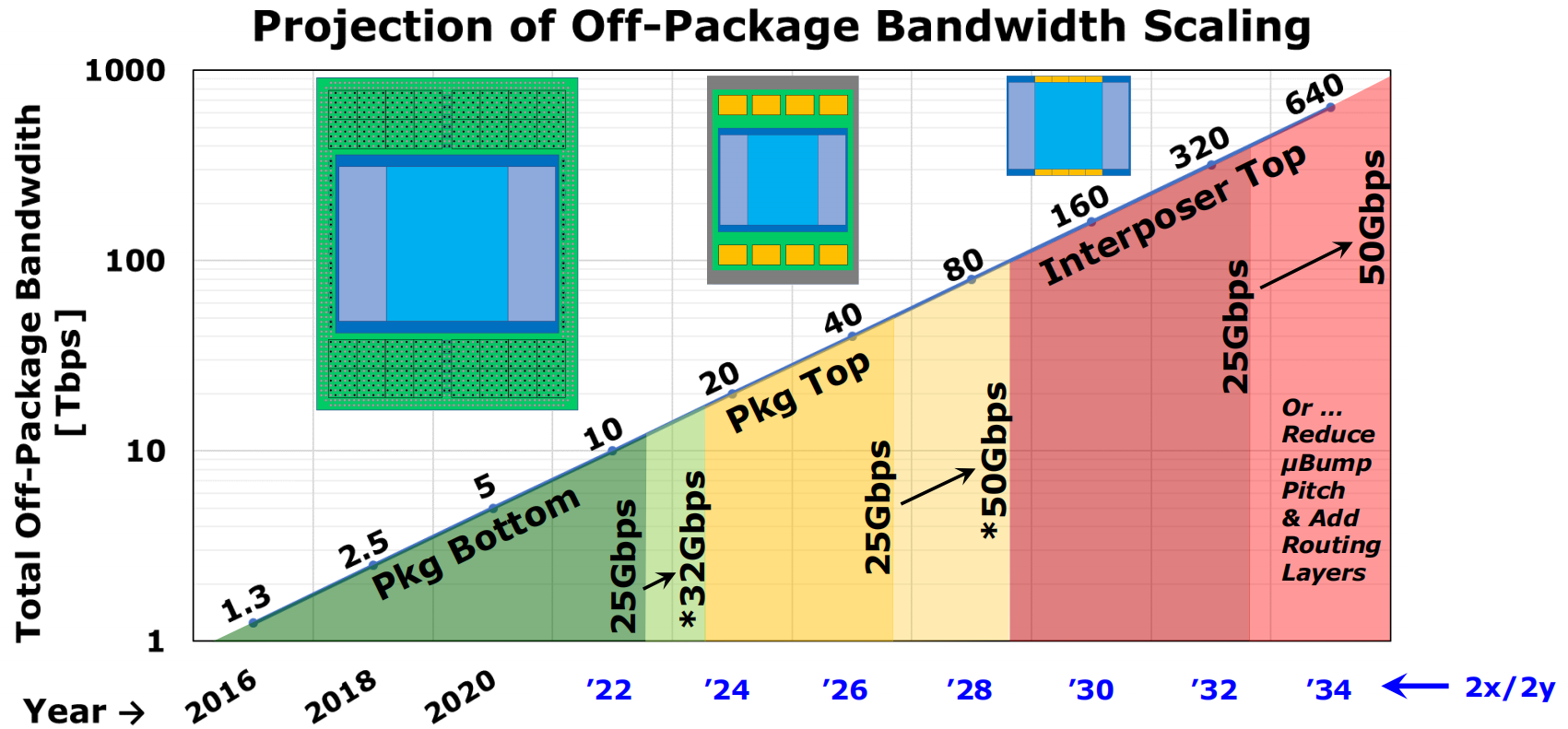
- 评
能够大规模并行标量计算的高带宽密度、能效、短距的信号输出。从工艺角度讨论了off-chip和off-package的带宽极限,对于接口PHY的设计,提出了大量数据传输场景下提高的chip-to-chip传输带宽的单端信号的输出方法,提出了在organic封装和PCB层级的方法 Ground-Referenced Signaling,在interposer层级使用Simultaneous Bidirectional Signaling;也说明了2.5D封装的chip-to-chip大带宽传输仍然存在数据传输功耗过大的挑战。
Dual-Stripline Configuration for Efficient Signal Routing in the Bunch-of-Wires Interface
Speaker:
