







 本文介绍了微博特征选择的发展历程,从人工选择到自动化方法,如相关性法、降维法、模型倒推法、GBDT和深度学习。通过对比实验,展示了不同方法对模型预测性能的提升,特别是深度学习在特征提取上的优势。
本文介绍了微博特征选择的发展历程,从人工选择到自动化方法,如相关性法、降维法、模型倒推法、GBDT和深度学习。通过对比实验,展示了不同方法对模型预测性能的提升,特别是深度学习在特征提取上的优势。
近年来,人工智能与机器学习的应用越来越广泛,尤其是在互联网领域。在微博,机器学习被广泛地应用于微博的各个业务,如Feed流、热门微博、消息推送、反垃圾、内容推荐等。
值得注意的是,深度学习作为人工智能和机器学习的分支,尤其得到更多的重视与应用。深度学习与众不同的特性之一,在于其能够对原始特征进行更高层次的抽象和提取,进而生成区分度更高、相关性更好的特征集合,因此深度学习算法还经常被叫作“自动特征提取算法”。由此可见,无论是传统的基础算法,还是时下最流行的深度学习,特征的选择与提取,对于模型最终的预测性能至关重要。另一方面,优选的特征集合相比原始特征集合,只需更少的数据量即可得到同样性能的模型,从系统的角度看,特征选择对机器学习执行性能的优化具有重大意义。
特征选择在微博经历了从最原始的人工选择,到半自动特征选择,到全自动特征选择的过程,如图1所示。我们将详细介绍微博在各个阶段的实践与心得。
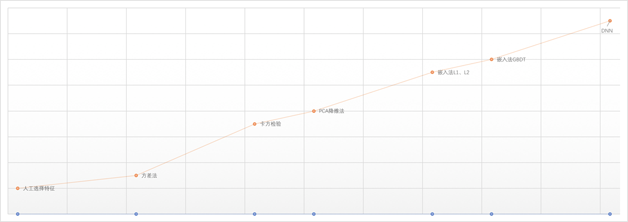
人工选择
在互联网领域,点击率预估(Click Through Rate)被广泛地应用于各个业务场景,在微博,CTR预估被应用在各个业务的互动率预估中。对于CTR预估的实现,逻辑回归(Logistic Regression)是应用最多、最广泛而且被认为是最有效的算法之一。LR算法的优势在于提供非线性的同时,保留了原始特征的可解释性。LR模型产出后,算法人
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3131
3131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









