






需求描述:
随着业务持续拓展,企业的物料基础数据规模呈指数级增长,当数据体量达到一定规模时,如何在日常业务中快速精准地辨识某个物品是否已合规存在于物料数据库中,并最终确定其是需作为新物料录入还是可直接归类至现有物料,成为亟待解决的关键问题。
技术路径:
核心技术路径围绕数据标准化处理、语义向量表征、高维向量管理、智能匹配决策及深度语义解析五大环节展开,具体技术流程如下:
- 一、数据标准化处理(Data Preprocessing):通过结构化清洗与特征工程构建高质量数据集。
- 二、语义向量表征(TextVectorization):基于深度语言模型实现文本到语义向量的映射。
- 三、高维向量管理(Vector Storage & Retrieval):借助向量数据库实现海量向量的高效存储与检索。
- 四、智能匹配决策(Similarity Matching):基于近似最近邻搜索(ANN)实现物料相似性评估。
- 五、深度语义解析(Large Model Explanation):利用大语言模型(LLM)实现匹配结果的可解释性增强。
代码实践:
1.数据准备
从系统中将物料的主数据导出,共计15万条左右。整理excel数据如下:number=物料编码;name=物料名称;baseunit=物料单位;modelnum=规格型号。
2.数据预处理
import pandas as pd
import torch
from sentence_transformers import SentenceTransformer
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
# 读取Excel数据
df = pd.read_excel("materials.xlsx", engine='openpyxl')
# 合并文本字段 df["number"].astype(str) + "||" +
df["text"] = df["name"]+"||" + df["baseunit"]+"||" + df["modelnum"].fillna('')
texts = df["text"].tolist()
3.加载文本编码模型
本次使用的模型是paraphrase-multilingual-MiniLM-L12-v2,由于特殊原因需要先下载好再加载本地的模型。自然语言处理(NLP)领域中,高质量的句子嵌入模型扮演着至关重要的角色,它们能够将复杂语言概念转化为易于机器处理的向量形式。paraphrase-multilingual-MiniLM-L12-v2。它是sentence-transformers库中的一员,擅长于多语言环境下的句子相似性检测和文本分析。我们利用该模型将物料名称、单位、规格型号拼接后的字符串映射到384维的密集向量空间中,用于语义搜索任务。
①安装依赖
pip install -U huggingface_hub
②设置环境变量
Linux
export HF_ENDPOINT=https://hf-mirror.com
Windows Powershell
$env:HF_ENDPOINT = "https://hf-mirror.com"
建议将上面这一行写入 ~/.bashrc。
③下载模型
huggingface-cli download --token XXXX --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir paraphrase-multilingual-MiniLM-L12-v2
④使用模型
# 使用多语言模型
device = "cuda" if torch.cuda.is_available() else "cpu"
model = SentenceTransformer('./paraphrase-multilingual-MiniLM-L12-v2/', device=device)
4.生成向量
# 生成向量(分批处理避免内存不足)
vectors = []
batch_size = 5000 # 根据内存调整
for i in range(0, len(texts), batch_size):