Shekar Geedimatla, Robin James Payyappillil, Devi Sreekumar, and Shalabh Gupta Department of Electrical Engineering, IIT Bombay, Mumbai – 400076, INDIA
BoW标准可以在基板上支持高密度的信号互联
BoW的每个slice有16根信号,每根线提供16Gbps的传输带宽,一个slice最多提供256Gbps的带宽。
Dual stripline配置
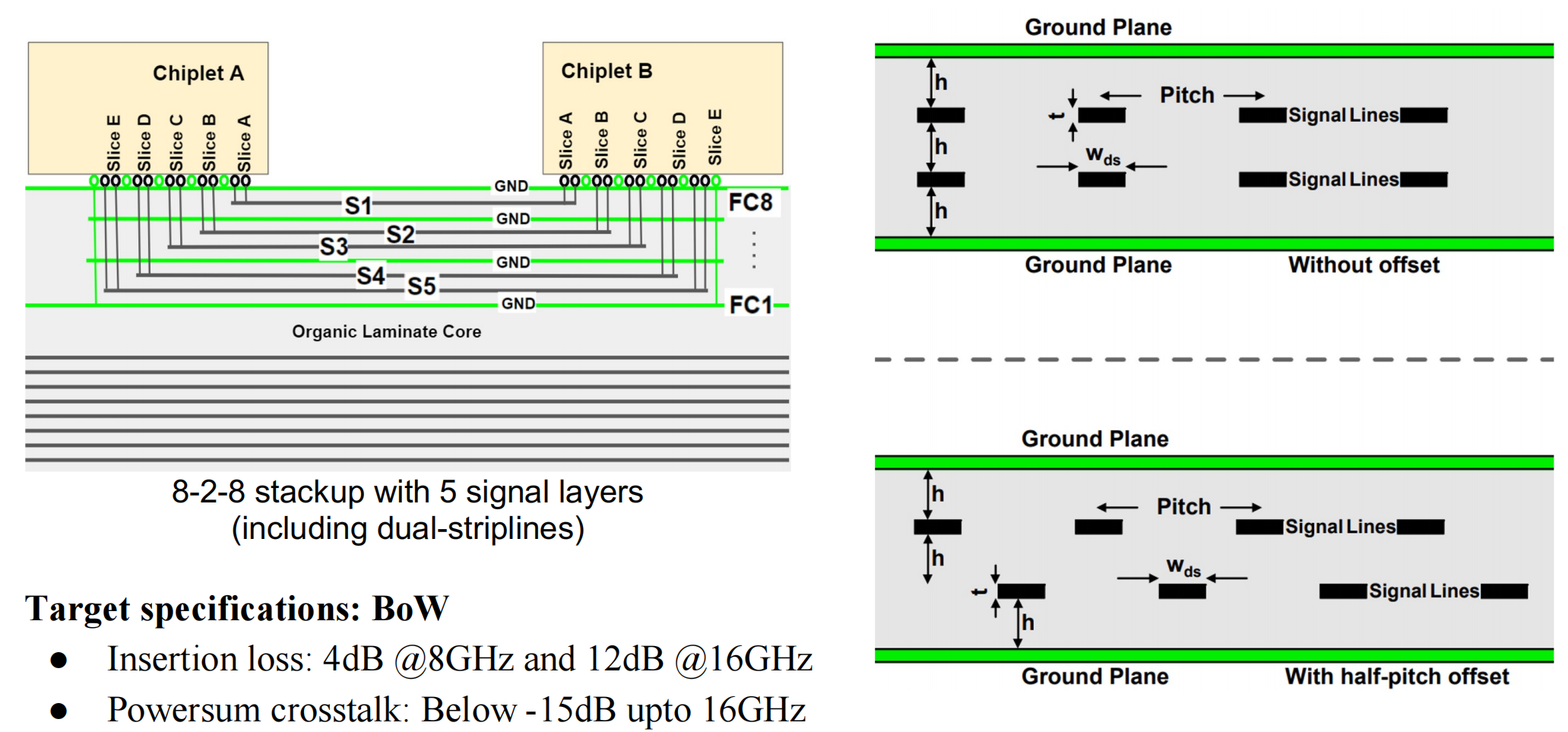
half-pitch offset可以减少信号串扰。
相关研究

- 评
基于BoW接口的双条纹配置的高效信号路由方法。通过封装时两个die间的走线优化(Dual-Stripline configuration)增加封装的走线密度,half-pitch偏移可以减少串扰影响,通过仿真结果表明眼图和串扰均符合要求。
