






神经网络结构包括输入层、隐藏层和输出层,其中输入层大小取决于输入特征数,输出层大小由输出目标值确定,而隐藏层的个数和尺寸,如何确定?
首先理解一下,隐藏层个数和尺寸,如下图所示:
x,y 中间的就是隐藏层个数,而每个隐藏层的神经元数量就是隐藏层的尺寸。
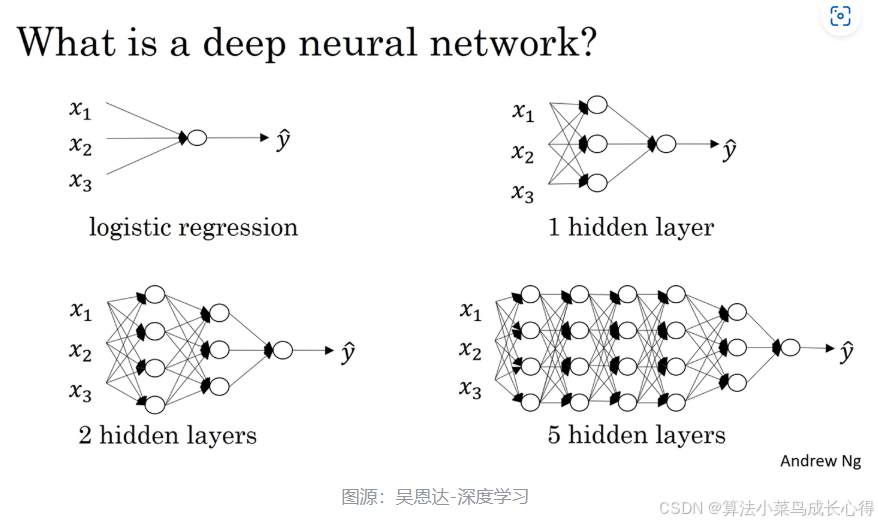
隐藏层个数和尺寸如果比较小,容易欠拟合,而如果过大,又会导致过拟合,因此合理使用隐藏层的个数和尺寸,是决定模型效果好坏的关键参数。
隐藏层个数:
- 没有隐藏层:仅能够表示线性可分函数或决策
- 隐藏层数=1:可以拟合任何“包含从一个有限空间到另一个有限空间的连续映射”的函数
- 隐藏层数=2:搭配适当的激活函数可以表示任意精度的任意决策边界,并且可以拟合任何精度的任何平滑映射。
- 隐藏层数>2:多出来的隐藏层可以学习复杂的描述(某种自动特征工程)
注:对于非时序数据,一般2个隐藏层足够了,如果涉及CV、NLP 可能需要更多(2-10个左右)
隐藏层尺寸(hidden_size):

而且一般隐藏层尺寸为2的幂次方,为什么一般都是32,64,128 这种呢?大模型给出的原因:
1. 硬件优化
现代计算硬件(如CPU和GPU)在处理2的幂次方大小的数据时效率更高。这是因为这些硬件设计时考虑了内存对齐和 SIMD(单指令多数据)操作,这些操作在数据大小为2的幂次方时可以更高效地执行。例如,AVX(高级矢量扩展)等技术可以处理批量大小的数字,这些批量大小通常是2的幂次方。
2. 内存对齐
在计算机内存管理中,数据块的大小通常被设计为2的幂次方,以确保内存对齐。这可以减少内存访问的延迟,提高数据处理的速度。
3. 实践中的便利性
在实际应用中,使用2的幂次方作为隐藏层尺寸可以简化代码和配置。例如,许多深度学习框架和库在处理2的幂次方大小的张量时有优化的实现,这可以减少开发和调试的时间。
4. 经验法则
在神经网络的设计中,隐藏层的大小通常需要通过实验和经验来确定。以下是一些常见的经验法则:
-
输入层和输出层大小的中间值:隐藏层的大小可以设置为输入层和输出层大小的中间值,例如输入层大小为784(如MNIST数据集),输出层大小为10,隐藏层大小可以设置为256、128、64等。
-
逐步减小:在多层网络中,隐藏层的大小可以逐步减小,例如从256到128再到64,这有助于逐步提取更高层次的特征。
5. 计算复杂度和模型容量
较大的隐藏层尺寸可以提供更大的模型容量,使网络能够学习更复杂的特征。然而,这也增加了计算复杂度和内存使用。因此,选择合适的隐藏层尺寸需要在模型性能和计算资源之间进行权衡。

















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









