







YOLOv8官方代码地址:ultralytics
COCO人体关键点数据处理:COCO姿态检测标签转YOLO格式:用于YOLOv8关键点检测
前言
实现YOLOv8-pose的快速使用:yolov8-pose关键点检测数据集的格式、标注与迭代;实现训练一个yolov8-pose模型;输出测试结果与分析。
1.训练所需配置文件
如下图,只需修改3个文件:
(1)数据配置文件:用于指定训练集和测试集路径、关键点格式、连接关键点方式。
(2)训练参数配置文件:包含轮次、批次、保存路径、数据增强等超参数设置。
(3)训练启动脚本,加载配置文件进行训练。

(a)建立保存训练文件的文件夹
如下图,每次保存配置文件和运行脚本,方便复现。因为需要进行的训练任务较多,所以用“task/用途_日期_模型大小”的方式保存(task可以是det或pose等)。这样目录结构更清晰,更方便后续的训练改进。(官方也对全部参数进行了保存,在train/args.yaml中。)

(b) 训练/验证/测试集路径格式
虽然官方给了读取JSON标签文件的方法,但个人更偏向于用txt标签文件。数据集布局如下:

如上图中,存在一个数据集文件夹比如“handpose_v2_yolov8_pose”、“VOC”等(图片实际可以存储在任意位置,在ultralytics/data/dataset.py中会调用get_img_files方法,可以遍历获取一个文件夹所有的图片,并保存为一个列表),但为了方便自己使用,还是分开保存。
数据集下分多个文件夹:比如train、val、test、xxx(文件夹的名字是任意的)等,但如果想要作为正样本(有目标类别和检测框),在路径中必须带有名为“images”的一个文件夹(不带也可以,但需要修改源码)。如下图,在images文件夹还可以有子文件夹:

如果没有labels文件夹,原图片则会作为负样本(加载时的background),标签文件夹“labels”需要和“images”存在同一级,否则也读取不到标签。且标签名称和图片名相同(仅后缀格式不同)。
例如:
图片路径为:/aaa/bbb/ccc/images/ddd/eee/fff/abc.jpg
则标签路径:/aaa/bbb/ccc/labels/ddd/eee/fff/abc.txt
为什么会这样要求呢?因为YOLOv8把图片路径转成标签路径的代码如下,就是把“images”替换成“labels”,和图片格式后缀换成“.txt”:
# ultralytics/data/utils.py
def img2label_paths(img_paths):
"""Define label paths as a function of image paths."""
sa, sb = f"{os.sep}images{os.sep}", f"{os.sep}labels{os.sep}" # /images/, /labels/ substrings
return [sb.join(x.rsplit(sa, 1)).rsplit(".", 1)[0] + ".txt" for x in img_paths]所以,也可以用文件列表来获取训练/验证/测试数据。如下图,保存一个数据的相对路径即可(因为在数据集配置文件中,可以指定根目录,自动组合成图片的绝对路径):

(c)关键点标签文件格式
(1)每个类有1+4+n×2个值
红色框内表示类别(1个值,可以多类别训练,但是要保证关键点数一致),绿色框内表示目标框(xywh4个值)。这里是1+4部分,和YOLOv8检测部分完全一致。
剩余其他的点,表示关键点(二维坐标x和y),我这里手部检测用了20个关键点(n=20),所以一个目标标签有1+4+20×2=45个数值。注意:无效点x和y的值在YOLOv8-pose里均为0。
无效点自定义:无效点(图片之外的点);不可见点(被其他物体遮挡,但在图片范围内,可以估计出其位置的点)均可作为无效点。但官方,以及一般做法,不可见点要估计出来保证目标关键点完整性。

(2)每个类有1+4+n×3个值
和上述(1)的唯一区别:给每个关键点分配了“无效”、“不可见”、“可见”属性,对应数值为0、1、2。如下图:

上面这个是COCO数据集中的,官方给了三种类别的标注,这样标注更好,就是标注起来比较麻烦。
为什么要分三类,是为了计算损失函数时候,方便给不同类型的点不同的权重。显然,可见点更重要,可以增加它的LOSS计算:
ultralytics/utils/loss.py中默认的损失函数,没有计算无效点的损失,且不可见和可见点的LOSS权重一样,这里就可以根据自己的需求修改了。(比如,加大可见点的损失、把不可见点的损失置为0等)。

