







一、语言模型
是衡量一句话的合理性大小的一种表示。

链式法则
在做语言模型时,往往会遵从下面的一种法则,依据条件概率学,每后面的一个单词是基于前面的单词出现的概率。
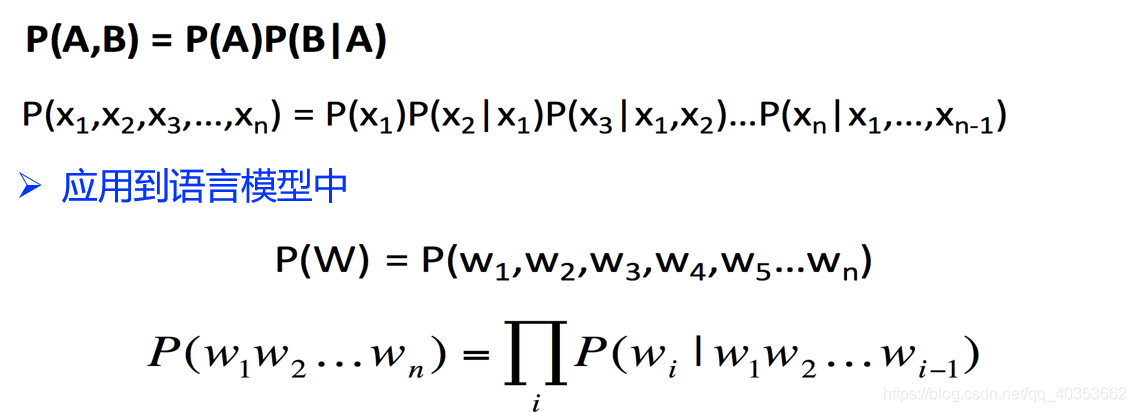
马尔可夫假设
后面的单词往往只基于前面的n个单词,至于n+1,n+2个单词就忽略不计了。

