







💪 专业从事且热爱图像处理,图像处理专栏更新如下👇:
📝《图像去噪》
📝《超分辨率重建》
📝《语义分割》
📝《风格迁移》
📝《目标检测》
📝《暗光增强》
📝《模型优化》
📝《模型实战部署》
😊总结不易,多多支持呀🌹感谢您的点赞👍收藏⭐评论✍️,您的三连是我持续更新的动力💖

一、SRGAN网络
1.1 标题
“Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network”
1.2 作者
Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, Wenzhe Shi
1.3 发表时间
2017年
1.4 摘要
SRGAN通过利用生成对抗网络(GAN)来实现单图像超分辨率重建。传统的方法如基于均方误差(MSE)的优化通常会导致图像平滑且缺乏细节,而SRGAN通过引入感知损失函数(perceptual loss),使得重建的图像不仅在像素级别上更接近高分辨率图像,而且在感知质量上也更加接近真实图像。
1.5 主要内容
1.5.1 生成对抗网络架构
生成器(Generator):采用残差网络(ResNet)结构,能够有效地学习从低分辨率图像到高分辨率图像的映射。
判别器(Discriminator):判别器的任务是区分生成的高分辨率图像和真实的高分辨率图像。通过对抗训练,生成器能够学习生成更加逼真的图像。
1.5.2 损失函数
内容损失(Content Loss):利用VGG网络提取的特征来计算生成图像和真实图像之间的差异。
对抗损失(Adversarial Loss):来自GAN的对抗训练,使得生成器能够骗过判别器,从而生成更加逼真的图像。
感知损失(Perceptual Loss):
感知损失结合内容损失和对抗损失,旨在提高重建图像的感知质量,使其在视觉上更接近真实图像。
1.5.3 实验结果
SRGAN在多种数据集上进行了测试,结果表明,与传统方法(如基于MSE的方法)相比,SRGAN生成的图像在感知质量上有显著提升。在用户研究中,SRGAN生成的图像被评为更接近真实图像。
1.6 论文总结
SRGAN通过生成对抗网络和感知损失函数的结合,显著提升了单图像超分辨率重建的效果。该方法不仅在像素级别上达到了更高的精度,同时在视觉感知上也大幅提升,生成的图像更加逼真,细节更加丰富。
二、源码包准备
本配套教程源码包中已经下载好了测试模型和预训练模型,部分训练集和测试集。源码包获取方法文章末扫码到公众号「视觉研坊」中回复关键字:超分辨率重建SRGAN。获取下载链接。
Pytorch版的官网源码包地址:SRGAN
论文地址:论文
三、环境准备
下面是我自己训练和测试的环境,仅供参考,其它版本也行。

3.1 报错:AttributeError: module ‘torch’ has no attribute ‘compile’
该报错是因为yTorch 版本不支持 torch.compile 方法。这种方法是在 PyTorch 2.0 版本中引入的,而我使用的Pytorch为1.12版本
在windows电脑上我安装了2.0.1版Pytorch,继续报错。
3.2 报错:RuntimeError: Windows not yet supported for torch.compile
安装了2.0.1版本Pytorch,见下:

报错见下:

报错原因:在 PyTorch 2.0 中,torch.compile 目前不支持在 Windows 上运行。
解决办法:网络训练过程不加速,把compile关闭,具体见下:

关闭后,后续训练和测试,我继续在之前Pytotch1.12.1版本上操作。
解决该问题还有中方式使用 torch.jit.trace 替代torch.compile,后续没调试。
四、数据集准备
直接运行代码会自动下载数据集,某些情况下会下载中断,而且很慢,可以把数据集下载链接拷贝到迅雷中,速度较快,找数据集链接的方法见下,原论文中的数据集下载链接为:https://huggingface.co/datasets/goodfellowliu/SRGAN_ImageNet/resolve/main/SRGAN_ImageNet.zip

数据集下载好后,先通过split_images.py脚本将各种分辨率的图像裁剪为统一尺寸图片并保存到指定路径中。关于split_images.py脚本的具体用法,以及数据集的样子参考另外一篇博文:高分辨率图像分割成大小均匀图像
测试集的路径见下:

五、训练
源码中有net网络和gan网络,我主要讲解gan网络的训练和测试,net网络的训练和测试类同。源码中有2倍,4倍,8倍超分,本教程主要讲解4倍超分,其它超分类同。
5.1 预训练权重下载
直接运行脚本,代码也会自动下载预训练模型,如果自动下载出了问题,去下面文件中找到预训练模型下载链接:

自己下载的模型权重文件,存放到results\pretrained_models路径中:

5.2 配置文件参数修改
下面是常用参数,其它参数学生根据自己情况自行修改。




5.3 启动训练
gan网络训练的主脚本为train_gan.py,在此脚本中修改训练用的配置文件路径,见下:

直接运行train_gan.py脚本开始训练:

部分训练过程见下:

5.4 实时可视化训练过程损失函数走势
在终端使用下面命令启动tensorboard实时可视化训练过程损失函数走势:
tensorboard --logdir=samples/logs/SRGAN_x4-SRGAN_ImageNet --port 6007

具体的可视化走势图见下:

5.5 训练结果
训练过程的模型权重文件自动保存到results\SRGAN_x4-SRGAN_ImageNet路径下:

训练过程中每一轮的模型权重文件保存到samples\SRGAN_x4-SRGAN_ImageNet路径下:

六、测试
6.1 测试配置文件修改
下面参数学者根据自己情况调整修改。




6.2 启动测试

将上面required设置为False后,直接运行test.py脚本:

输出的评价指标如下:

测试结果保存到result_images\SRGAN_x4-SRGAN_ImageNet-Set14路径下:

七、推理速度
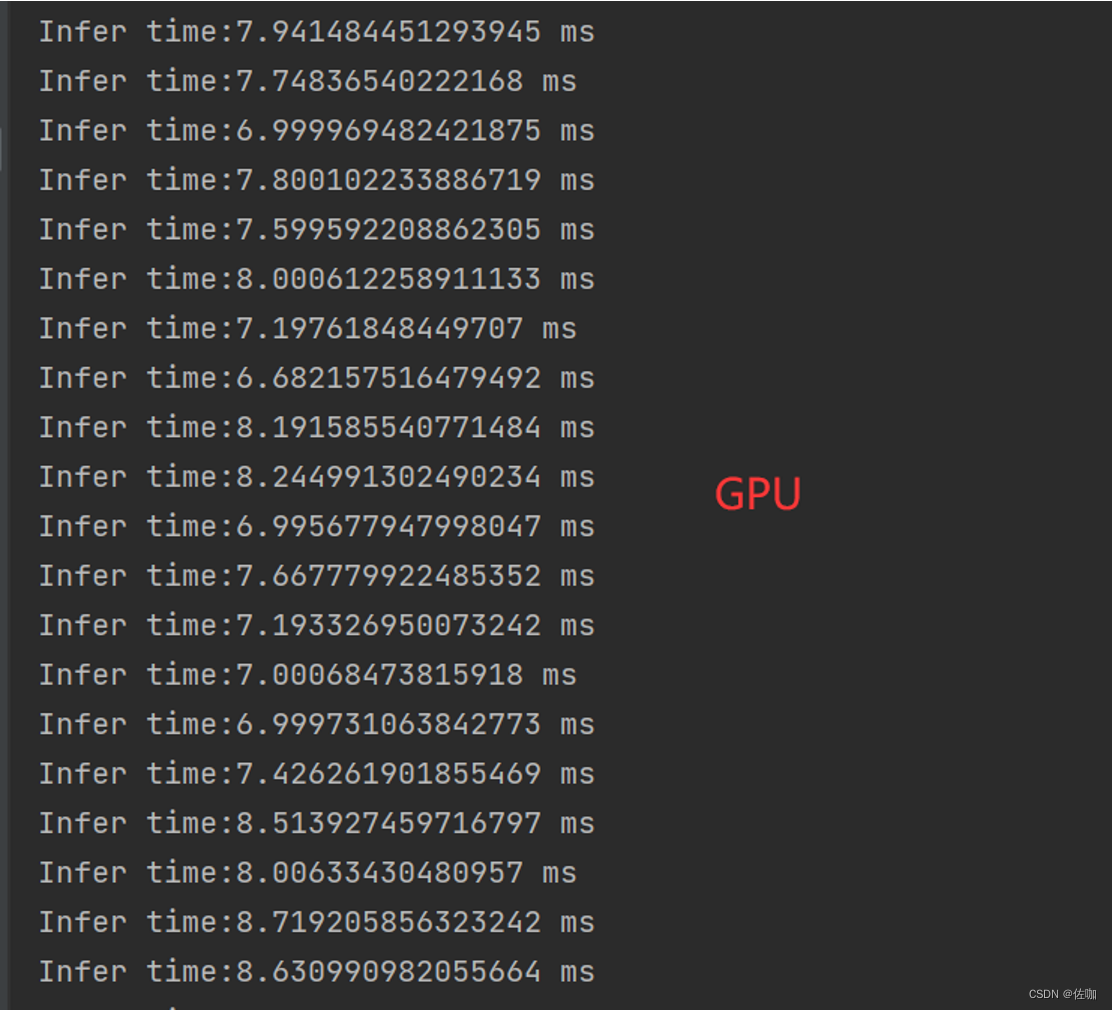