(3)多标签的关键点检测训练
尽量不用用一个网络去做多标签的关键点检测,因为YOLOv8-pose是端到端的网络,网络本质上在做对每个关键点进行了关联与回归。会产生以下影响:
比如,手部关键点检测,将手势分成18个类别,检测20个关键点。YOLOv8-pose会分别对18个类进行关键点关联,因为每种手势差不多是固定的姿态,就会导致关联时,网络学习到某些姿态的特征。而本质上,这18个类别的手势都是“手”,关键点在手上也是固定的,而类别的划分会导致手部20个关键点的学习限制在特定的姿态。
用分类举例,更容易理解:对人进行手部检测,如果只有一个类别,那检测准确率可能达到90%。而当划分多类时,比如“ok”、“张开手掌”、“抓”等手势很像,这会导致对这三类预测的可能性变成:35%, 30%,25%(因为经过了softmax之类的操作,所有类别概率和为1),最终导致检测到手的置信度只有35%了。而实际上,不管是预测为哪个类别,网络都以较高的置信度检测到手。
如果一定要做多目标检测,尽可能检测不同类型的目标:比如一个检测人体姿态,一个检测手部姿态,二者属于差异较大。再处理标签时,需要把二者维度设为一致。(少的那个类别,增加无效点,因为无效点训练不会产生LOSS)。
(d)关键点检测数据集配置文件
在官方目录ultralytics/cfg/datasets下有coco-pose.yaml、tiger-pose.yaml。
以我自己进行的手部关键点检测为例, 创建hand-pose.yaml:
根据1.b所述,train和val的正样本是包含“images”和“labels”的路径,负样本读取到不含目标物体的图片就行。
根据1.c所述,kpt_shape是关键点维度,没有设置有效和不可见就是2维。原本是3维的也可以用2维训练,但是标签里每个关键点要去除标识类别(0, 1, 2)。
flip_idx:翻转关键点,开启图片翻转的时候,对称关键点需要进行替换,比如进行人体关键点检测时候,原图的左眼和右眼IDX为1和2,则水平翻转图片后,左眼会变成右眼,右眼会变成左眼,则IDX要变成2和1([0, 2, 1]这样一个顺序)。非对称目标则不用直接写[0, 1, 2]。没有开启翻转训练也不需要。之前这一个参数的理解写错了这里纠正一下。
nc:1和names0:hands:需要在训练配置里设置single_cla: True,才能把多个类别看做一个。
negative_setting:是我额外加的参数,用于增加负样本,以及控制每个epoch的正负样本比例和训练数据量。主要用于能够落地的模型训练,自测、试玩、做做本科毕业设计则不需要。具体实现参考:YOLOv8源码修改(1)- DataLoader增加负样本数据读取+平衡训练batch中的正负样本数
# path: ../datasets/coco-pose # dataset root dir
train: path/to/datasets/handpose_v2_yolov8_pose/train/images
val: path/to/datasets/handpose_v2_yolov8_pose/val/images
# test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Keypoints
kpt_shape: [21, 2] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
flip_idx: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 ,13 ,14, 15, 16, 17, 18, 19, 20]
# Add negative image ---------------------------------------------------------------------------------------------------
negative_setting:
neg_ratio: 0.1 # 小于等于0时,按原始官方配置训练,大于0时,控制正负样本。
use_extra_neg: True
extra_neg_sources: {"path/to/datasets/COCO2017/det_neg/images" : 80000,
# "path/to/datasets/VOC/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/JPEGImages": 1000,
} # 数据集字符串或列表(图片路径或图片列表)
fix_dataset_length: 640000 # 是否自定义每轮参与训练的图片数量
# Classes
nc: 1
names:
0: hand
(e)关键点检测训练参数配置文件
setting.yaml需要修改的参数取自default.yaml。
注意点:single_cls:把所有类当成一个类。muti_scale:图片会有多种shape传入网络,训练效果更好,但是很耗显存。需要调整box、cls、dfl、pose、kobj等损失的比重(如单类别cls就可以置为0)。degree:调整角度,比如手就可以随便转。fliplr:左右翻转的概率。还有个上下翻转的,用了效果很差,慎用。
# Train settings -------------------------------------------------------------------------------------------------------
task: pose # (str) YOLO task, i.e. detect, segment, classify, pose
mode: train # (str) YOLO mode, i.e. train, val, predict, export, track, benchmark
data: ./hand-pose.yaml # (str, optional) path to data file, i.e. coco8.yaml
epochs: 150 # (int) number of epochs to train for
batch: 64 # (int) number of images per batch (-1 for AutoBatch)
patience: 50 # (int) epochs to wait for no observable improvement for early stopping of training
device: 2 # (int | str | list, optional) device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu
project: ./ # (str, optional) project name
single_cls: True # (bool) train multi-class data as single-class
multi_scale: True # (bool) Whether to use multiscale during training
# Hyperparameters ------------------------------------------------------------------------------------------------------
lr0: 0.01 # (float) initial learning rate (i.e. SGD=1E-2, Adam=1E-3)
lrf: 0.01 # (float) final learning rate (lr0 * lrf)
box: 7.5 # (float) box loss gain
cls: 0.5 # (float) cls loss gain (scale with pixels)
dfl: 1.5 # (float) dfl loss gain
pose: 12.0 # (float) pose loss gain
kobj: 1.0 # (float) keypoint obj loss gain
degrees: 0.0 # (float) image rotation (+/- deg)
translate: 0.1 # (float) image translation (+/- fraction)
scale: 0.5 # (float) image scale (+/- gain)
fliplr: 0.5 # (float) image flip left-right (probability)(f)训练启动脚本
修改个模型位置,然后注意脚本运行所在路径,最终在./trains_pose/hands_07_12_m下运行python train.py:
为什么要引入Path、sys来修改当前所在目录?因为,在pycharm中运行,会自动调整好相对路径和绝对路径。但是在命令行运行时,import ultralytics导入的可能是pip安装的那个官方三方库,而不是自己工程路径下的ultralytics,这会导致自己修改的内容失效。
import sys
import yaml
from pathlib import Path
current_file_path = Path(__file__).resolve()
ancestor_directory = current_file_path.parents[2]
sys.path.insert(0, str(ancestor_directory)) # 必须转成str
from ultralytics import YOLO
sys.path.pop(0)
model = YOLO("../../weights/yolov8m-pose.pt")
with open('./setting.yaml') as f:
overrides = yaml.safe_load(f.read())
model.train(**overrides)
2.预测结果与分析
手部检测和关键点检测的算法流程将在后续给出。
(a)可视化结果
仅用一个手部关键点检测网络,结果惨不忍睹,这里检测顺序是:
人体姿态检测==>人体框手部检测==>手部关键点检测。
可以看到即使只检测手部,下图简单场景,效果都很差。
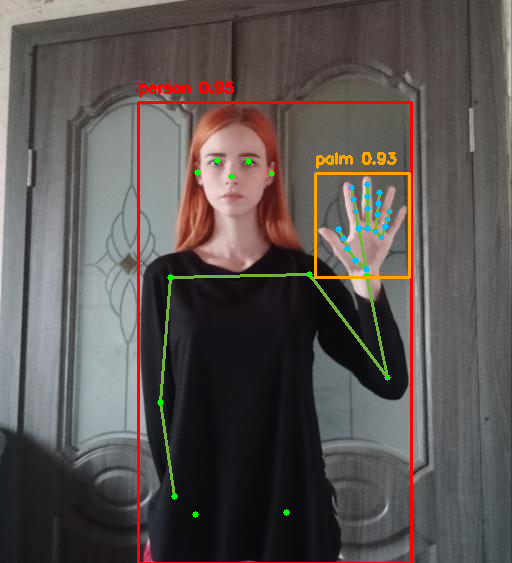
复杂场景,可能手都检测不出来,后续还要优化数据,重新训练网络:

相对好一点的结果:


(b)量化结果
conf:每个目标每个关键点的置信度;data:关键点实际坐标+置信度;has_visible:是否存在可见关键点;shape:关键点形状(下面是COCO人体姿态估计,17个关键点);xy:每个目标每个关键点在图片上的坐标;xyn:归一化的xy。
conf: tensor([[0.9967, 0.9576, 0.9962, 0.3303, 0.9817, 0.9987, 0.9991, 0.9887, 0.9940, 0.9904, 0.9942, 0.9994, 0.9995, 0.9991, 0.9994, 0.9948, 0.9955],
...
[0.0210, 0.0089, 0.0069, 0.0069, 0.0048, 0.0316, 0.0081, 0.3573, 0.0861, 0.7334, 0.4100, 0.0407, 0.0205, 0.0580, 0.0308, 0.0297, 0.0179]], device='cuda:0')
data: tensor([[[2.9429e+02, 4.5180e+02, 9.9670e-01],
...,
[2.7689e+02, 8.2352e+02, 9.9554e-01]],
...
[[0.0000e+00, 0.0000e+00, 2.1022e-02],
...,
[0.0000e+00, 0.0000e+00, 1.7886e-02]]], device='cuda:0')
has_visible: True
orig_shape: (1080, 810)
shape: torch.Size([4, 17, 3])
xy: tensor([[[294.2882, 451.7998],
...,
[276.8858, 823.5200]],
...
[[ 0.0000, 0.0000],
...,
[ 0.0000, 0.0000],
[ 0.0000, 0.0000]]], device='cuda:0')
xyn: tensor([[[0.3633, 0.4183],
...,
[0.3418, 0.7625]],
...
[[0.0000, 0.0000],
...,
[0.0000, 0.0000]]], device='cuda:0')3.后续改进
(a)数据迭代
手部关键点检测需要先检测到手部,再检测关键点,因此需要重新制作数据集。
(b)关键点自动标注
一般训练需要几千上万张图,自己没那么多时间标,可以用模型来标注。如谷歌有mediapipe可以用于手部自动标注。

















 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









