









作者:François Petitjean、Jordi Inglada、Pierre Gançarski
发表期刊:IEEE Transactions on Geoscience and Remote Sensing (IF 8.125)
目录
2) Compression-Based Dissimilarity Measure
3) Levenshtein Distance / Edit Distance
4) Longest Common Subsequence(LCSS)
1、DTW Versus Multidimensional Sequences
2、Avoiding Inconsistent Temporal Distortions
3、Handling Cloud-Contaminated Images
3、两个年份(2007和2008)之间的 Domain Adaption
背景
DTW(Dynamic Time Warping,动态时间规整),由Sakoe H等人发明于语音识别领域:1971年《A dynamic programming approach to continuous speech recognition》;1978年《Dynamic programming algorithm optimization for spoken word recognition》。
遥感影像时间序列(SITS)应用 所面临的问题
SITS(Satellite Image Time Series,遥感影像时间序列):一种在空间和时间上都高度结构化的数据。空间结构指 像元的坐标(x, y),是识别不同区域、比较不同值的基础。时间结构指 数据获取时间 或 获取数据的时间顺序。
(a) reference data
参考影像难以实时更新。
解决方法:使用非监督方法 / 将历史数据当做现实参考
(b) irregular sampling (由sensor引起的)
时间上的采样频率的稳定性较差。比如:如果每个季节只有一张影像,则在采样时间段内几周的扰动对结果的影响很小;但若每个月有几张影像,几周的扰动对结果的影响就会很大。
因此,处理SITS的算法必须考虑到采样频率的不规律性,才能充分挖掘可用的数据。
(b) pseudo periodic phenomena (由observed objects引起)
很多phenomena of interest会被外界环境的变化扰动,使得 观测到的物理变量的temporal behavior与canonical temporal profiles不同。
比如,植物生长周期理论上有一些阶段性行为,但这些行为会受天气、人为扰动等的影响,这些影响使得实际的植物生长行为与理论行为产生偏差,使得观测到的NDVI时序与理论有偏差。
因此,处理SITS的算法最好对时间上的扭曲不敏感(have some kind of invariance to temporal stretching or dilation)。
时间维度的使用方式
根据 使用时间维度的方式,对方法进行分类,可以描述time structuring的不同级别。例子:image differencing只利用了一些影像的顺序,frequency analysis:利用了整个序列的顺序。
本文旨在定义一个 既可用于 abrupt 变化分析、也能用于 long-term 变化分析 的时间序列描述器(descriptor);因此,不区分 bidate 和 multidate 方法。
记号: t1, t2,…,tn 表示 image 1, image 2, … , image n
< 表示 影像的时间顺序
f 是一个 输入2张影像、输出1张影像 的二值函数。
1) Time as identifier
时间只是一个用于区分数据的属性,序列中的影像之间没有顺序。这类方法通常会将 几张不同的影像 合成 一张有许多属性的影像。
优点:使用简单;可以解决(b) irregular sampling。
