






会议:2021 interspeech
作者:Yinghao Aaron Li
单位:Columbia University
abstract
- StarGAN v2做many-to-many的变声,使用20个英文说话人训练,可以完成any-to-many,cross-lingual, singing voice conversion。
- 使用style-encoder,可以把plain speech转换成stylistic speech。
introduction
变声的技术路线可以分为三类:
- Auto-encoder approach:encoder去编码说话人无关的信息,需要设定各种限制移除说话人相关的信息;
- GAN-based:使用判别器判断生成的语音和真实目标人的相似度,因为不能保证判别器从real data中学到了合理的信息,因此转换生成的语音可能会有相似度不高、发音错误等问题;
- TTS-based:利用文本标签,保证了音色一致度,但是不能适用于没有文本的场景。
本文是基于StarGAN的框架,对比自然度和相似度结果超过了AUTO-VC 和VTN (tts-based)
method
使用StarGAN v2一样的结构,加入 joint detection and classification (JDC) F0 extraction network保证基频一致性;

目标函数

- 对抗损失
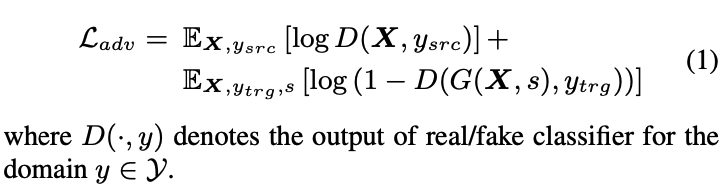
- asr loss
- 基频一致性
- 风格区分性 L d s L_{ds} Lds,随机挑选两个风格,区分度越大越好
experiments
dataset
- VCTK20人的数据,for style JVS dataset(10人,有正常的和假音的句子);for emotion emotional speech dataset (ESD),















 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