语言模型的评价
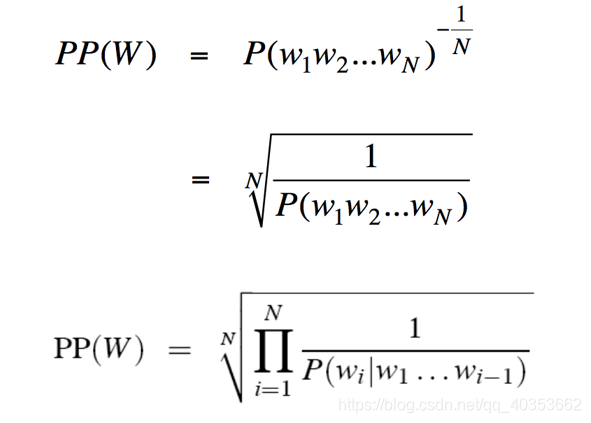
基于神经网络的语言模型(Neural Language Model)

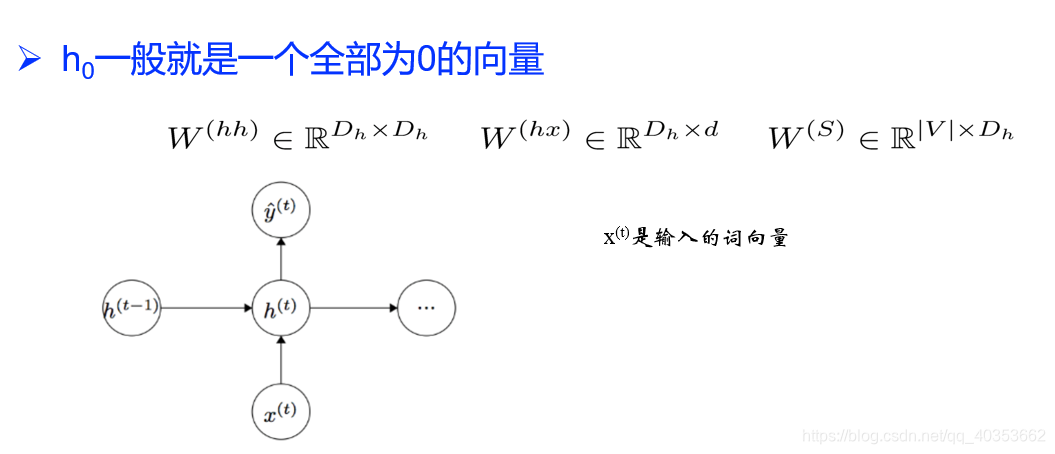
循环神经网络(Recurrent Neural Network)