batch_texts = texts[i:i+batch_size]
batch_vectors = model.encode(batch_texts, convert_to_tensor=False)
vectors.extend(batch_vectors.tolist())
print("第" + str(i) + "个向量化")
print("向量化完成")
5.连接Milvus并定义集合
本次我们选择的向量数据库是Milvus,Milvus是一个开源的向量数据库,专为AI应用中的大规模向量相似性搜索而设计。
向量数据库是专门设计用于通过向量嵌入和数值表示来管理和检索非结构化数据的系统,这些表示捕捉了图像、音频、视频和文本内容等数据项的本质。与处理结构化数据并执行精确搜索操作的传统关系数据库不同,向量数据库擅长使用 Approximate Nearest Neighbor(ANN)算法等技术进行语义相似性搜索。
# 连接Milvus
connections.connect(host="XXXXXXXX.XXXX.XXXX", port="19530", user="XXXX", password="XXXXXX")
# 定义集合结构
collection_name = "materials"
dim = 384 # 模型输出维度
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
# 字段定义
fields = [
FieldSchema(name="material_id", dtype=DataType.VARCHAR, is_primary=True, max_length=100),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=dim),
FieldSchema(name="name", dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name="unit", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="specification", dtype=DataType.VARCHAR, max_length=1000)
]
schema = CollectionSchema(fields, description="物料数据向量库")
collection = Collection(name=collection_name, schema=schema)
6.分批次插入数据
# 准备数据批次
insert_batch_size = 1000 # 根据Milvus性能调整
material_ids = df["number"].astype(str).tolist()
names = df["name"].astype(str).tolist()
units = df["baseunit"].astype(str).tolist()
specs = df["modelnum"].astype(str).tolist()
total = len(material_ids)
for i in range(0, total, insert_batch_size):
end_idx = min(i + insert_batch_size, total)
batch = [
material_ids[i:end_idx], # 主键
vectors[i:end_idx], # 向量
names[i:end_idx],
units[i:end_idx],
specs[i:end_idx]
]
collection.insert(batch)
print(f"已插入 {end_idx}/{total} 条数据")
print("所有数据插入完成")
7.创建索引
# 定义索引参数
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128}
}
collection.create_index(field_name="vector", index_params=index_params)