Design Space for Chiplet IO
Speaker: Ken Chang, Scott Huss (@ Cadence)
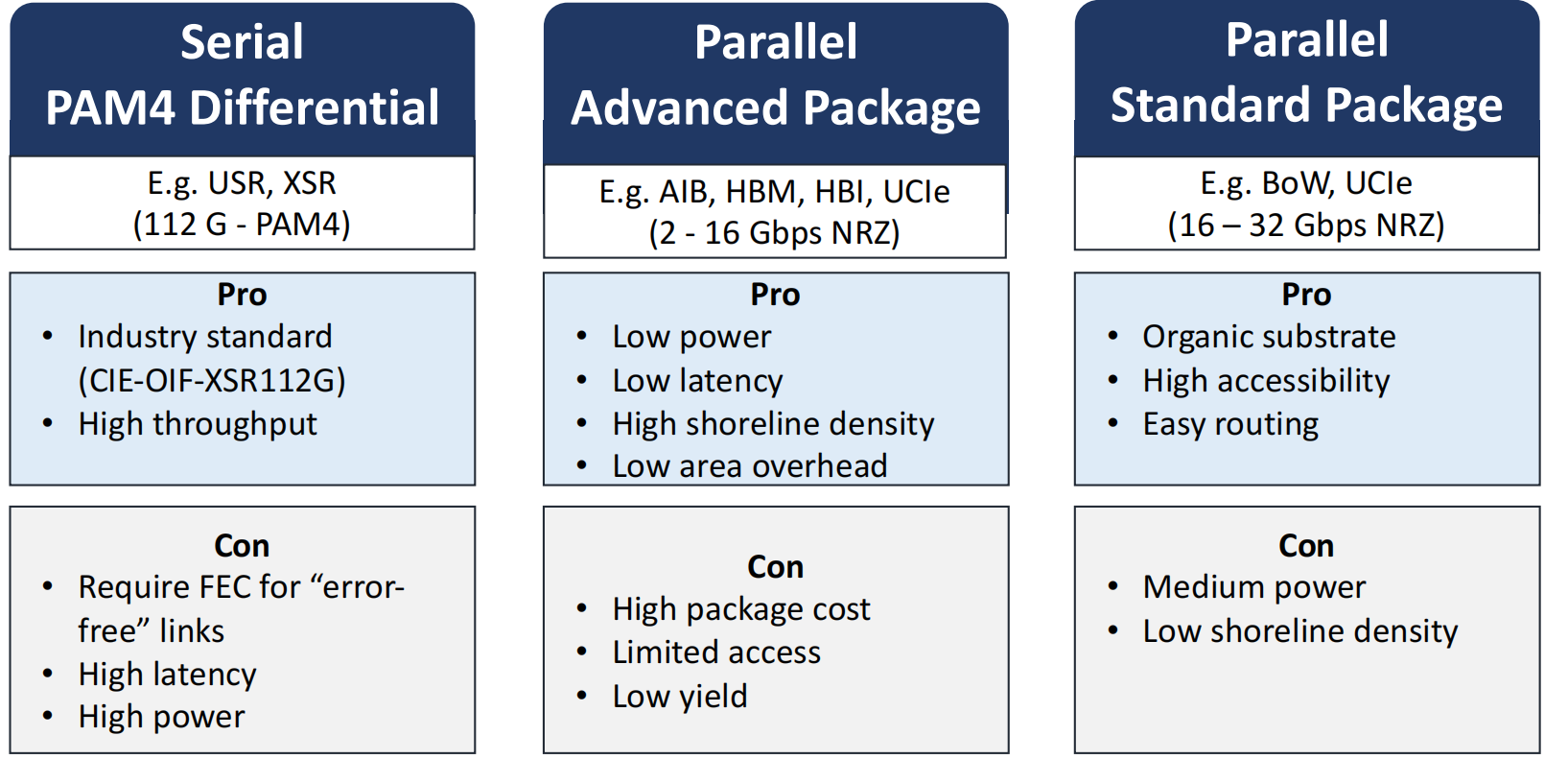
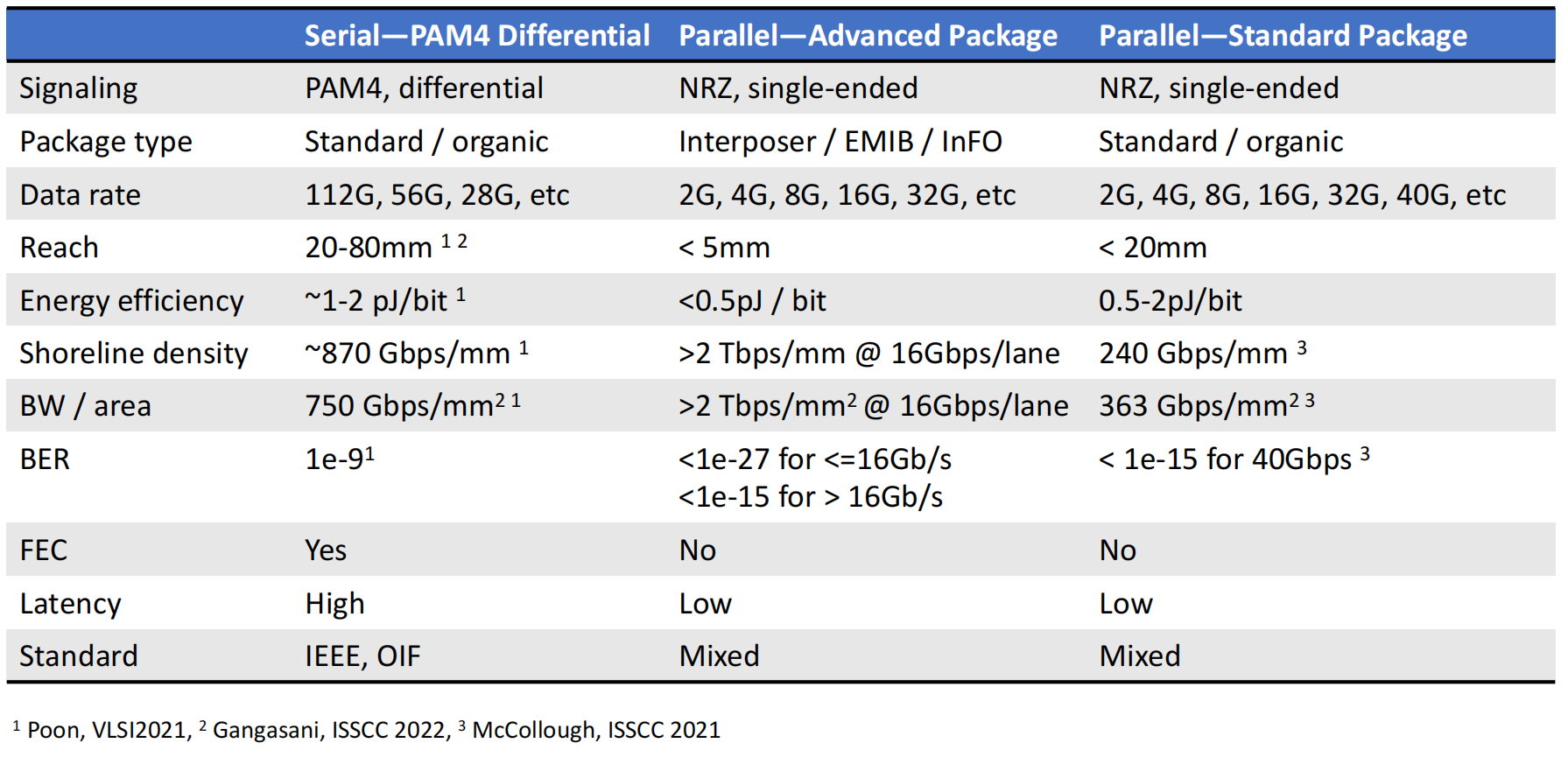
chiplet IO类型分类
相对串行PAM4差分信号和并行接口先进封装,并行接口标准封装在能效和带宽密度两方面有折中的效果。
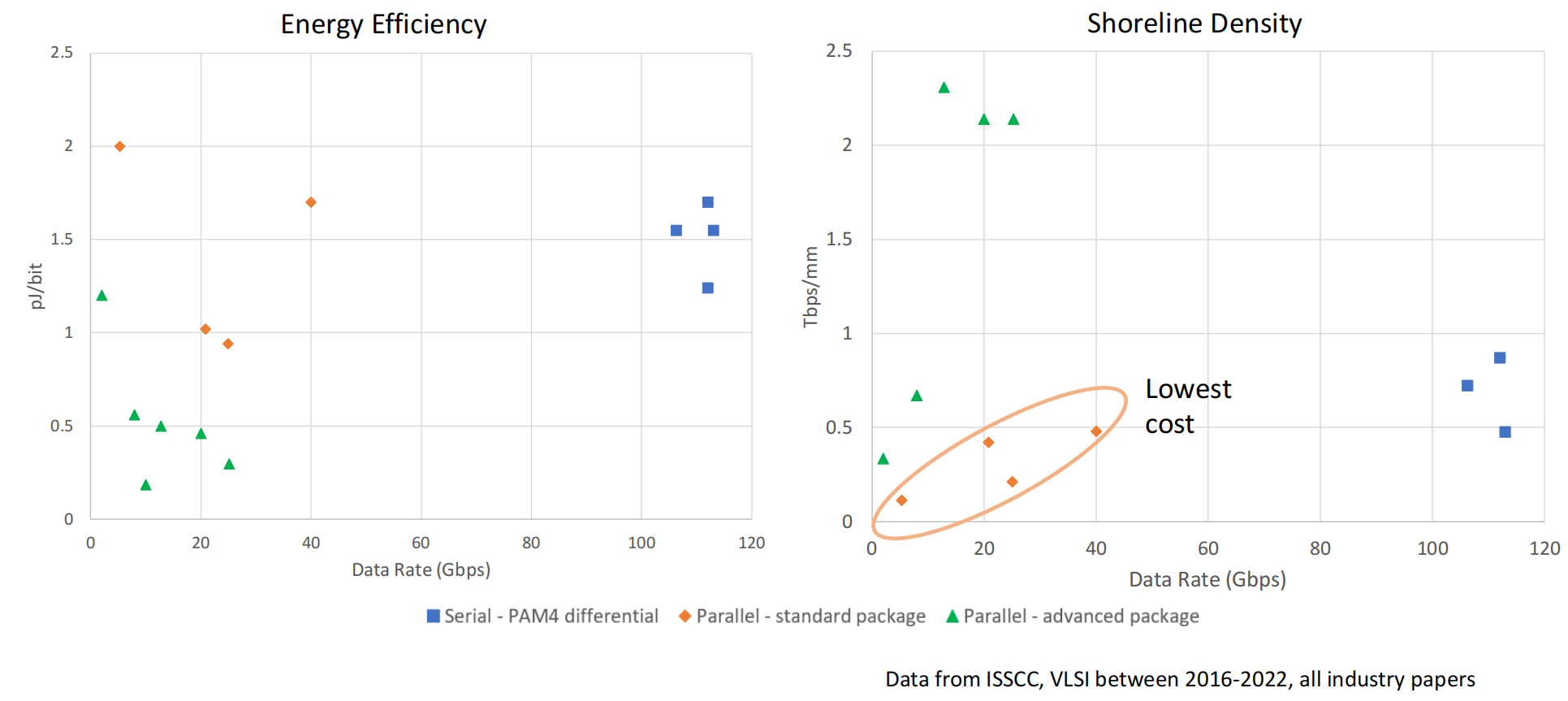
Cadence D2D接口Ultralink
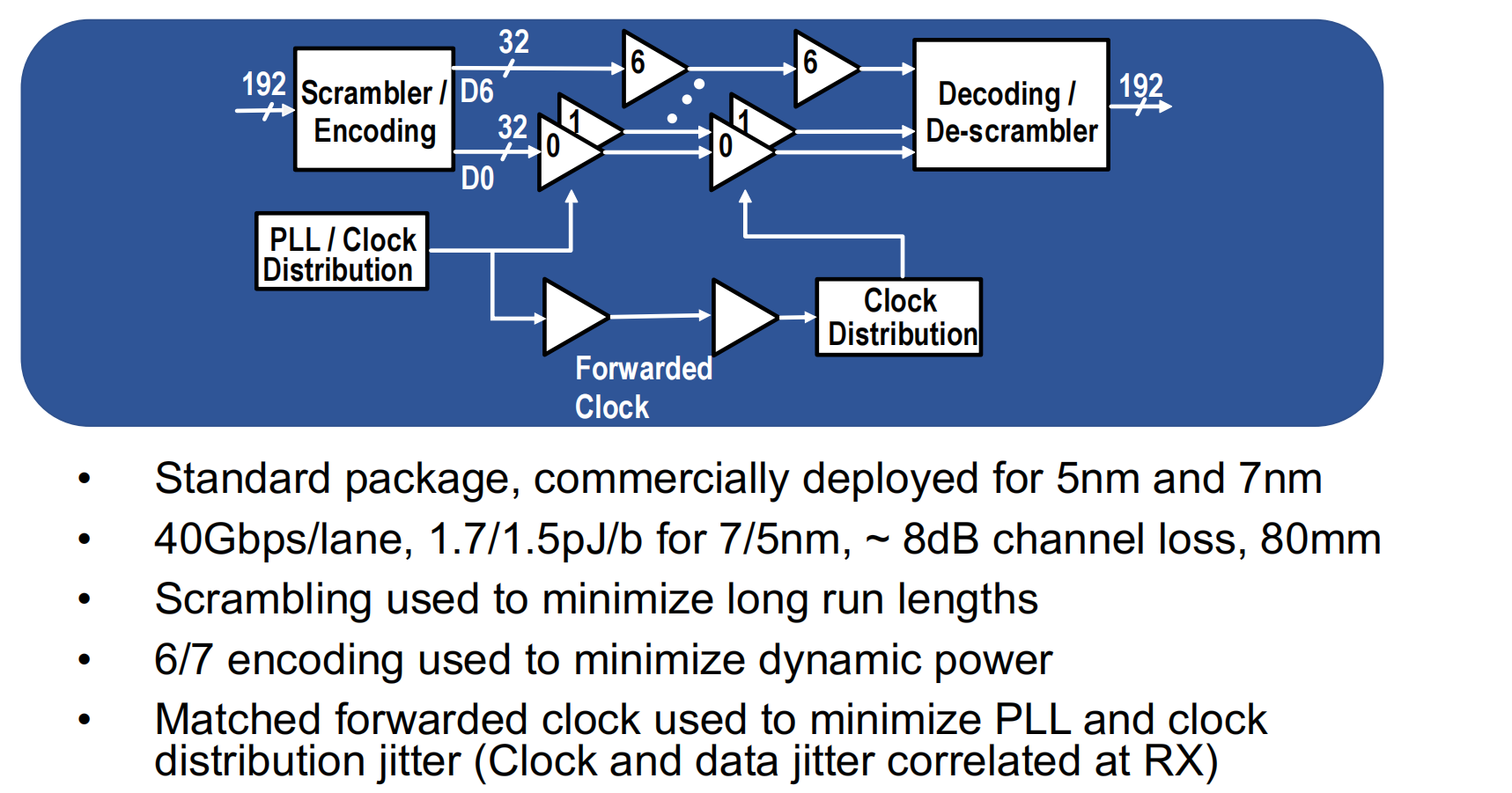
6/7 bit编码尽可能达到直流平衡。
- 评