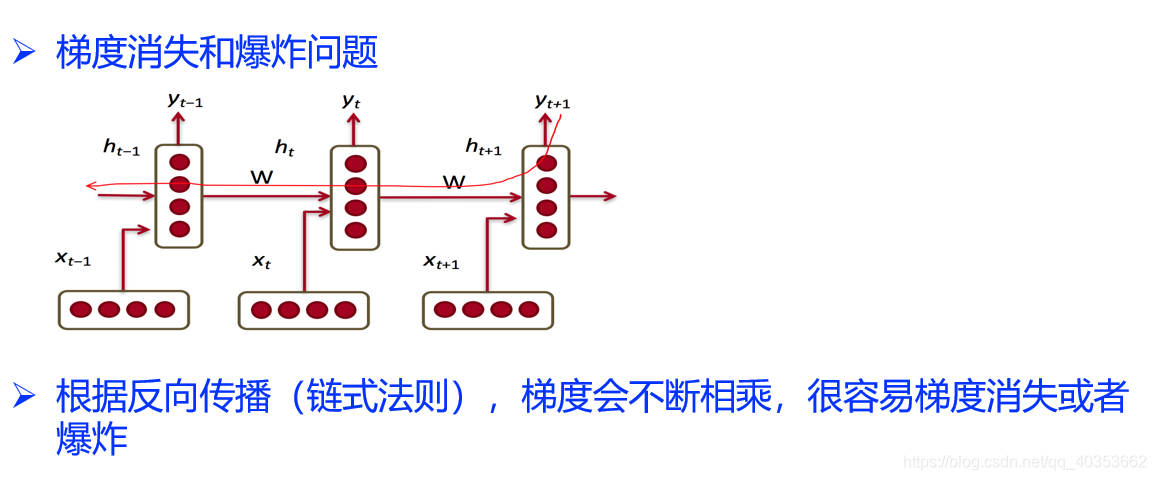
训练RNN很难
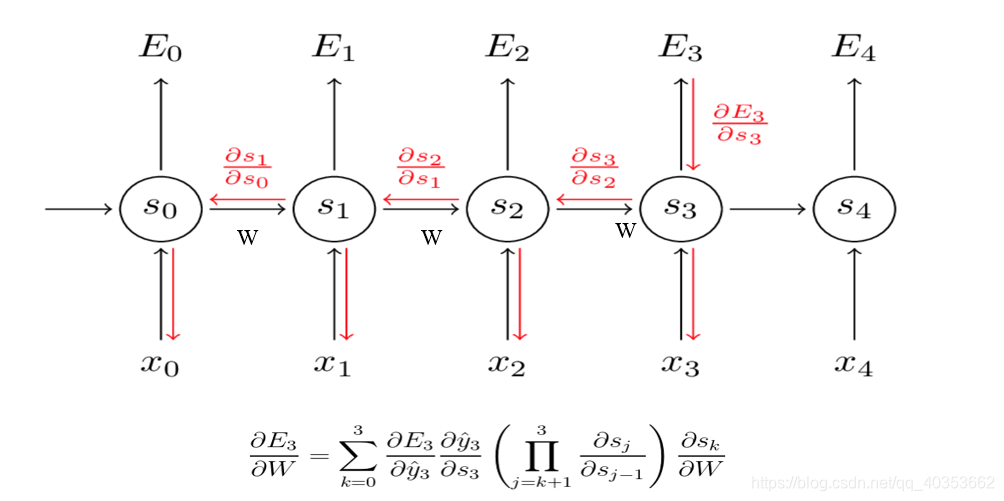



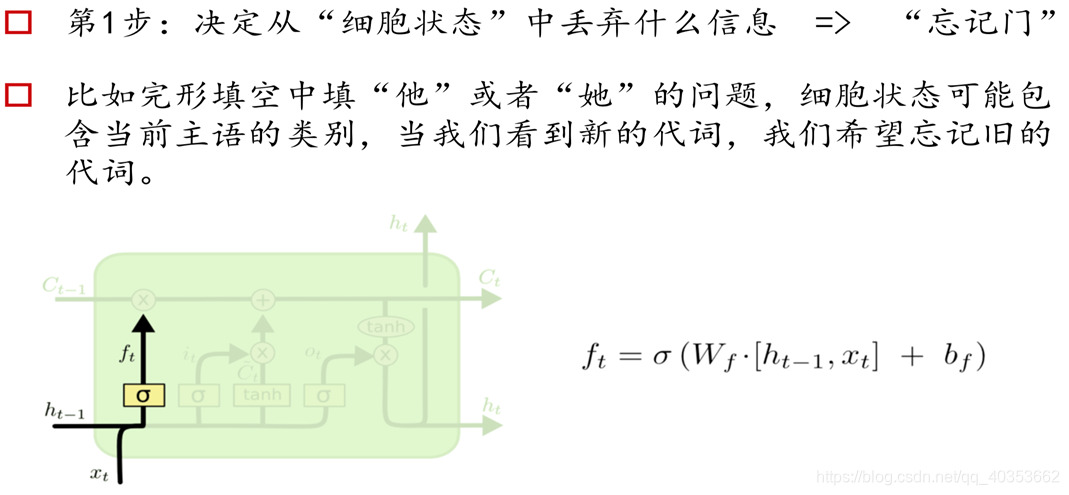
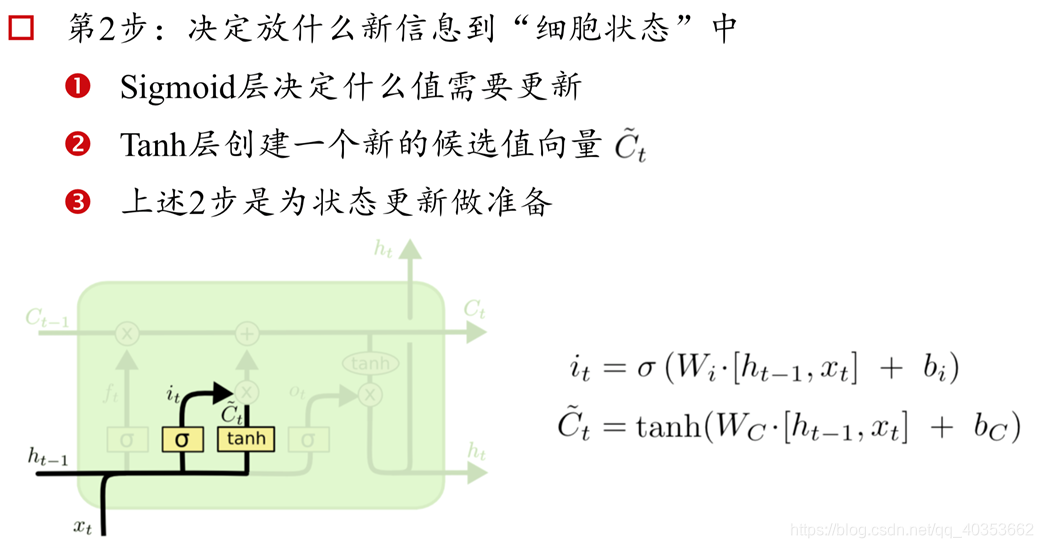