缺点:没有挖掘时间行为;有些区域 可能仅仅因为某些事件的频率不同 就被孤立;打乱影像的顺序 不会影响结果。
a) Data linear transformation
基于统计学理论。比如,主成分分析、最大自相关因子。
b) Classification
对合成后的影像使用一些分类算法,比如K-means、Expectation Maximization。
c) Change detection methods based on classification comparison
先对每个影像单独进行分类,再将各张影像结合,以产生一个分类结果。
优势:不需要影像之间存在可比较的radiometric levels (如 辐射标准化) 即可使用≥2张影像。
2) Pairwise time ordering
利用时间成对地structure影像:t1 < t2 , … , tn-1 < tn
这类方法刚开始用于bitemporal分析,后来扩展到multitemporal。扩展方法一般是多次应用,比如:f( f(t1,t2), f(t3,t4) )、f( f( f(t1,t2), t3), t4)。
缺陷:① 先应用到 (t1,t2)、再应用到 (t3,t4) 时,并未利用 t2和t3 之间的顺序。
② 多次应用会有风险:结果取决于 f 的性质,多次应用可能放大 f 的缺陷。
a) Difference / Ratio / Combination
按照时间顺序组合t和(t-1)影像,组合方式可以是 减法、除法 或 更复杂的方式。通常,会对 组合后的影像 进行 thresholded或classified,从而识别变化区域。
b) Change Vector Analysis
用change之前和之后的2个multiband值,在多维空间中建立1个vector。这个vector的norm和angle,表现了change的type和intensity。
norm:范数,具有“长度”概念的函数。赋予 矢量空间内的所有矢量 非零的正长度或大小。
Change Vector Analysis 是为双时相数据设计的,且只能用于双时相。
此类方法认为 t 时刻 与 t-1 时刻 的数据线性相关。回归的参数(residual)用于表征change。
有研究表明,Linear Regression一般没有image differencing效果好。
3) Time ordering the sequence
利用时间structure整个序列:(t1<t2) ∩ (t2<t3) ∩ … ∩ (tn-1<tn) ⇔ t1 < t2 … tn-1 < tn
a) Frequent pattern mining
此类方法提取了radiometric evolutions的frequent subsequences。
优势:对噪声不敏感,提取了有意义的patterns。
缺点:产生了很多很多patterns,过滤出有效信息较为困难。为了缩小搜索范围,需要进行一个discretization步骤。该步骤对理解序列至关重要。
b) Frequency analysis
使用Fourier或小波变换,对radiometric time series进行decomposition。
优势:可以handle整个时序,且较为稳定。
缺点:必须对时序进行 regular sampling,即 采样的时间间隔必须保持不变。
如果不要求 regular sampling,使用观测值的总体顺序,与 对每个观测区域的evolution behaviors 进行分析,所得的结果,似乎是一致的。
时序的相似性度量
要求:① 使用了所有可用的观测数据
② 可用于数字值(numeric values)
③ 可以捕捉时间行为,比如 shifts、distortions
④ 可用于时间采样不规律的序列
⑤ 不需要额外参数(parameter free)
⑥ 结果容易理解
记号:A = <a1, a2, ... , aT>、B = <b1, b2, ... , bT> 分别表示两个序列。
δ 表示来自两个序列的两个元素之间的距离
1) Euclidean Distance
