









摘要
图像分割的本质是像素级别的分割。广泛应用于医疗成像、自动驾驶领域等。
图像分割的类型:
普通分割:将不同类别不同物体的像素区域分开,比如分开前景和后景。
语义分割:在普通分割基础上,分类出每块区域的语义(什么物体)。将画面中所有物体都指出各自的类别。
实例分割:在语义分割的基础上, 识别并给出每个相同的物体的编号。
FCN
普通CNN网络用于输出图像级别的分类和回归任务。它的尾部是全连接输出固定的值。而FCN将CNN最后一层全连接层替换为卷积层,输出一张Label好的图片。这种结构就是一种编解码的结构。但是FCN得到的结果还是不够精细,上采样的结果还是比较模糊和平滑,细节敏感性低。concat不够,应用了池化,像素位置有问题。

基于FCN框架的UNet
采用FCN的思想,四个下采样提取目标特征,再通过四个上采样,最后逐个对其像素点进行分类,那么这实际上是一个基于编码器(encode)-解码器(decode)思想。
网络模型结构:

下采样方法(压缩图像的特征):使用大步长的卷积;池化;使用Padding的卷积。
上采样方法:像素插值(双线性插值、邻近插值——信息丢失少,速度适中),反卷积(转置卷积T.conv——参数少,速度快),反池化(Unpooling),像素融合(通道信息平铺,不丢失信息)
在Unet中使用了转置卷积实现上采样,在Unet中每一个上采样Block里,运用了一个跳连接把前面一部分特征Concat到了上采样后的特征图上。(思想类似ResNet),目的是使上采样后的特征图有更多的浅层语义信息,增强分割精度,在最后一层直接使用sigmoid二分类把mask分为前景和背景。
损失函数:常见的图像分割损失函数有,Binary crossentropy(BCE),Dice coefficient,Focal loss(解决类别不平衡)。Unet使用如下的损失函数。

存在的问题:网络是固定层数,对不同的分割需求是冗余的。可以改进模型结构,适应不同的分割需求。
UNet ++
论文:https://arxiv.org/abs/1807.10165
UNet++根据UNet模型的结构进行优化。可以把UNet++看成多个不同深度,不同池化的Unet 的集合模型。提出了Deep Supervision 深监督,作用类似辅助loss,可以加快模型收敛速度。在训练时是集合训练,在测试使用时,可以通过不同剪枝来选择更简单合适的模型。

两个问题:
为什么UNet++可以剪枝?
模型是长连接加短连接,所以每一层都可以单独剪下来去使用,结构决定。
如何剪枝?
应用了一个深监督模型1*1的卷积,监督他每一层的输出,都要去训练单独使用。
好处:适应各种简单或复杂的任务。
为什么测试时剪枝?而不是剪枝后再去训练?
剪完枝后去训练没有共同促进的作用,而且剪完训练后使用也更复杂,无法判断哪个模型适应哪个任务,只能主观判断。而测试的时候剪枝可以通过模型的dice系数在哪一层的效果最好去决定。
DeepLab v1-v3
论文:
V1 https://arxiv.org/pdf/1412.7062v3.pdf
V2 https://arxiv.org/pdf/1606.00915.pdf
V3 https://arxiv.org/pdf/1706.05587.pdf
V3+ https://arxiv.org/pdf/1802.02611.pdf
DeepLab系列使用了空洞卷积,ASPP结构,Encoder-Decoder(编解码)结构,CNN与PGM(概率图模型)结合,。
空洞卷积:

这里的Input stride理解为空洞的洞的大小,这里洞为1,在3x3的卷积核下,使用了Input stride使原本3x3的卷积核有了5x5大小的感受野,但是原始卷积核还是没变。
ASPP结构:

目的是通过不同的比例rate构建不同感受野大小的卷积核,来获取多尺度的物体信息。
CRF:
在V3中,作者把解决多尺度的问题的方法分为4类:
图像金字塔、编解码、网络层最后加入其它模块如DenseCRF或串联不同感受野大小的卷积、在网络层最后并行空间金字塔池化模块获取不同尺度物体信息。

V3在实验中主要做了两个改进:
使用残差网络结构时通过串联结构,做到了更深的空洞卷积;
优化了ASPP。
V3+:
把原DeepLabv3当作encoder,添加decoder得到新的模型(DeepLabv3+),也就是把ASPP模块与E-Dcoder融合为一体。使用了深度可分离卷积和膨胀卷积。
网络结构:

在Encoder部分使用空洞卷积,得到多尺度的特征图,再将这部分拼接在一起后使用1x1的卷积,将通道变小后上采样(使用双线性插值)输入Decoder。
在Decoder部分先将前面的低维度特征通过1x1卷积变换通道后,将Encoder的输出拼接。使用3x3的卷积、上采样输出。
由于普通卷积学习的是像素之间的关系,具有平移不变性,而在这里用在图像语义分割上不好。而平移同变性指位置发生变换,相应的侦测输出也会变化。我们希望图像分割任务能够及时响应物体位置的变化。
同一个像素在同一图像上,在某一位置是前景,而在另外一位置可能变成了后景。在不同的位置具有不同的语义信息。
高级语义:抽象程度高,用于检测分类回归任务。
低级语义:像素点的定位。
Mask-RCNN
以Faster RCNN原型,增加了一个分支用于分割任务。所以这个模型同时包含了检测分类回归分割任务,当然单对于分割任务有些冗余。
使用ROI Align替代ROI Pooling。
图像分割评估指标
DICE 系数:
取值:[0,1]
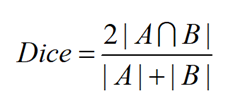
Jaccard 系数
取值:[0,1]
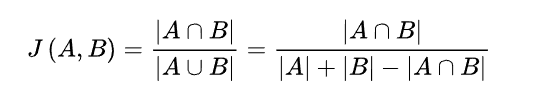















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