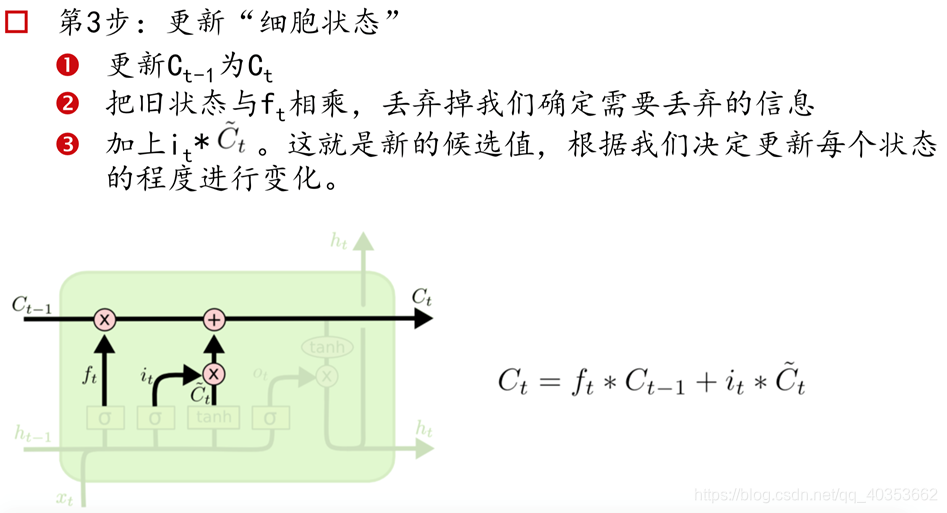
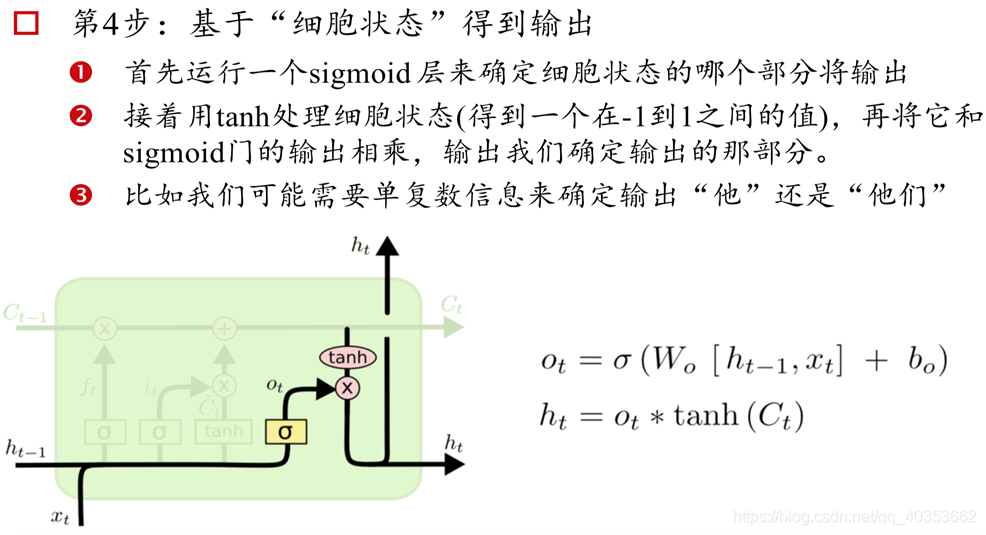
长短记忆网络(Long Short-term Memory)

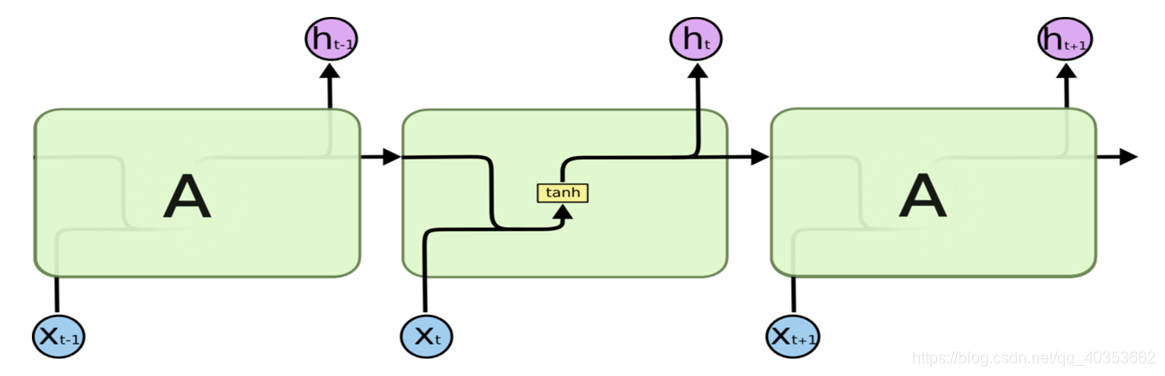
RNN细胞
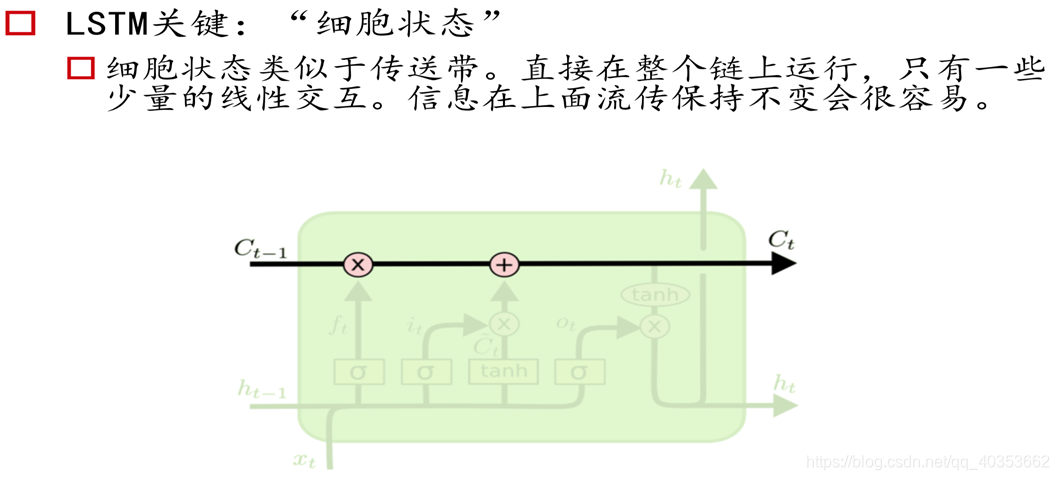