chiplet IO接口的设计空间。本文将目前已有的chiplet IO类型根据封装和信号编码类型分成三大类,并详细介绍了cadence的D2D接口,其6/7bit编码特性使该接口在低延迟、能效、带宽密度、低成本方面有较为平衡的优势。同时也展望了UCIe未来将可能统一chiplet接口。
软件相关开发议题
HALO: A Compiler Framework for Chiplet Architectures
研究者:Weiming Zhao, Weifeng Zhang(@ Alibaba Cloud)
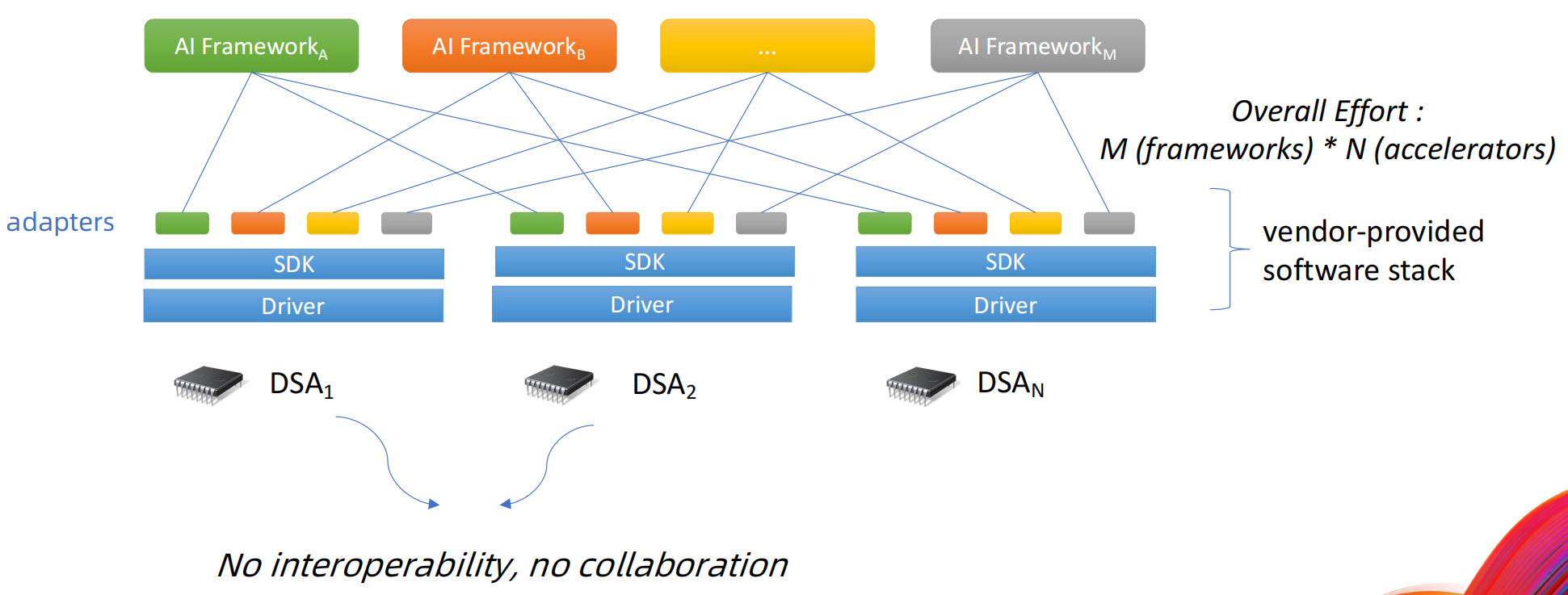
软件开发面临的挑战
- 纵向扩展:碎片化的软件生态
- 不同硬件有不同供应商提供的软件栈
- 巨大的移植工作和长时间的产品上市时间
- 缺乏互操作性
- 横向扩展
- 工作负载并行化
- 针对chiplet系统的分布式计算系统
软件升级的目的和解决方案
目的
- 减少工作量
- 充分发挥AI的性能
- 纵向扩展更多种硬件