7.1 GPU
GPU测试环境:Nvidia GeForce RTX 3050。
120*90图像超分4倍 GPU平均推理时间:7.69ms/fps。
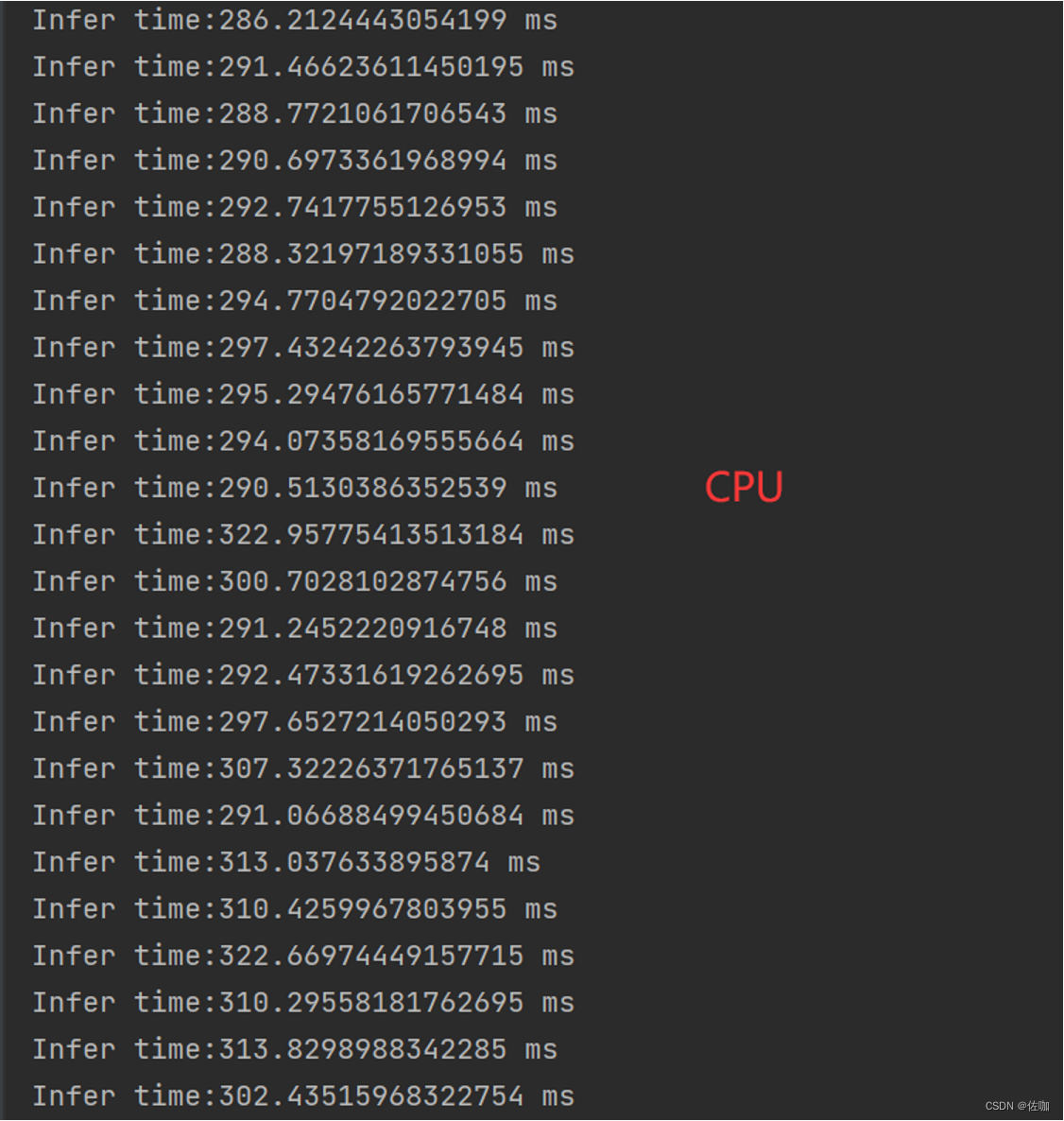
7.2 CPU
12th Gen Intel® Core™ i7-12700H 2.30 GHz。
下面是120*90图像超分4倍,CPU平均推理时间:302.31ms/fps。
八、超分效果展示
下面左图为bicubic上采样4倍,中间为原图,右图为SRGAN网络超分4倍结果图。














九、总结
以上就是超分辨重建SRGAN网络训练自己数据集与推理测试详细过程,超分效果与我超分专栏里的其他网络做对比。
感谢您阅读到最后!关注公众号「视觉研坊」,获取干货教程、实战案例、技术解答、行业资讯!

















 343
343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