LSTM记忆细胞

长短记忆网络(Long Short-term Memory)
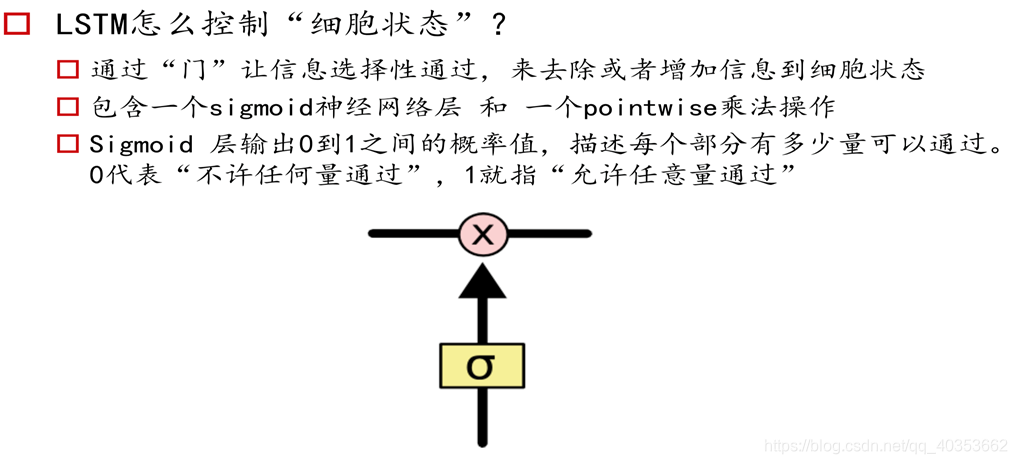
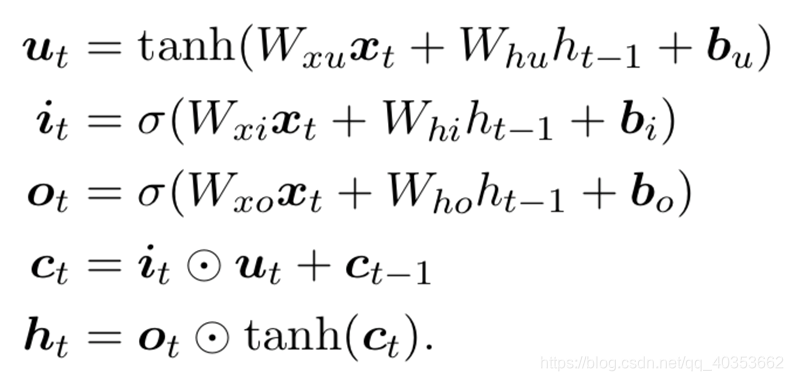
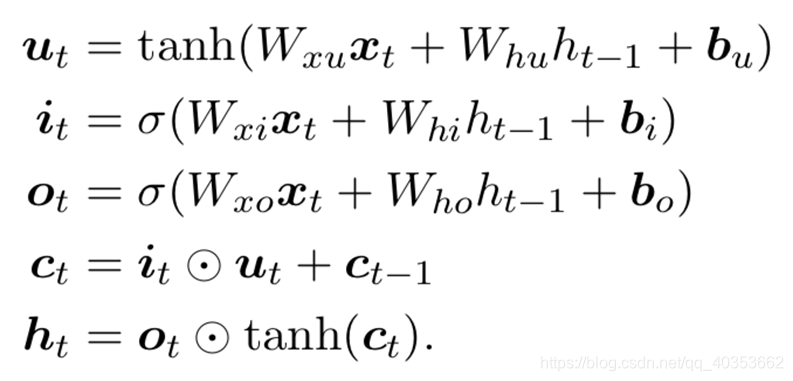
