







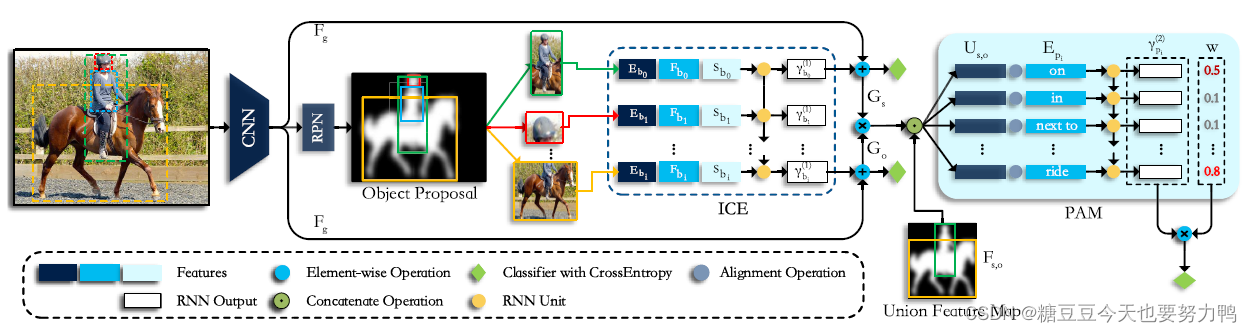
整个网络结构可以分成两部分,先说前半截:
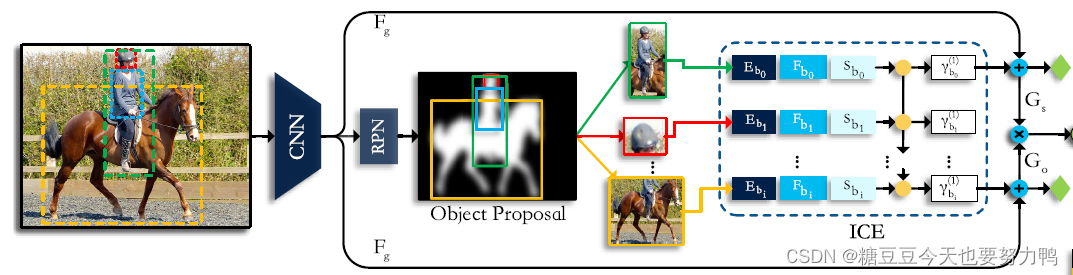
深蓝、蓝、浅蓝三种颜色表示的特征分别为class embedding、spatial info、visual feature,cat后线性变换一下,得到特征V
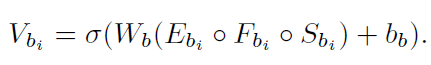
之后再对整幅图像的所有主客体对计算出的V经过RNN,得到实例级别的上下文
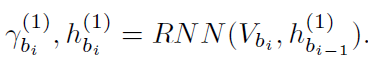
整幅图像经过CNN提取的feature map线性变换一下,作为场景级别的上下文,然后与实例级别上下文相加得到融合上下文G,最终物体的类别由融合上下文得到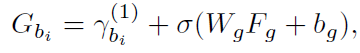
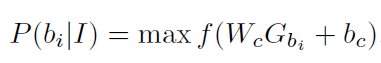
后半截:
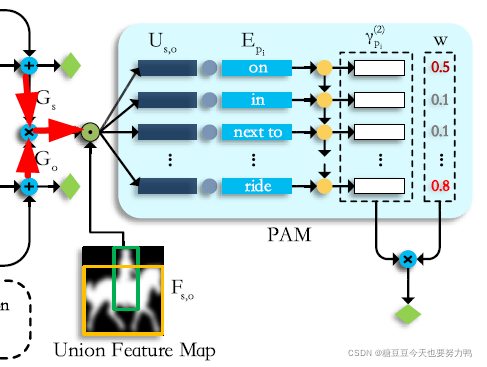
红色箭头即为输入特征的计算方式:
主客体的上下文和union feature map的融合,得到U,即融合特征
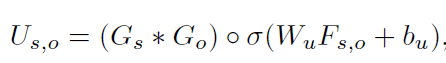
然后把融合特征复制n份,分别与不同谓语的word embedding特征cat在一起,得到对齐特征R
这n种对齐特征输入RNN,得到n种谓语上下文特征
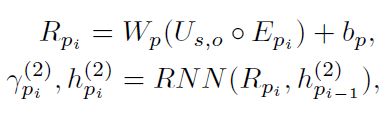
由于不同的谓语对最终的上下文影响不同,使用了注意力机制,最终的谓语上下文特征是这n种上下文的加权
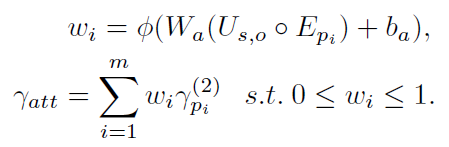
谓语分类取决于谓语上下文特征:
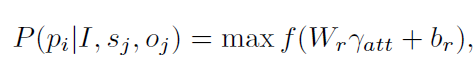
------------------------------一些碎碎念-----------------------------
妈妈上班去了 要3月才能回来。
15551

















 1210
1210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