8.整合代码运行

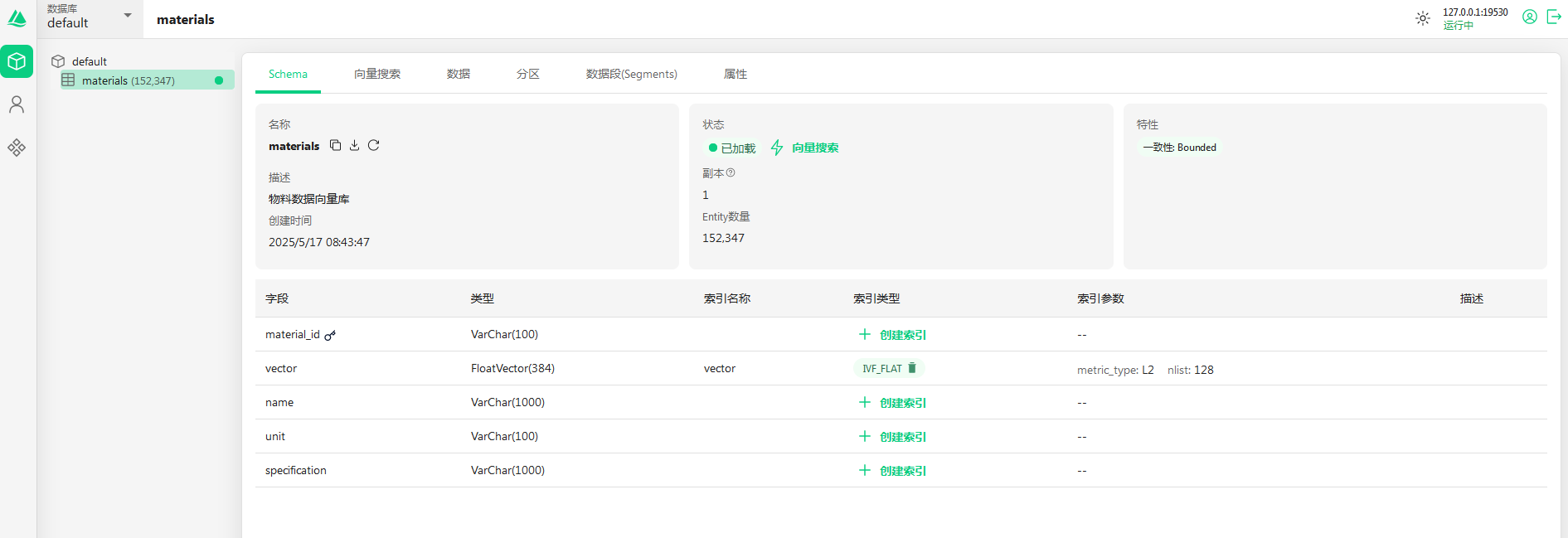
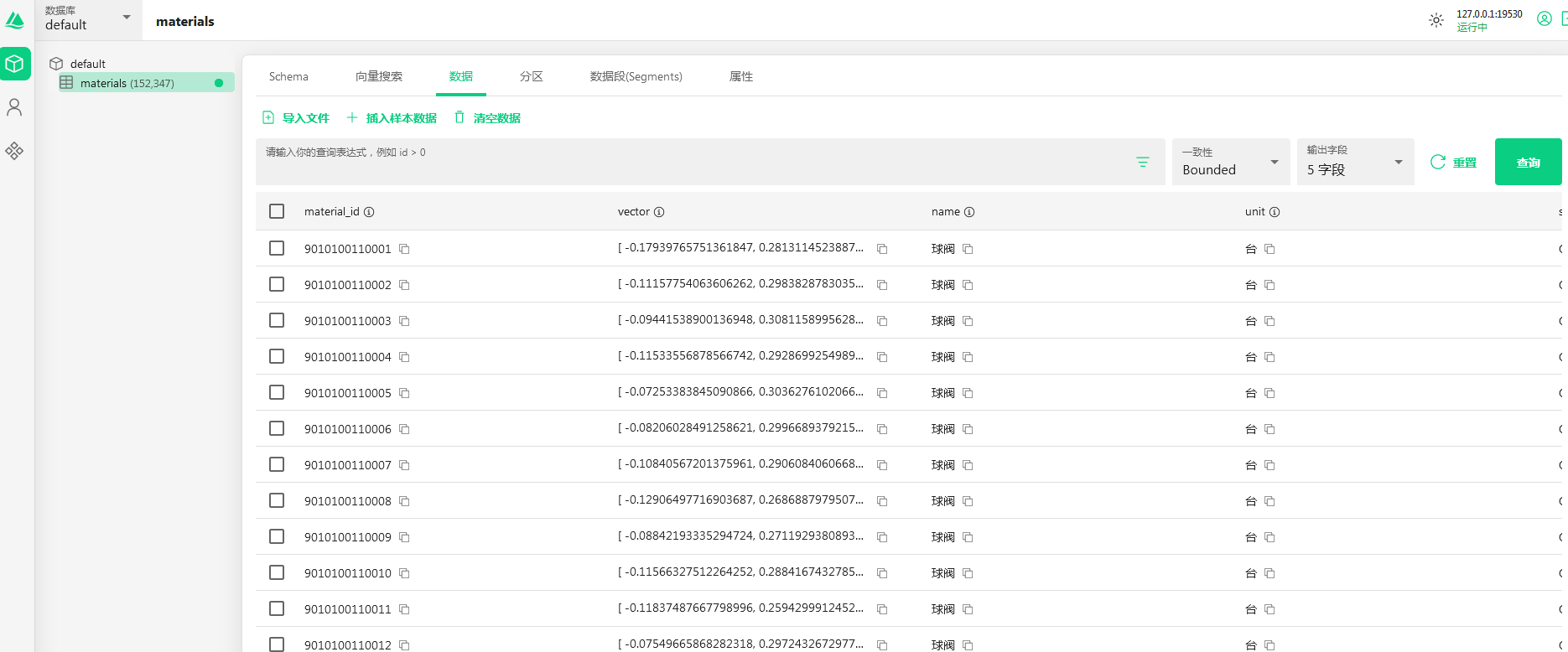
 我们通过autt manager查看数据已经成功入库
我们通过autt manager查看数据已经成功入库
9.向量检索
from sentence_transformers import SentenceTransformer
from pymilvus import connections, Collection, utility
from typing import List, Dict
from 物料辨识_3 import generate_explanation
class MaterialDuplicateChecker:
def __init__(self, model_path: str, milvus_cfg: dict):
# 初始化模型
self.model = SentenceTransformer(model_path)
# 连接Milvus
connections.connect(**milvus_cfg)
self.collection = Collection("materials") # 集合名称
self.collection.load()
# 配置参数
self.search_params = {
"metric_type": "L2",
"params": {"nprobe": 128}
}
self.sim_threshold = 0.6 # 需根据业务数据调整
def _preprocess_text(self, name: str, unit: str, spec: str) -> str:
"""生成与入库时一致的文本格式"""
return f"{name.strip()}||{unit.strip()}||{spec.strip()}"
def search_similar(self,
material_name: str,
material_unit: str,
material_spec: str) -> List[Dict]:
"""执行相似性搜索"""
# 生成查询向量
search_text = self._preprocess_text(material_name, material_unit, material_spec)
query_vector = self.model.encode([search_text])[0].tolist()
print(query_vector)
# 构建过滤表达式
expr = None
# 执行搜索
results = self.collection.search(
data=[query_vector],
anns_field="vector",
param=self.search_params,
limit=5, # 返回前5个可能重复项
expr=expr,
output_fields=["material_id", "name", "unit", "specification"]
)
# 处理结果
duplicates = []
for hits in results:
for hit in hits:
# 计算相似度得分(L2距离转相似度)
similarity = 1 - (hit.distance / 2) # 将L2距离转换为0-1相似度
if similarity >= self.sim_threshold:
duplicates.append({
"id": hit.entity.get("material_id"),
"name": hit.entity.get("name"),
"unit": hit.entity.get("unit"),
"spec": hit.entity.get("specification"),
"similarity": round(similarity, 3)
})
return duplicates
@staticmethod
def format_result(results: List[Dict]) -> str:
"""格式化输出结果"""
if not results:
return "✅ 无相似物料,可以新增"
report = ["⚠️ 发现疑似重复物料:"]
for item in results:
report.append(
f"ID: {item['id']} | 相似度: {item['similarity'] * 100:.1f}%\n"
f"名称: {item['name']}\n"
f"单位: {item['unit']}\n"
f"规格: {item['spec']}\n"
f"{'-' * 40}"
)
return "\n".join(report)
# 使用示例
if __name__ == "__main__":
# 配置参数
MODEL_PATH = "./paraphrase-multilingual-MiniLM-L12-v2/"
MILVUS_CONFIG = {
"host": "XXXXX.XXXXX.XXXXX",
"port": 19530,
"user": "XXXX",
"password": "XXXXX",
"alias": "default"
}
# 初始化检测器
checker = MaterialDuplicateChecker(MODEL_PATH, MILVUS_CONFIG)
# 模拟业务员输入
new_material = {
"name": "球阀",
"unit": "台",
"spec": "Q41F-10C-DN15;L=130;水、油品;-29—150℃"
}
# 执行查重(带单位过滤)
duplicates = checker.search_similar(
material_name=new_material["name"],
material_unit=new_material["unit"],
material_spec=new_material["spec"]
)
# 输出结果
print(checker.format_result(duplicates))
# generate_explanation(new_material, duplicates)
本次测试我们随机选取了一个物料进行了简单修改,最后输出结果如下:


10.将检索结果通过大模型解释
这里大模型选择的deepseek
from openai import OpenAI
# 初始化OpenAI客户端
client = OpenAI(
# 如果没有配置环境变量,请用百炼API Key替换:api_key="sk-xxx"
api_key="sk-XXXXXX",
base_url="https://XXXX.XXXX.XXXX/XXXX-XXXX/v1"
)
# 解释生成模块(使用deepseek)
def generate_explanation(query_data, candidates):
"""格式化输出结果"""
if not candidates:
return "✅ 无相似物料,可以新增"
report = []
for item in candidates:
report.append(
f"ID: {item['id']} | 相似度: {item['similarity'] * 100:.1f}%\n"
f"名称: {item['name']}\n"
f"单位: {item['unit']}\n"
f"规格: {item['spec']}\n"
f"{'-' * 40}"
)
"\n".join(report)
prompt = f"""
作为物料管理专家,请分析新申请物料与已有物料的匹配情况:
[新申请物料]
名称:{query_data['name']}
单位:{query_data['unit']}
规格:{query_data['spec']}
[候选匹配物料]
{report}
请用中文按以下格式分析每一个候选匹配物料并输出,不同的匹配物料之间有分隔符分割:
1. 匹配物料ID | 匹配物料相似度
2. 匹配物料名称
3. 匹配物料单位
4. 匹配物料规格
5. 关键匹配因素(材料/尺寸/单位等)
6. 差异点警告(如单位不可转换)
7. 最终建议(直接使用/需人工复核)
"""