Gated Recurrent Unit
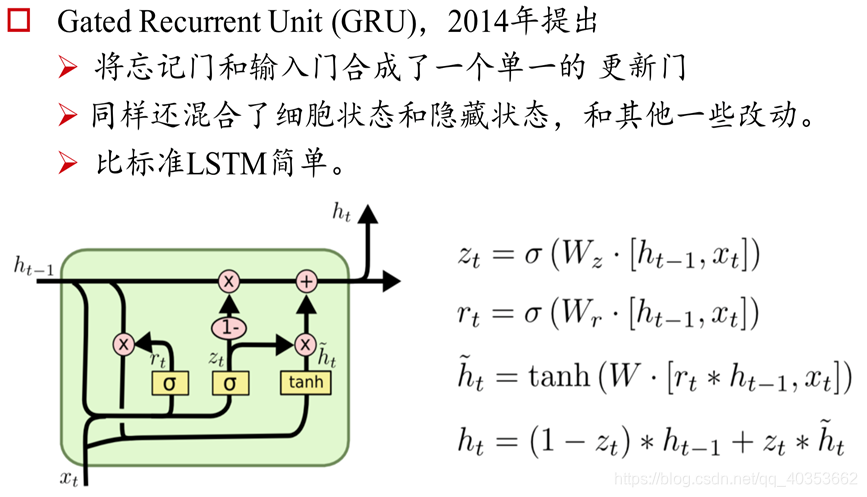
二、文本分类



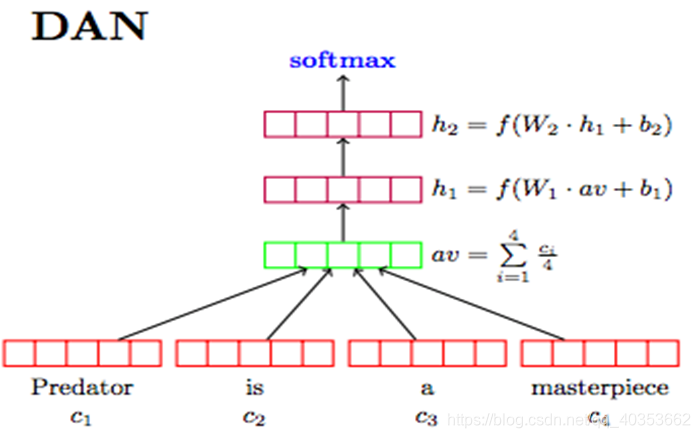

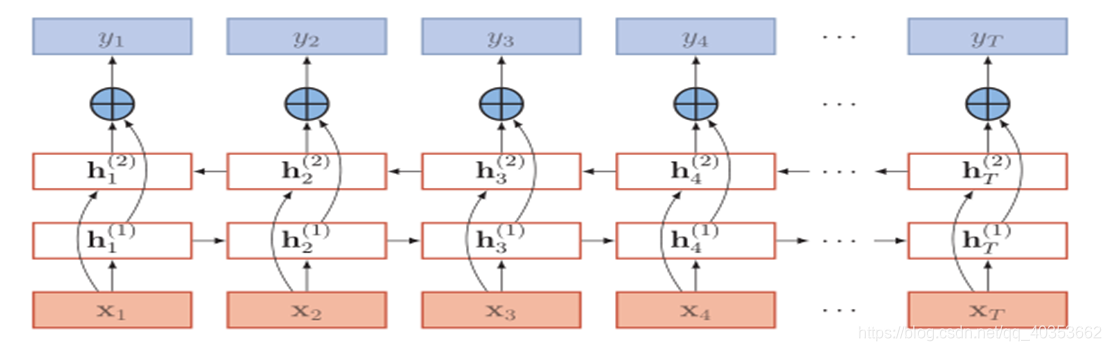
双向RNN
