







引言:
深度学习是一种强大的机器学习方法,它在许多领域中都取得了显著的成功。在深入探讨深度学习之前,我们需要了解几个重要的概念,包括监督学习、无监督学习、参数模型和非参数模型。本文将对这些概念进行简要概述,并通过图解的方式帮助读者更好地理解它们。
1.监督学习:
监督学习是机器学习中最常见的形式之一。
监督学习是一种将一个数据集转换成另一个数据集的方法,通俗的来首就是通过监督学习,可以将你知道的转换成你想知道的。
举个小例子:我们知道了过去10年的每周一的股价以及同一时段内的下周二的股价,那么我们就能通过训练好的神经网络,通过输入本周一的股价来预测下周二的股价。

2.无监督学习:
无监督学习是一种机器学习范式,不需要标记的训练数据。
无监督学习和监督学习都是将一个数据集转换成另一个数据集,(在训练模型建立模型中)但它转换的数据集并不是已知的。如果说监督学习是建立输入-输出之间的映射关系,那么无监督学习就是发现隐藏的数据中的有价值信息,如:有效特征、类别、结构、概率分布等。
聚类就是一种经典的无监督学习,聚类算法就是将一些列数据点转换成对应的一系列类别标签。举个小例子如下图:我们给出了几个词语,如果已经学习到了生物、食物两个类别,那么它就会转换成一系列“1”、“2”的标签。

无监督特征学习一般用来进行降维、数据可视化、监督学习前期的数据预处理。
3.参数模型:
参数模型是一种通过学习参数来表示数据分布或函数关系的模型,其具有固定数量的参数
在参数模型中,模型的结构是固定的,但参数的值可以根据训练数据进行调整。
参数模型更倾向于试错法。
典型的参数模型包括线性回归、逻辑回归和神经网络等。
4.非参数模型:
非参数模型是一种不依赖于预定义参数数量的模型,其参数的数量是无限的。
非参模型的参数个数是由数据为基础(而非预先定义好的),这也就通常适用于以某种方式计数作为输入的方法。非参数学习能够根据数据中惨在的具体项目数量相应增加参数的数量,故而非参数模型的灵活性更高。
举个小例子:假设我们要观察某个街道某个街灯与汽车行驶的关系,我们回收机到以下信息,然后模型就能预测出中间的灯光总是会导致汽车行驶,而右边的灯光只有50%的概率导致汽车行驶。(ps:这看上去像是一个参数模型,但若是我们在观察之前并不知道灯的数量,那么就无法使用固定参数数量的模型去进行预测了)
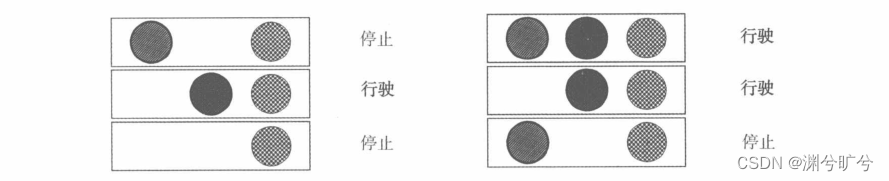
典型的非参数模型包括决策树、支持向量机和高斯过程等。
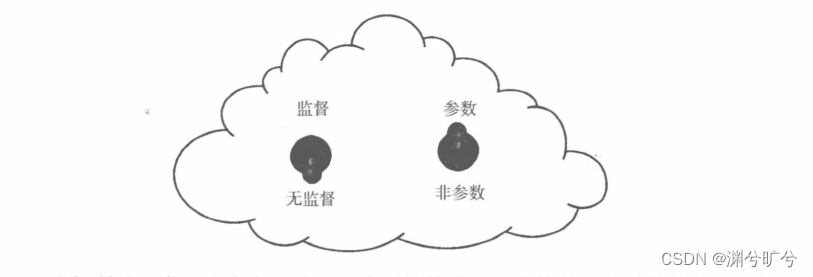
四种不同类型的算法:
我们可以在脑海里想象一些一个机器学习云,它可以由两个开关来拨动,实际上也就存在了四种不同类型的算法:监督参数学习、无监督参数学习、监督非参数学习、无监督非参数学习。
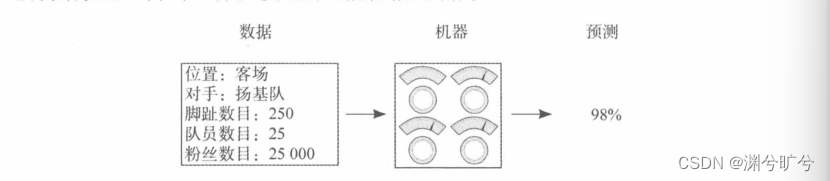
这里简单举两个小例子来辅助理解吧:
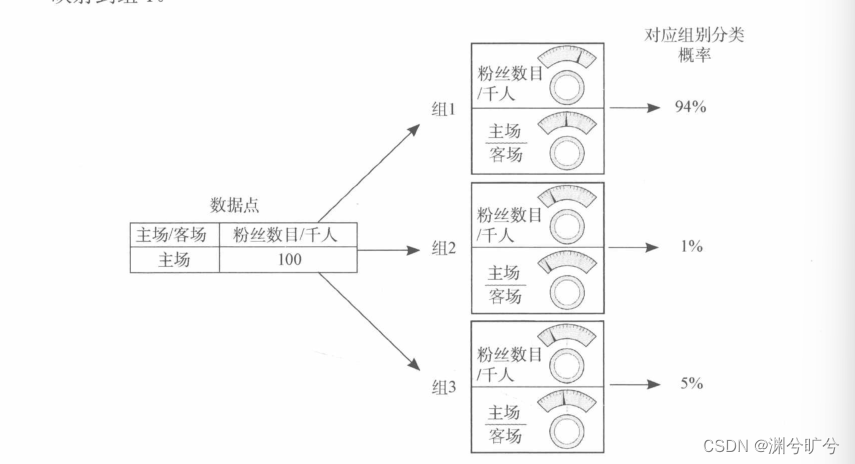
监督参数学习:我们输入固定的5组参数来预计某一个队伍的胜率。
无监督无参数学习:我们获取了固定组数的数据(每个场地的对决表),我们假设要将它分成3组

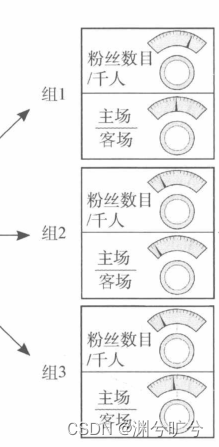
我们不妨用组1组2组3来标注它们,现在让门传入一个数据点,无监督参数模型会根据输入的数据做出分组预测,如下图:很明显,组1的概率最大


















 2543
2543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











