







自编码器
自动编码器是一种无监督的深度学习算法,它学习输入数据的编码表示,然后重新构造与输出相同的输入。它由编码器和解码器两个网络组成。编码器将高维输入压缩成低维潜在(也称为潜在代码或编码空间) ,以从中提取最相关的信息,而解码器则解压缩编码数据并重新创建原始输入。
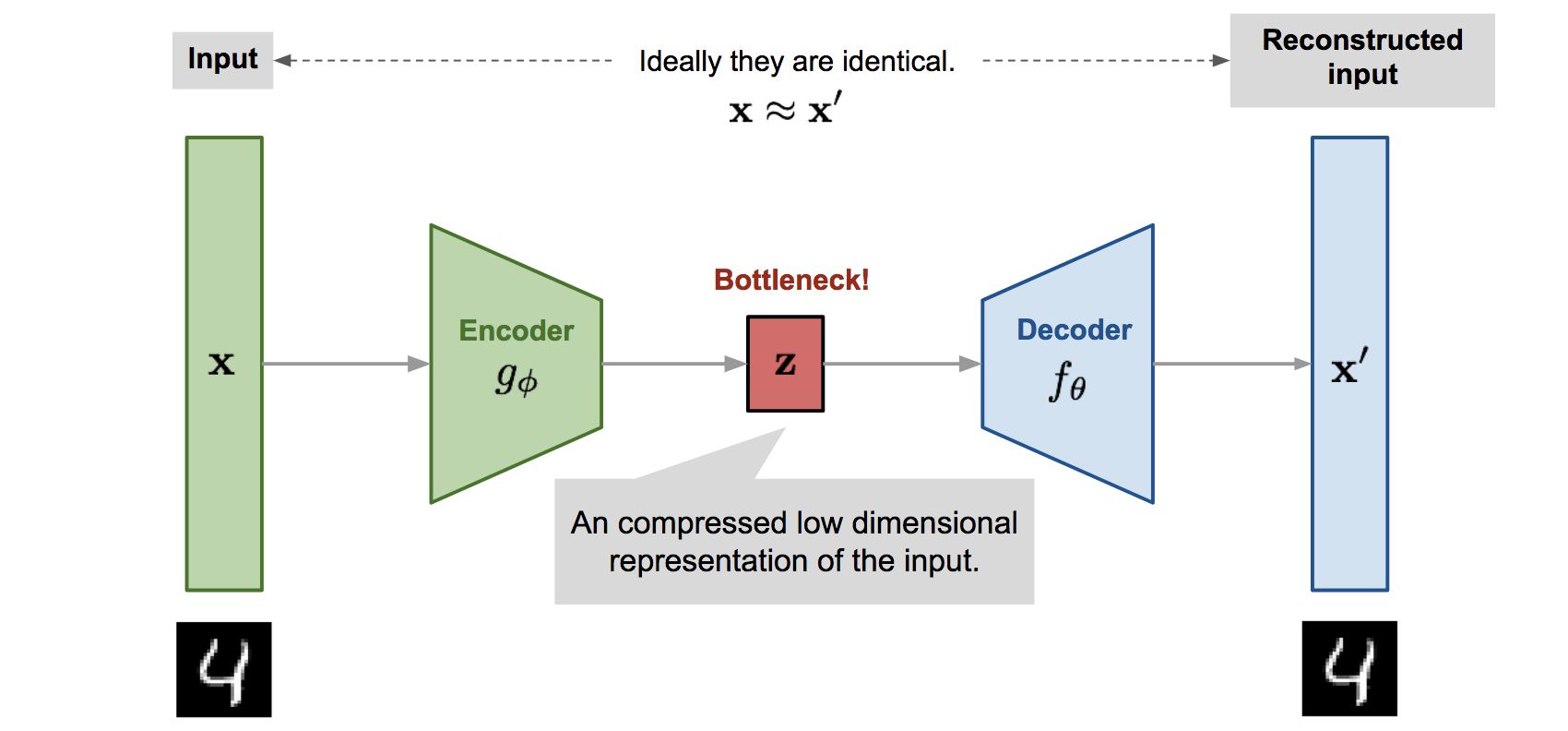
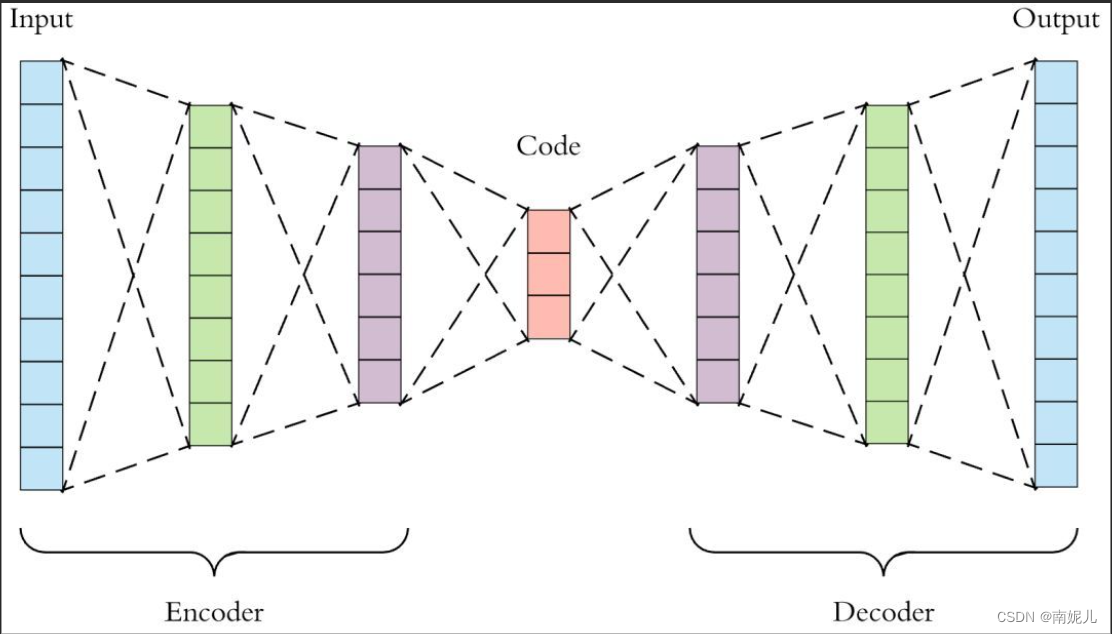
自编码器的输入和输出应该尽可能的相似。
通过输入含有噪声的图像,编码器在编码的过程中会存在信息丢失,将输入和输出最相似的特征保留下来,通过解码器得到最后的输出。在这个转换的过程中实现了图像的去噪。
自编码器主要的用途其实是用于降维,将高维的数据编码为一组向量,解码器通过解码得到输出。
数据集导入可视化
import torchvision
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
import numpy as np
import random
import PIL.Image as Image
import torchvision.transforms as tra
 订阅专栏 解锁全文
订阅专栏 解锁全文
















 4202
4202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