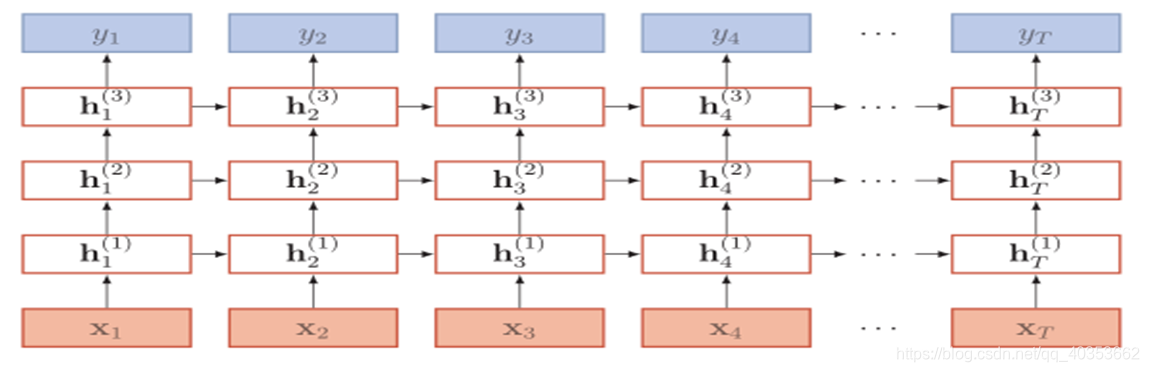
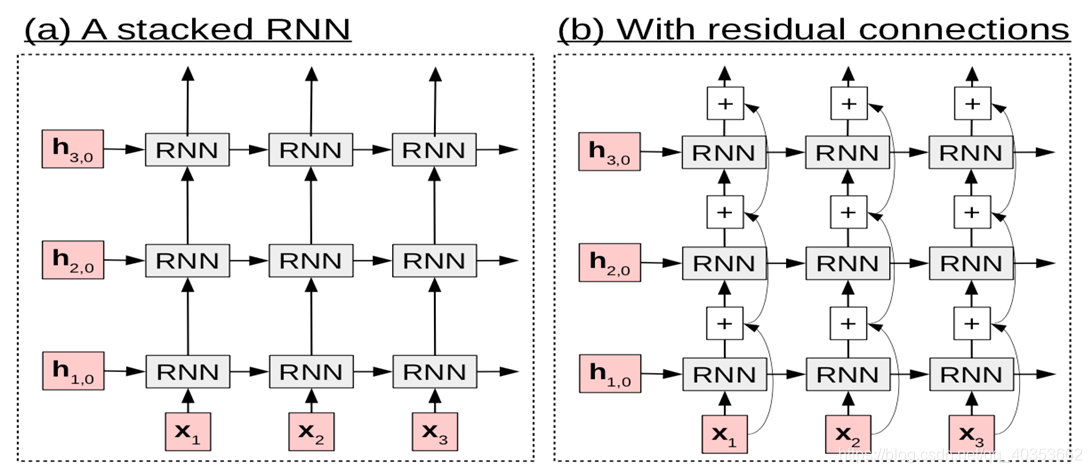
堆叠循环神经网络
CNN用作文本分类
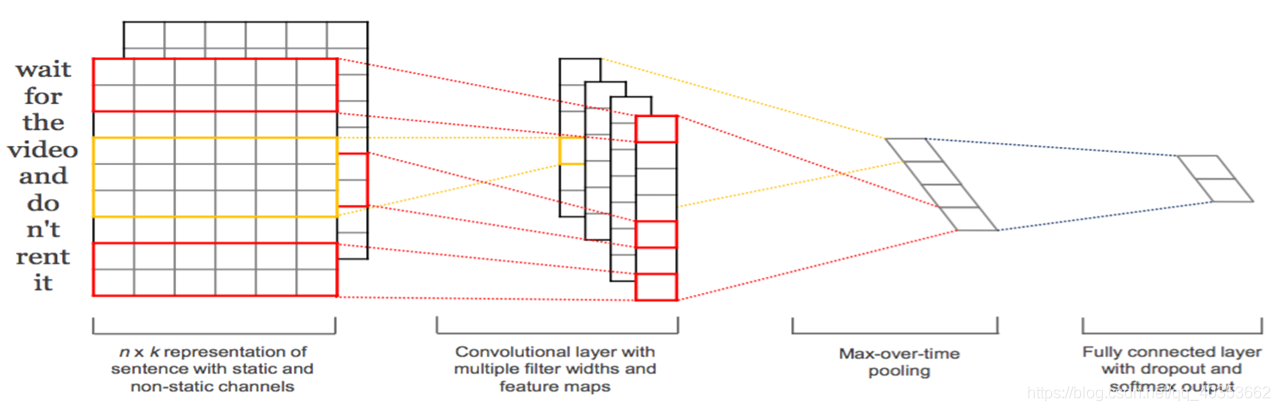
Embedding层

卷积层

Pooling层