![]()
缺点:欧式距离不能捕捉到一些灵活的相似性,不能理解时间序列。比如,X=<a,b,a,a>和 Y=<a, a,b,a>表现了相似的进化特征,但根据欧式距离,X和Y是不同的。
2) Compression-Based Dissimilarity Measure
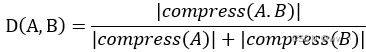
上式中,A.B 是 A和B的concatenation,|compress(A)|![]() 指压缩后文件的大小。
指压缩后文件的大小。
由 E. Keogh 等人于《Towards parameter free data mining》提出。其理论基础是 A. N. Kolmogorov 于文章《On tables of random numbers》中提出的 Kolmogorov complexity。
缺点:距离的效果强烈依赖于压缩算法的选择。且压缩算法是个黑箱,该距离较难理解。
3) Levenshtein Distance / Edit Distance
由 V. I. Levenshtein 于文章《Binary codes capable of correcting deletions, insertions, and reversals》提出。
编辑距离将两个符号字符串(symbol string)之间的距离概念形式化。通过对单个符号(symbol)进行一系列编辑操作(edit operations),将一个字符串(string)转换成另一个字符串。编辑操作包括 插入、删除、替换某个symbol。
优势:可以理解 <a,b,a> 与 <a, a,b,a> 接近(通过插入或删除一个 a),可以理解时间序列。
缺点:不能用于数字值。且需要定义 插入、删除、替换symbol 等操作的cost。
4) Longest Common Subsequence(LCSS)
最初用于寻找两个字符串之间最长的公共子序列。后来由M. Vlachos 等人衍生到数字序列:《indexing multidimensional time-series》。
优点:可以跳过被云污染的值
缺点:需要定义“common”的含义。由于着重于寻找公共子序列,该方法会遗忘一些观测值;如果被忽视的值恰好很有用,就会遗失有效信息。
对 相似性度量方法 的评价:
a) 应用角度:上述方法不太适用于遥感时序。欧氏距离没有考虑数据的时间性质,基于压缩的方法计算昂贵、难以理解,编辑距离只能用于符号序列,LCSS没有利用到全部数据。
b) 理论角度:本文关注的是基于距离对整个SITS进行分析,大多基于距离的方法(如K-means)需要计算距离的平均值。上述方法只有欧氏距离可以计算平均值。
DTW 介绍
DTW 是一种 对每个元素的时间演变行为进行分析,并将其与其他元素的演变行为进行比较 的 全局分析方法。
DTW 满足 “时序的相似性度量”的要求:可以分析整个数据集的时间特征,不会跳过任何值;能够挖掘temporal distortions、比较shifted / distorted profiles;由于optimal alignment of radiometric profile,允许时间采样是 irregular的;无需额外参数。
注意:DTW对尖锐的噪声(spiky noise)很敏感,用于微波影像前必须去除speckle noise。
DTW会找到两个序列之间的 最佳全局匹配(optimal global alignment),并提供一个度量这两个序列 总体相似性 的实数值。
DTW通过匹配两个序列中各元素的坐标,捕捉一些灵活的相似性。具体来说:序列中的每个元素,都会和 另一个序列中至少一个元素 关联。
最佳匹配的 cost 通过下式递归计算:

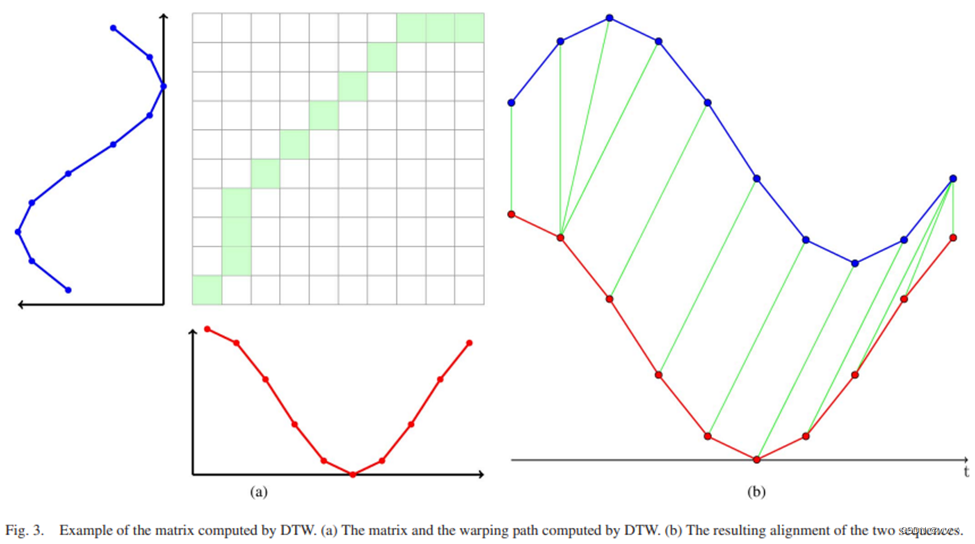
DTW 需要计算 A与B 的 匹配(alignment)和 对比(comparison)。DTW 使用dynamic programming 的原则,允许将重叠的子问题记录到一个 S×T![]() 的代价矩阵中,如上图所示。
