







 本文介绍了均方误差(MSE)在机器学习中的作用,定义了其计算原理,以及如何在Python的PyTorch和TensorFlow框架中使用MSE评估模型性能。通过实例演示了如何在代码中实现MSE计算和神经网络模型的训练过程。
本文介绍了均方误差(MSE)在机器学习中的作用,定义了其计算原理,以及如何在Python的PyTorch和TensorFlow框架中使用MSE评估模型性能。通过实例演示了如何在代码中实现MSE计算和神经网络模型的训练过程。
均方误差(MSE)是机器学习中常用的评价指标,用于衡量模型预测值与真实值之间的差异。在实际应用中,我们通常使用均方误差来评估回归模型的性能。
一、均方误差的概念
均方误差(MSE)是指观测值与预测值之间差异的平方和的平均值。用数学公式表示为:
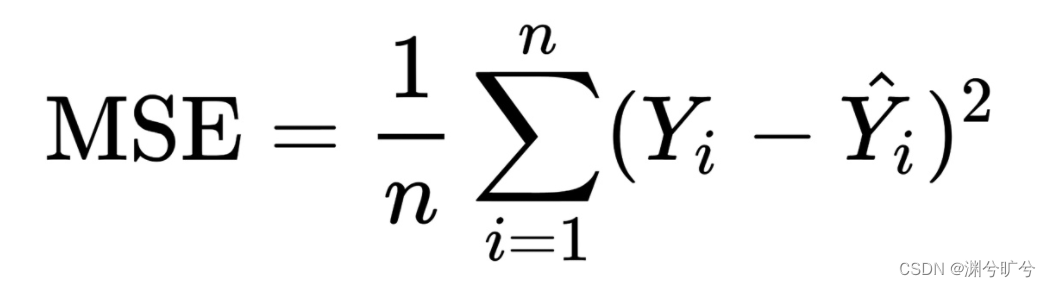
PS:均方误差从数学含义上,它会放大误差>1的的部分的比重,缩小误差<1的部分的比重,这就意味着,使用均方误差来作为误差函数,会更加重视误差较大的部分,会轻视误差较小的部分,我们选择误差函数时,需要根据实际来考虑是否适用
这里简单举一个1维的例子,n取1
#权重参数
knob_weight = 0.5
#输入数据
input = 0.5
#实际预测值
goal_pred = 0.8
#预测值
pred = input * knob_weight #=0.25
#误差
error = (pred - goal_pred) ** 2二、均方误差的计算方法
在实际问题中,我们通常采用以下步骤来计算均方误差(当然可以选择其他的误差函数,但基本都是这个套路):
- 将数据集分为训练集和测试集;
- 使用训练集训练一个回归模型;
- 使用测试集进行预测,得到预测值;
- 计算预测值与实际值之间的差异;
- 将所有差异的平方相加,然后除以样本数量得到均方误差。
三、均方误差的代码实现
实际上,我们在训练模型中,均方误差的参数以及输入往往是一个n*m的矩阵,在pytorch,tensflow等框架中,也提供了简单的调用代码,可以便捷设定使用均方误差法来评估神经网络的准确性,下面我会一一介绍使用方式。
numpy,以及pandas实现
import numpy as np
import pandas as pd
#创建一个实际值矩阵
actual = np.array([[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7],
[4, 5, 6, 7, 8],
[5, 6, 7, 8, 9]])
#随机生成一个5*5的矩阵,数字随机在0-9中选取
predicted = np.random.randint(0, 10, size=(5, 5)
#np实现
mse_np = np.mean((actual - predicted) ** 2)
#pandas实现
mse_pd = ((actual - predicted) ** 2).mean()
实现效果
pytorch使用MSE
import torch
import torch.nn as nn
# 真实输出
output = torch.randn(10, requires_grad=True)
# 预测输出
target = torch.randn(10)
#定义一个线性模型
model = nn.Linear(10, 10)
# 计算模型的输出和目标之间的MSE
criterion = nn.MSELoss()
loss = criterion(model(output), target)
print(loss)
tensflow使用MSE
import tensorflow as tf
import numpy as np
# 创建模拟数据
X_train = np.random.rand(100).astype(np.float32)
Y_train = X_train * 0.1 + 0.3
# 定义模型
class LinearModel(tf.keras.Model):
def __init__(self):
super(LinearModel, self).__init__()
self.dense = tf.keras.layers.Dense(1)
def call(self, inputs):
return self.dense(inputs)
#实例化这个模型,并编译它,使用MSE作为损失函数
model = LinearModel()
model.compile(optimizer='sgd', loss='mean_squared_error')
# 使用我们的模拟数据来训练模型
model.fit(X_train, Y_train, epochs=50)


















 4964
4964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