- 合理的安排不同chiplet的工作
- 横向扩展更多相同的处理器
- 高效且灵活
- 不依赖于特定的AI框架
- 更少的内存资源占用
- 更少运行时间
解决方案
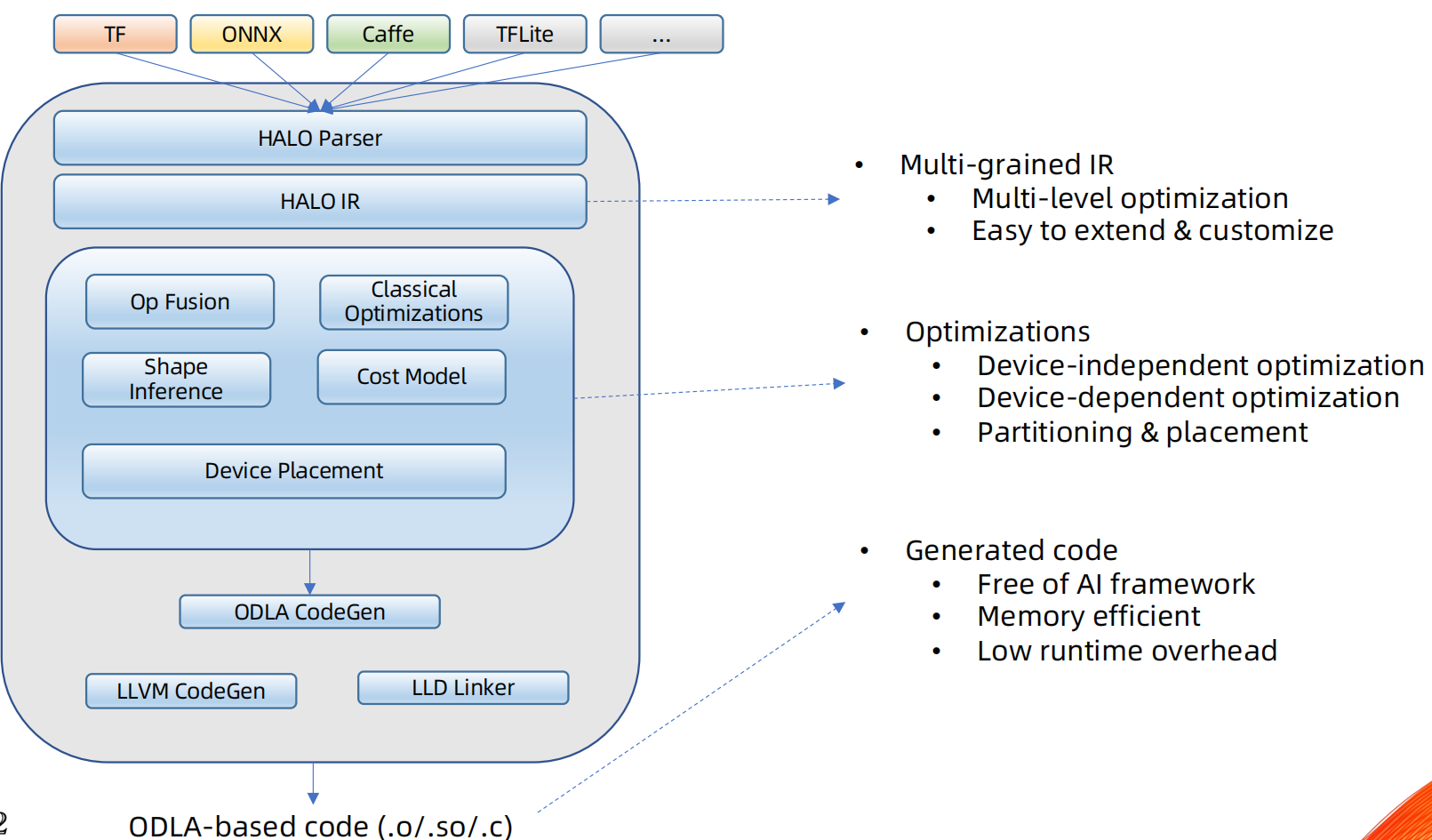
- 统一的AI计算编程模型:开放的深度学习API(Open Deep Learning API, ODLA)

- 优化的编译器框架:Heterogeneity Aware Lowering & Optimization (HALO)
- 基于ODLA代码编译AI算法,构建工作流
- 优化经典的编译器
- 优化AI算法
- 支持异构设备
- 优化并行化和共享
HALO架构
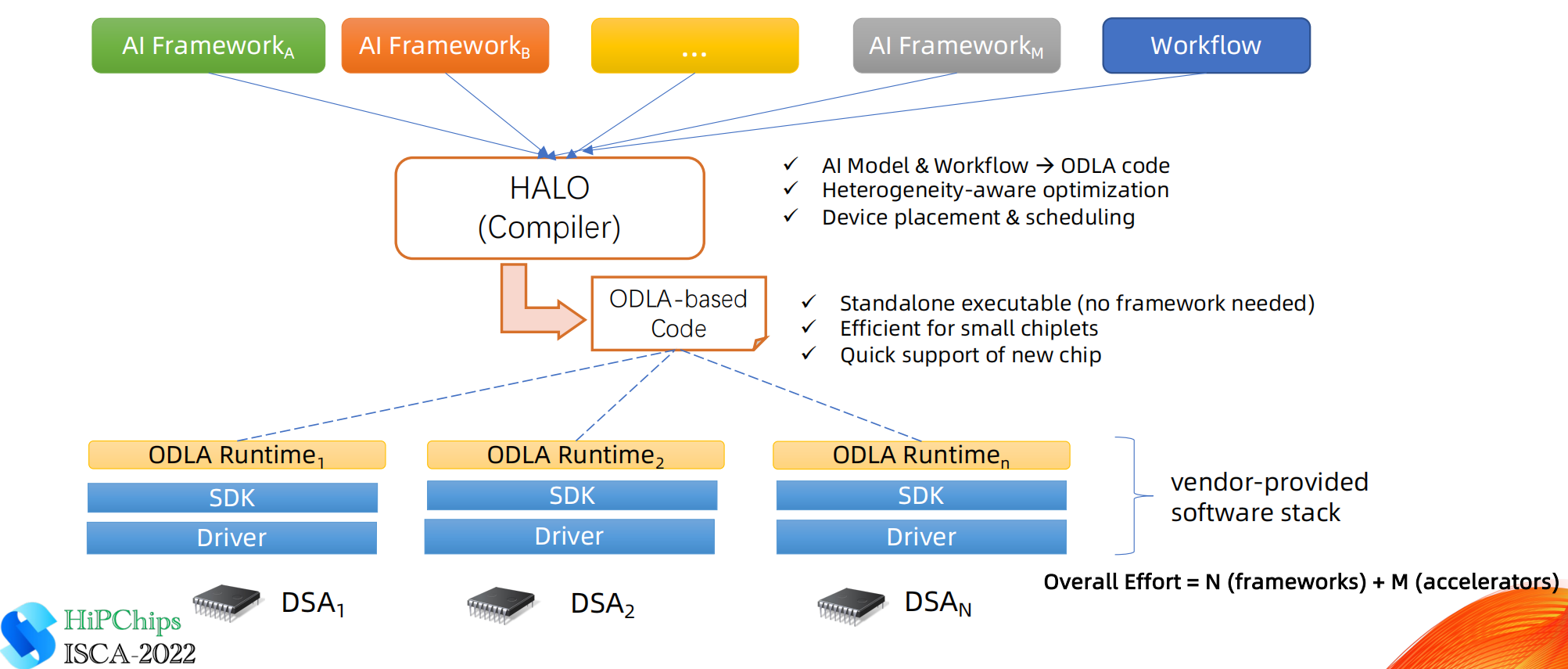
HALO组件
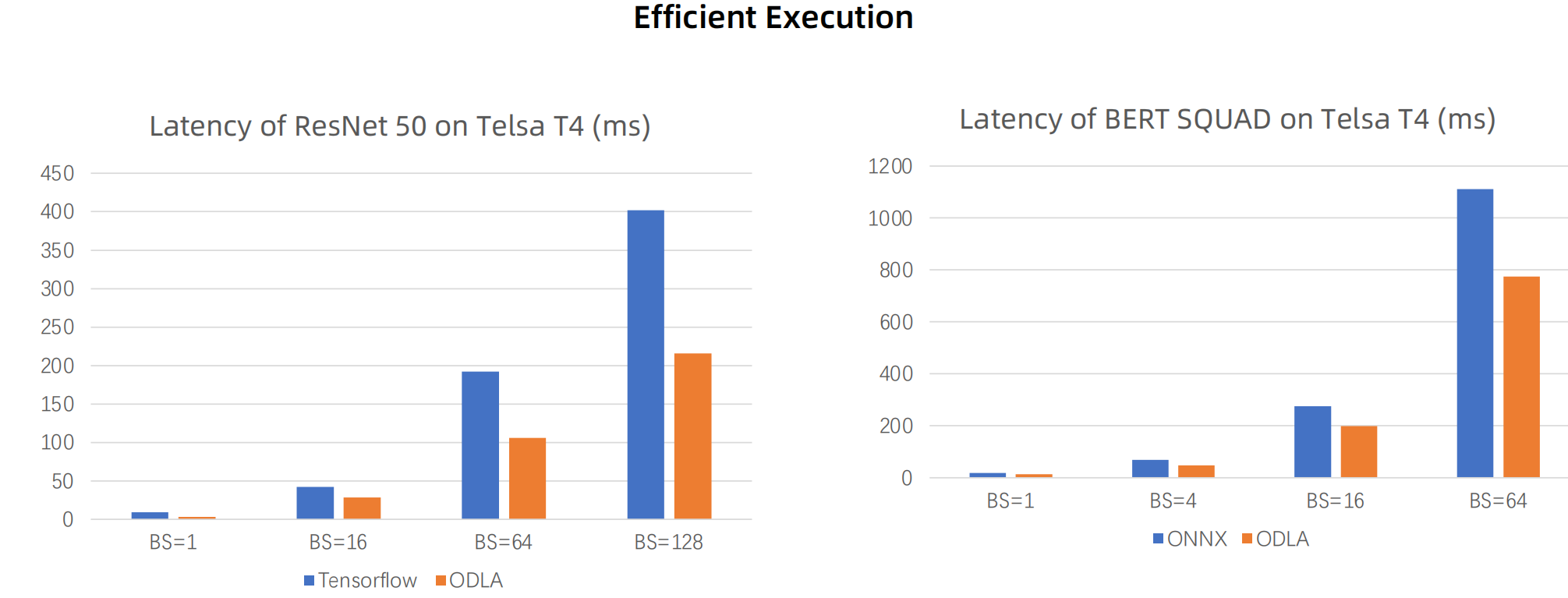
使用HALO后的性能对比

- 评:
异构架构的软件编译框架。阿里云从2017年开始投入建设的震旦异构计算开放平台(HALO/ODLA),因其可裁剪可扩展的轻量级接口、极简的内存足迹、和内禀的异构并行支持,非常适宜于作为小芯片加速系统的软硬协同计算平台。
HALO为了解决不同AI计算平台、和AI算法模型不统一的问题,将各种AI模型编译成C++描述的API接口,通过该API对应的运行时库,AI模型的C++程序可以运行在不同的计算平台上。
EDA生态议题
Configurable IO chiplet Architecture
Speaker: Rishi Chugh (@ Cadence)
chiplet系统自动化引擎的参数
- 评
可配置IO chiplet架构。该报告感觉使Cadence的chiplet产品的宣传报告,cadence拥有从接口IP、性能评估等全流程工具,客户只需要关心架构层面。
The Case for a Universal Chiplet Revolution
-
Speaker: Rohit Mittal & Cliff Young(@ Google)
-
评
通用chiplet进化的案例。google的该报告提出了chiplet是未来定制化芯片的方向,但是需要打破生态的“鸡生蛋和蛋生鸡”的问题,为此google在生态建设方面做了很多工作,对业界的交流持开放态度。
Software-defined design for systems of chiplets
- Speaker: Dr. Duncan Haldane (@ JITX)
一种chiplet系统编译器
工作流:
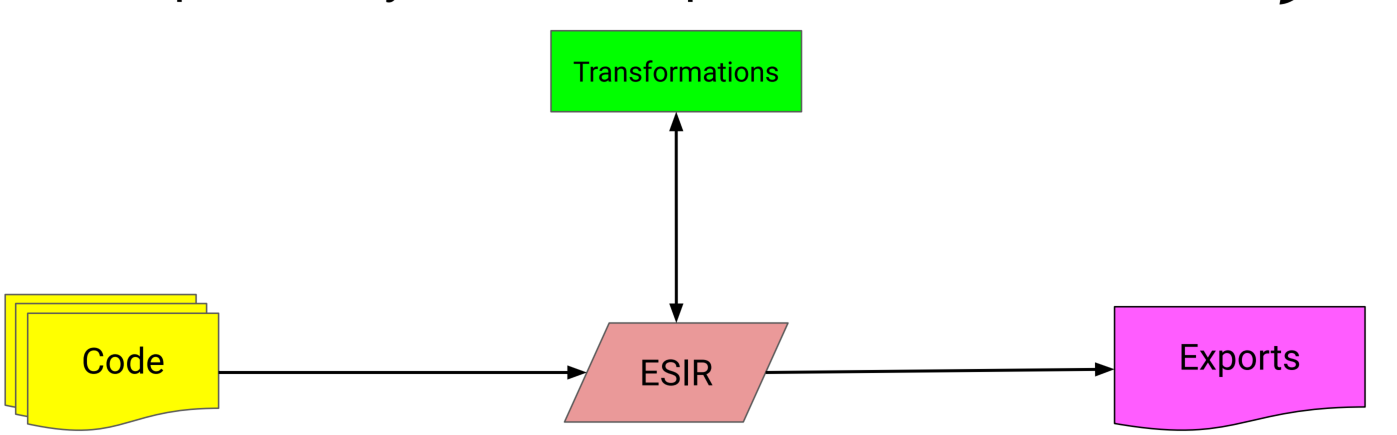
编译器框架:
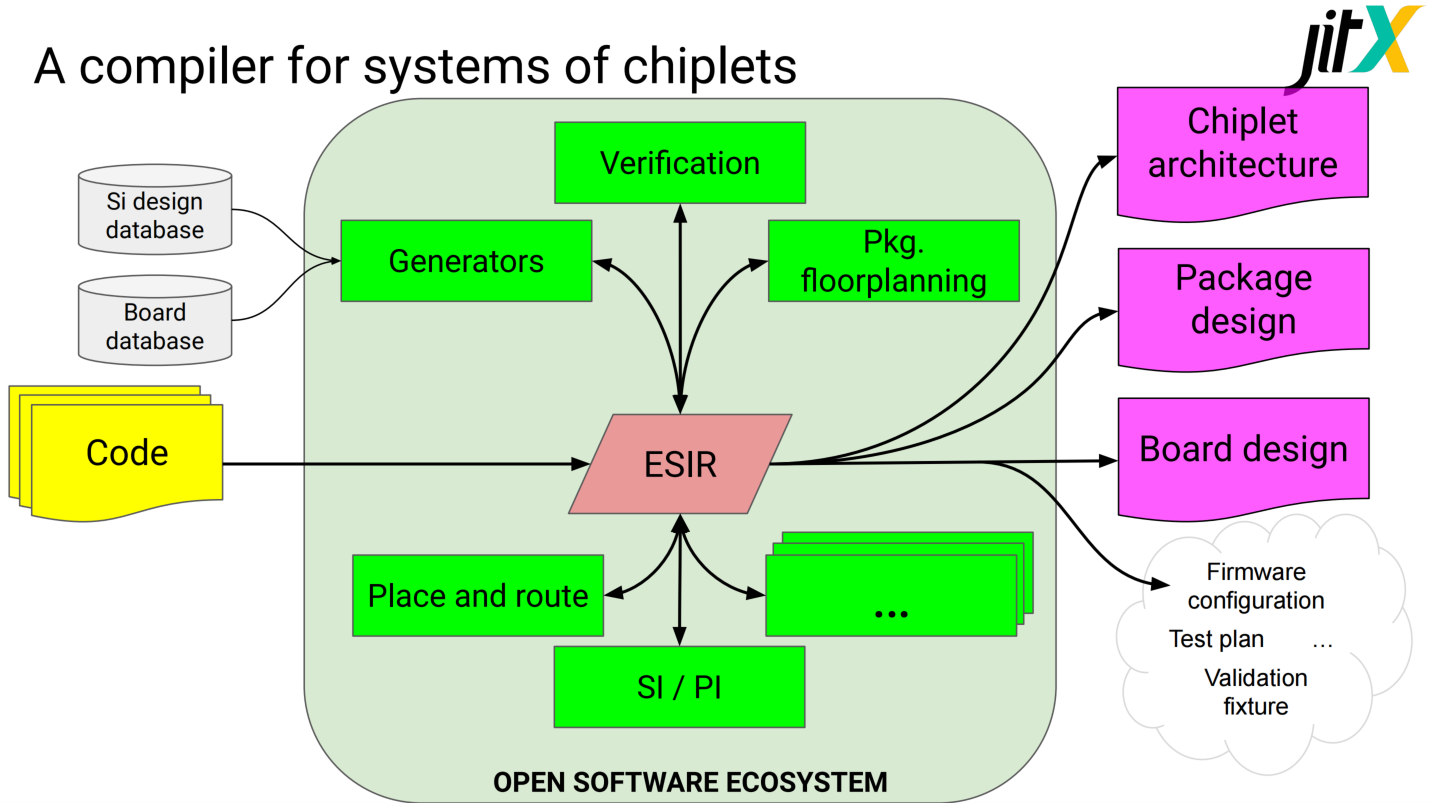
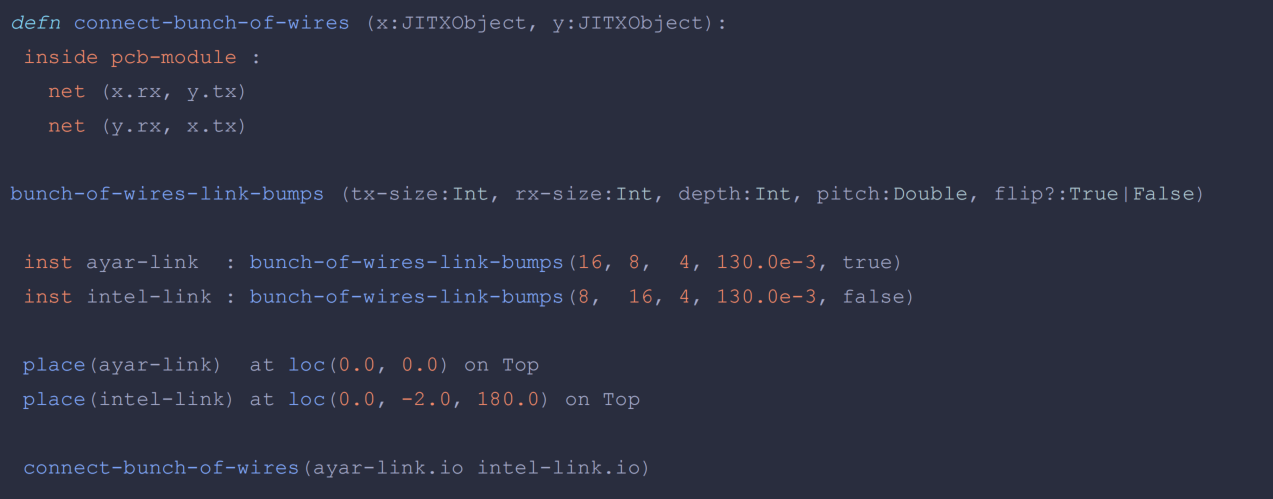