的代价矩阵中,如上图所示。

具体算法如上图所示。 首先,分别对矩阵的第一行和第一列初始化;然后,从左到右、从上到下(上图的矩阵是向左旋转了90°的结果,所以应该是从下往上、从左往右计算)计算矩阵中剩下的元素,每个元素的值都是该元素与其左、上、左上元素的cost中的最小值。整个矩阵都计算完毕后,右下角最后一个元素即为这两个序列最佳alignment的分数。
如果直接将这种递归定义应用到某个算法中,不仅时间cost 特别大;还会出现 overlapping subproblem 问题:DTW 允许记录部分结果,这会导致,即使最小的权重耦合,也会包括 |A|×|B| 的计算。该方法的 时间和空间复杂度 可达 ![]() 。
。
将 DTW 应用于 遥感 需要考虑的问题
1、DTW Versus Multidimensional Sequences
本文将 SITS中一个像元的值 作为 描述一片观测区域的evolution的序列的一个元素。
原始的DTW适用于一维数据(声音信号),即每个元素都可以在一个一维空间中进行描述。然而,在进行SITS分析时,每个元素都是一个多波段像元(多维向量)。
两种通过DTW比较多维序列的方法:
① 一次计算一个波段(一个维度),计算n次DTW。
将 SITS 看成 n 个一维序列,每个子序列为一个波段。此时,算法会分别匹配每个波段,产生 n 个匹配结果。损失了 “一个像元 n 个波段值” 的同步性信息。
② 在计算DTW时,使用一个n维的距离度量。
将 SITS 看成一个序列,其元素是n维的。此时,算法只会产生一个匹配结果,保留了像元的同步性信息(维持了像元的原子性)。
注意:该情况下,δ 必须采用一个能够比较n维向量的距离度量。
2、Avoiding Inconsistent Temporal Distortions
有时,专家可能希望引入专业知识。比如,确保冬季和夏季的作物不相似(时间间隔超过两个月即视作不相似)。
以往研究的本质目标是减小计算复杂度。通过给warping path加global constraints,防止两个元素的alignment太远,从而限制alignments。
将warping path的搜索范围缩小到矩阵的一个子集中,该子集称为warping window。warping window可以是矩阵对角线周围的某个带(Sakoe-Chiba band);也可是某个平行四边形(Itakura Parallelogram),平行四边形可以允许序列中间部分的变形大于边缘部分。
但是,由于SITS是irregular sampled的,这种global constraints并不适用。
比如,Sakoe-Chiba band会将离矩阵对角线太远的元素都移除。若 i-j>ω![]() (ω
(ω![]() 是带宽),则元素(i,j)
是带宽),则元素(i,j)![]() 不会是warping path的一部分。那么,如果 第1个序列的第 i
不会是warping path的一部分。那么,如果 第1个序列的第 i![]() 个元素 和 第2个序列的第 j
个元素 和 第2个序列的第 j ![]() 个元素 之间的距离大于 ω
个元素 之间的距离大于 ω![]() 个元素,它们就不能关联。
个元素,它们就不能关联。
Sakoe-Chiba band只能用于 time delay固定的情况,即regularly sampled序列;因为它们的元素个数具有时间意义:ω![]() 个元素的时长=ω×
个元素的时长=ω×![]() time delay 。
time delay 。
对于time delay可变的SITS,“所有元素的距离小于 ω![]() 个元素”没有时间意义。因为两个连续元素的time delay(两张连续影像的观测时间间隔)可以是一周、一个月、甚至一年。
个元素”没有时间意义。因为两个连续元素的time delay(两张连续影像的观测时间间隔)可以是一周、一个月、甚至一年。