reasoning_content = "" # 定义完整思考过程
answer_content = "" # 定义完整回复
is_answering = False # 判断是否结束思考过程并开始回复
# 创建聊天完成请求
stream = client.chat.completions.create(
model="deepseek-r1", # 此处可按需更换模型名称
messages=[
{"role": "user",
"content": prompt}
],
stream=True
# 解除以下注释会在最后一个chunk返回Token使用量
# stream_options={
# "include_usage": True
# }
)
print("⚠️ 发现疑似重复物料:")
print("\n" + "=" * 20 + "思考过程" + "=" * 20 + "\n")
for chunk in stream:
# 处理usage信息
if not getattr(chunk, 'choices', None):
print("\n" + "=" * 20 + "Token 使用情况" + "=" * 20 + "\n")
print(chunk.usage)
continue
delta = chunk.choices[0].delta
# 检查是否有reasoning_content属性
if not hasattr(delta, 'reasoning_content'):
continue
# 处理空内容情况
if not getattr(delta, 'reasoning_content', None) and not getattr(delta, 'content', None):
continue
# 处理开始回答的情况
if not getattr(delta, 'reasoning_content', None) and not is_answering:
print("\n" + "=" * 20 + "完整回复" + "=" * 20 + "\n")
is_answering = True
# 处理思考过程
if getattr(delta, 'reasoning_content', None):
print(delta.reasoning_content, end='', flush=True)
reasoning_content += delta.reasoning_content
# 处理回复内容
elif getattr(delta, 'content', None):
print(delta.content, end='', flush=True)
answer_content += delta.content
# 如果需要打印完整内容,解除以下的注释
"""
print("=" * 20 + "完整思考过程" + "=" * 20 + "\n")
print(reasoning_content)
print("=" * 20 + "完整回复" + "=" * 20 + "\n")
print(answer_content)
"""
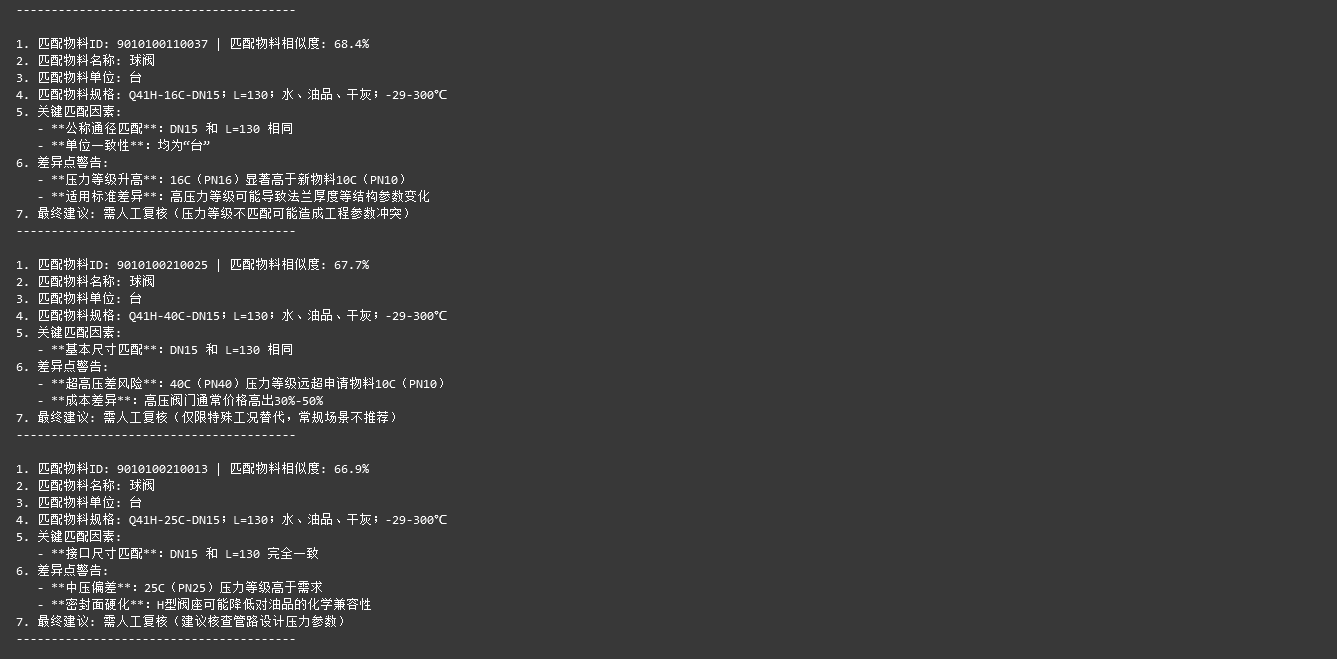
整合后的测试结果:

后续问题
在技术落地与业务融合过程中,需系统性攻克以下关键议题,其中技术路径的优化与业务场景的深度打磨需协同推进,各环节均需投入阶段性研发资源与验证周期:
- 一、业务场景验证与效果迭代
需通过长周期业务数据回溯分析与实时业务场景测试,验证智能识别模块的有效性。 - 二、向量化方法的选型与优化
需开展多模型对比实验与特征工程深度研究,确定最优语义表征方案。 - 三、近似匹配算法的持续优化
需围绕检索精度与响应速度开展算法调优,平衡工程实现与业务需求。 - 四、大模型调校与可信性增强
需构建领域专属知识库与抗幻觉机制,提升解释性结果的可靠性。 - 五、原型系统工程化与产品化
需完成从技术验证到工业级系统的跨越,重点突破工程实现中的关键挑战。


















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