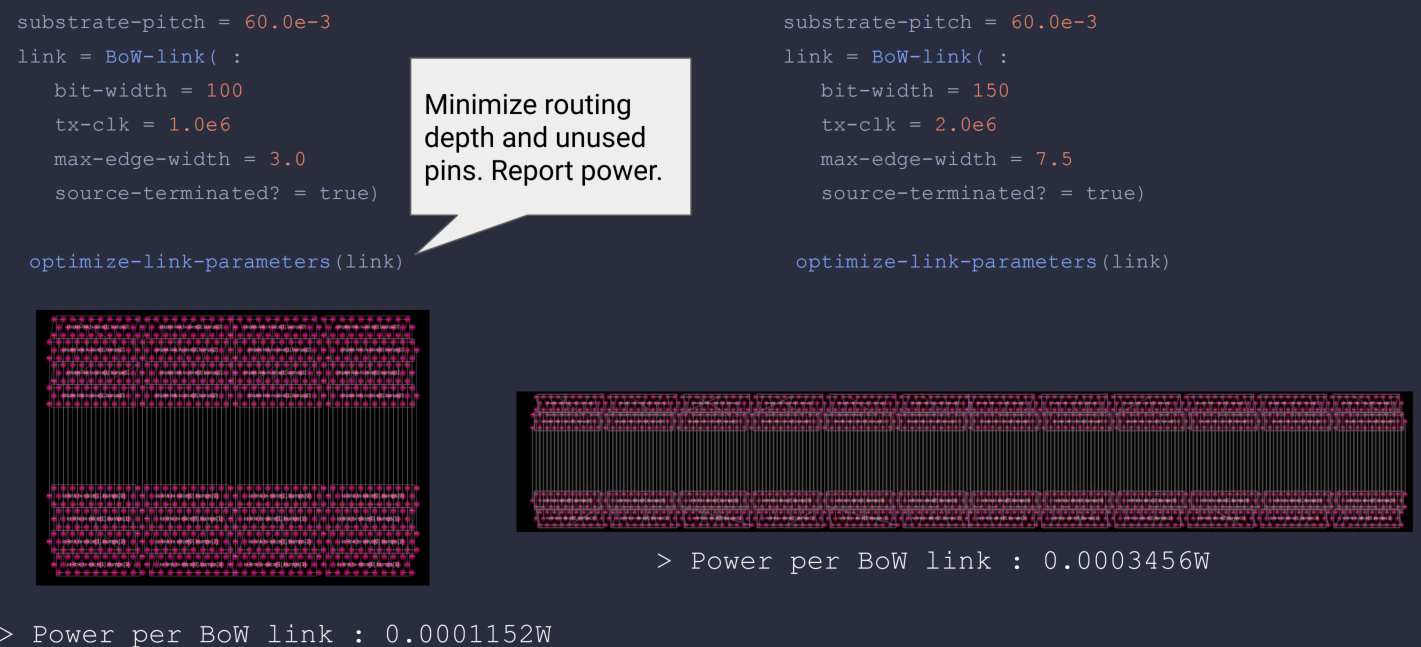
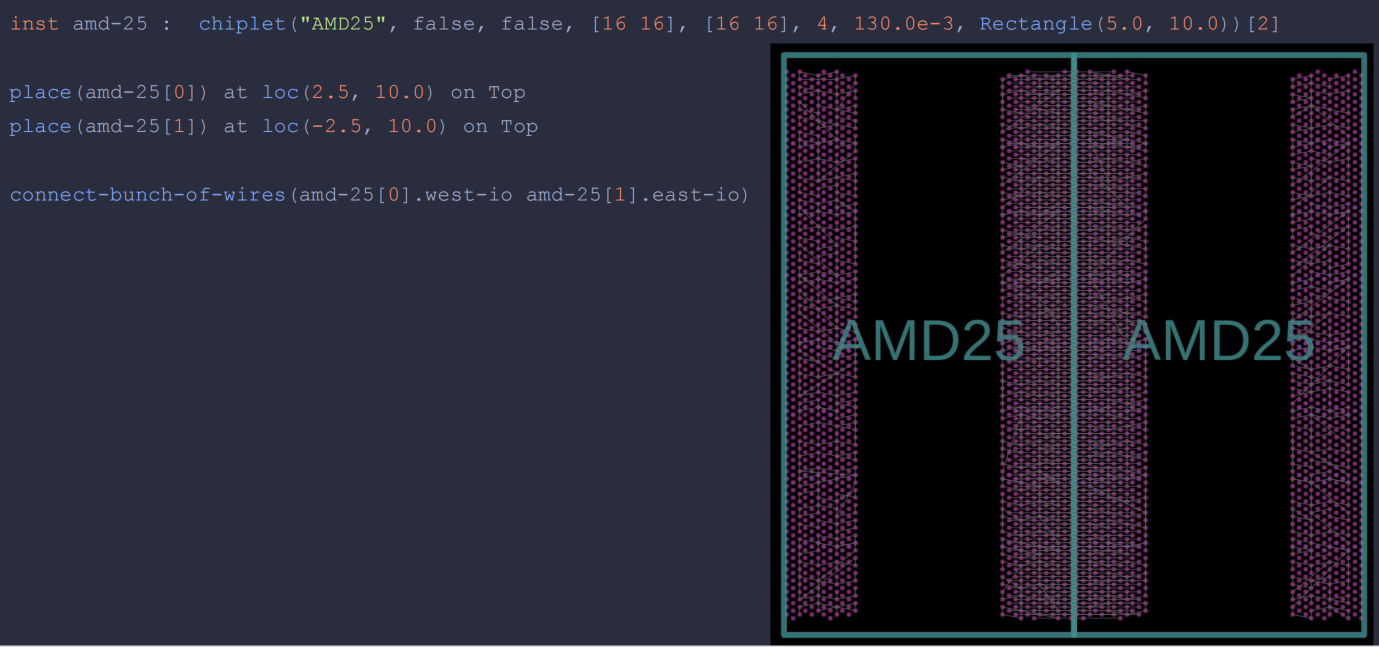
以BoW为例可以描述slice、die组件架构、链路等信息
- 评
软件定义的chiplet系统设计。该报告通过Chisel 语言和软件定义方案来描述chiplet、package、board设计的集成和优化,其系统设计中间表示(ESIR)和chiplet编译器,让小芯片系统的自动验证和优化更加高效和便捷。推测tapeout流程让需要传统EDA工具参与。
其他链接
“小芯片 大集成” 从软硬协同看Chiplet生态——ISCA 2022-HiPChips研讨会组织观察记
Cerebras:晶圆级大芯片


















 2269
2269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