本文 引入 constraints 的主要目标是 避免inconsistent temporal distortions,减小计算复杂度只是一个附加优势。
本文提出以下改动:给定最大time delay为 ∆t,搜索范围 满足下式:
DateDiff( Date(i), Date(j) )< ∆t
上式中:Date(i) 表示第1个序列的第 i 张影像的观测时间,Date(j) 表示第2个序列的第 j 张影像的观测时间;DateDiff 是一个函数,返回值是两个日期之间的间隔时间(elapsed time)。
注意事项:① 确保warping path存在;即:warping window由单个部分构成。
② 为了匹配更复杂的先验知识, ∆t 是可变的。
在实际操作中,在计算矩阵的每个元素之前,必须先评估上述条件:满足条件,则照常计算;不满足条件,则将该元素的值设置为+∞。这效果相当于 给矩阵加一个mask,使得计算warping path时必须在给定的warping window中。该mask与遥感影像的观测日期一致,可以适用于时间采样不规律的数据。
3、Handling Cloud-Contaminated Images
在使用单幅遥感影像进行分类时,由于结果一般会剔除云覆盖区域,被云层覆盖的像元不会对结果造成很大影响。
在处理SITS时,由于原子数据(atomic data)是某个区域的 辐射值序列,云污染影响很大。
假设一个像元被云覆盖的概率是一个常数:![]() 表示观测区域 p 没有云层覆盖的概率。那么,序列S 没有云层覆盖的概率为
表示观测区域 p 没有云层覆盖的概率。那么,序列S 没有云层覆盖的概率为![]() 。由此可见,即使一个像元被云覆盖的概率很小(一个像元没有云覆盖的概率很大),该像元的一整个序列都没有云覆盖的概率仍然很小。
。由此可见,即使一个像元被云覆盖的概率很小(一个像元没有云覆盖的概率很大),该像元的一整个序列都没有云覆盖的概率仍然很小。
三种处理云覆盖的方法:
① 保留被云层覆盖的值:会增加噪声。
② 剔除主要的被云层覆盖的影像:删除的影像中可能会包含没有云覆盖的像元,没删除的影像中可能存在云覆盖像元(类似①会增加噪声)。
③ 只剔除被云层覆盖的值:保留了所有的无云值,但可能导致 各个像元的序列长度不同。此时,就需要一个能够比较不同长度(不同时间采样)的序列的相似性度量。DTW 可以比较不同长度和采样方式的两个序列,同时寻找到两个序列的最佳耦合。DTW的realign能力,可以处理时间轴上的非线性失真。
DTW在遥感中的应用实例
数据信息:
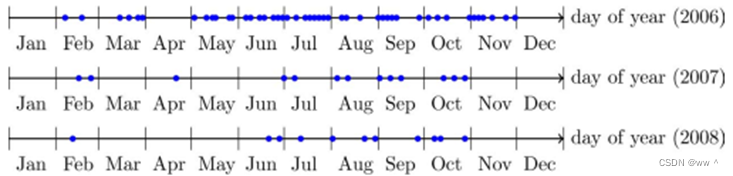
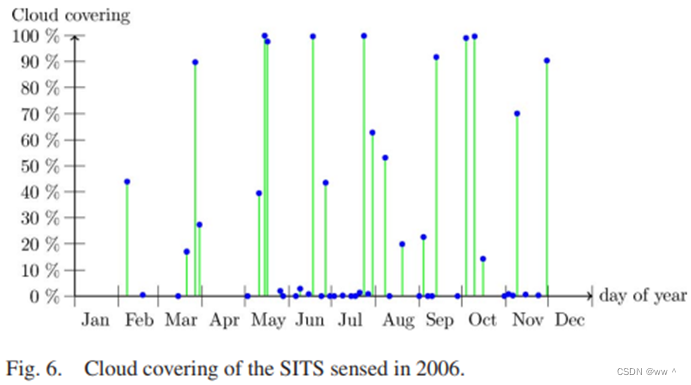
研究区域位于法国西南部的图卢兹镇附近。共70张Formosat-2卫星影像,时间分布如下图所示。 46张2006年云覆盖很多(30%);13张2007年 和 11张2008年的数据基本没有云层覆盖(<3%)。
影像的空间分辨率为8m。用到了多光谱数据的 3个波段:近红外、红、绿(蓝波段关于植被的信息很少,且对大气状况十分敏感,易受污染)。
预处理:
(1)正交校正(orthorectify):保证每个像元(x, y) 在整个时间序列中覆盖同样的地理区域。
(2)辐射标准化:保证整个时序中各张影像的辐射值具有可比性。包括 将传感器提供的数字值转换为物理量、大气校正 等操作。
首先,根据仪器的辐射模型,将数字值转换为反照率(一种太阳辐射的归一化物理量)。
其次,通过对比真实反照率与模拟反照率,将反照率转换为表面反照率。
模拟反照率是为了获取测量的大气和几何条件,在大气层顶部模拟得到的。在考虑了大气压力、气溶胶含量和水蒸气含量的影响后,对各种高度都进行了模拟。
观测时的实际大气情况通过 气象(NCEP:压力、湿度)、臭氧(TOMS\TOAST)、气溶胶(SeaWiFS、Aeronet)和 气候值(climatological)等数据源获取。
时序的构建:
每张影像高H、宽W、波段数为B,每张影像都可以看作一个函数![]() 。序列
。序列![]() 由N张影像构成,是影像中各像元对应的一系列元组(NIR, R, G)。