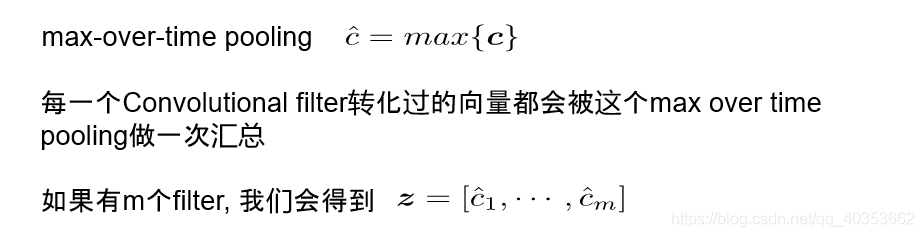
Regularization

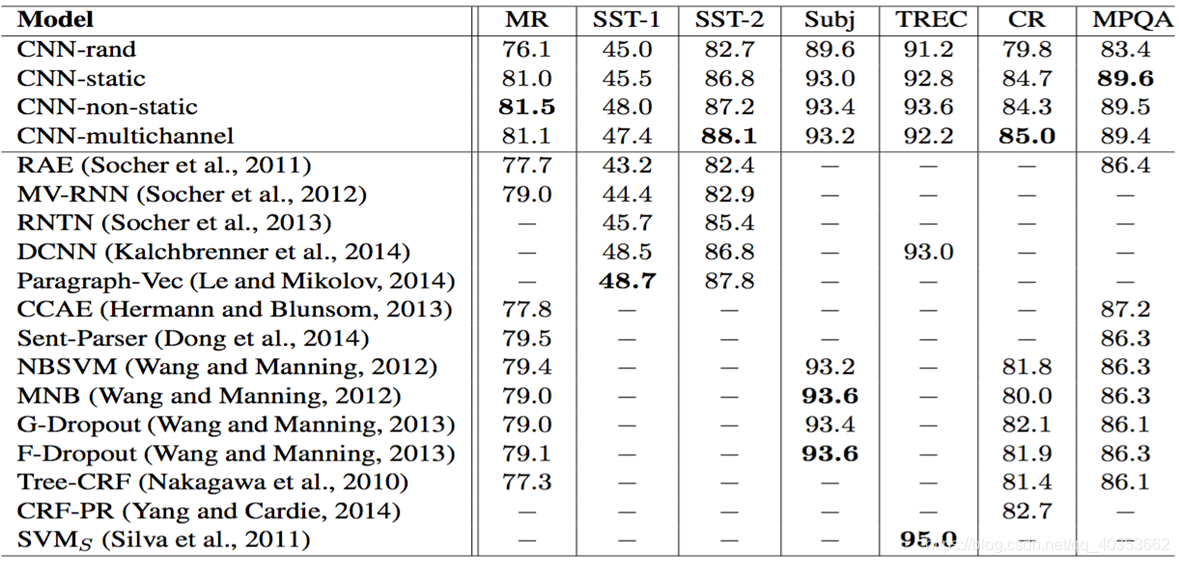
CNN实验结果














 7715
7715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