由N张影像构成,是影像中各像元对应的一系列元组(NIR, R, G)。
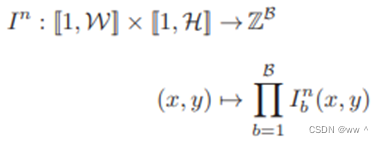
![]()
每张影像 In 都与一个云掩膜(cloud mask)相对应,云掩膜定义了被云污染的地理范围。如果某个像元被定义为云污染,则它会被剔除/跳过。
实验设置:
i. 两个像元(坐标)之间的距离度量为squared Euclidean distance。
ii. DTW的平均方法是DBA和AS的结合。
AS:adaptive scaling。出自 F. Petitjean 等人的《A global averaging method for dynamic time warping, with applications to clustering》 。
iii. 使用 Kappa系数 评估结果
![]()
其中,Pr(a) 表示两个对象的相对一致性;Pr(e) 表示 hypothetical probability of chance agreement,通过观测数据来计算每个观察者随机选择魔偶各类别的概率。

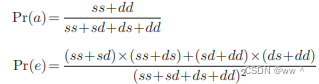
实验
1、使用2006年的数据进行聚类
目的:使用DTW处理长度不同的序列
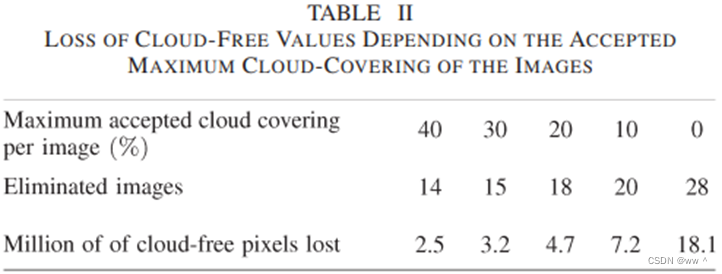
由上表可见,如果只保留云覆盖<20%的影像(方法②),会去除大量影像,损失大量无云影像。因此,只去除有云的像元(方法③),得到各个像元的时间序列。根据参考地表覆盖图中的地类数量,将这些时间序列分成24个聚类。
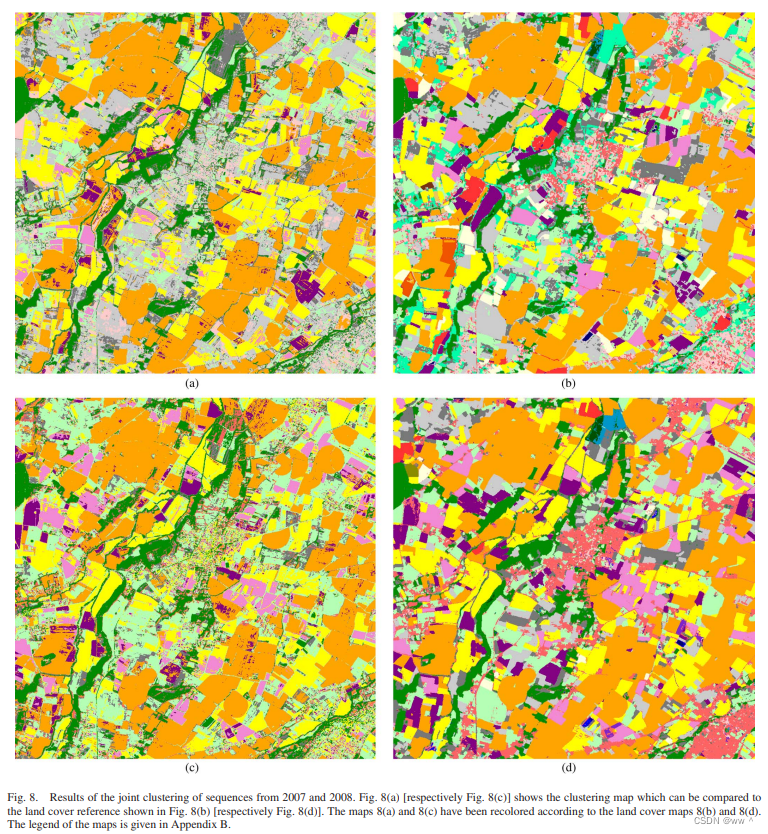
研究了两种情况:(a) 无限制。(b) 限制最大time delay为2个月。结果如下图,(c)为参考地表覆盖图。


结果:(a) 的Kappa系数为86.9%,(b) 的Kappa系数为87.2%。由上图可见,两种DTW都存在 meadow和fallow 的混分,(a) 额外存在 wild land和forest 的混分。
2、同时使用2007年和2008年的数据进行聚类
没懂啥叫同时聚类,贴个原文:


3、两个年份(2007和2008)之间的 Domain Adaption
经典 Domain Adaption 从一张影像学习分类,用于对另一张影像进行分类;一般在第一张影像上学习时,为了提高模型精度,会用到外部知识。本研究 从2007年的影像学习分类,应用到2008年;不添加额外知识。
难点:如何使得两个序列具有可比性。
具体步骤:
(1) 通过 K-means 由2007年影像 获取25个聚类。
(2) 对每个聚类:
(a) 根据参考土地分类图的地物类型,计算该聚类的分布(直方图);
(b) 对每个 出现在该直方图中的、大于该影像1%(1000 个像元)的地物类型,都建立一个新的中心点(对涉及到的序列进行平均)。
(3) 为2008年影像分类,将每个序列分类成和它距离最近的中心点所对应的地物类型。
结果:与2008年的参考地物类型图比较,Kappa系数为84%.其中,corn 分类效果很好,不过存在 corn和soybean 的混分。此外,与上一个实验结果类似,存在 urban和wheat 的混分现象。
结论
本研究主要解决了SITS应用的两大问题:① irregular sampling in the temporal dimension;② the need for comparison of pairs of time series having different number of samples。
实验1 展示了DTW 处理云污染 和 根据专家知识限制搜索范围 的能力。实验2 显示了DTW如何在同一个区域上同时聚类两个数据集。实验3 属于domain adaptation。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









