







背景
承接上部分:YOLOv8源码修改(2)- 解耦检测推理类+融合多个YOLOv8模型的检测推理结果
YOLOv8对追踪部分的代码同样实现了高度的封装,如进行推理只需运行:
from ultralytics import YOLO
data_path = r"/path/to/data/*.mp4"
model = YOLO(task="detect", model='/path/to/model/*.pt')
results = model.track(source=data_path, show=True, save=False, stream=True)上述跟踪调用代码和检测调用代码的区别仅在model.predict和model.track的调用名不同。官方仅提供了bot_sort和byte_tracker两种跟踪算法,常用的deep_sort并未给出。即使给出,由于高度封装,高耦合度导致自定义使用跟踪结果困难。因此,这里将YOLOv8只作为检测器使用,再结合deep_sort实现目标跟踪。最终,实现获取目标跟踪结果、可视化、保存推理文件等方法。
1.修改思路
改进点1:修改deep_sort,增加返回类别标签和置信度。
改进点2:实现自定义追踪类VideoTracker。
2.涉及修改相关的文件
deep_sort修改相关文件:
ultralytics/trackers/deep_sort/deep_sort.py
ultralytics/trackers/deep_sort/sort/detection.py
ultralytics/trackers/deep_sort/sort/tracker.py
实现追踪的相关文件:
ultralytics/task_bank/utils.py 【deepsort读取参数get_config()方法实现】
ultralytics/cfg/bank_monitor/track.yaml 【跟踪类读取的配置文件】
ultralytics/trackers/tracker_deep_sort.py 【跟踪类VideoTracker实现】
3.deepsort显示类别信息和置信度
3.1 修改代码
参考文章:yolov5+deepsort实现在跟踪时显示类别信息
由于deep_sort中的参数设置,导致实际检测的目标数和输出的跟踪目标数不一致,为了更好确定跟踪目标,需要知道跟踪目标的类别信息。原始deepsort并没有给出,因此进行修改。
如下图:deep_sort输出有11个目标,但实际检测目标仅10个。(因为当前帧有一些目标没检测出,但是deep_sort存有历史目标;或者当前帧首测检测出某些目标,但是deep_sort需要n帧才确认某个有效目标。)
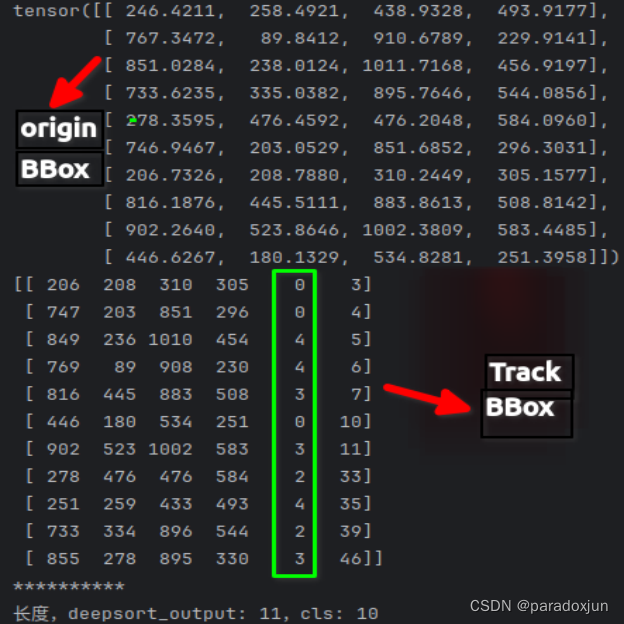
增加类别信息的方式和上述参考文章完全一致(上图绿色框内即为增加类别标签后的输出结果),但额外加入置信度时会略有差异。
# deep_sort.py中
# update方法中
# 对于detections新增了相应目标的label,但是置信度conf已经传入了,所以不需要增加
detections = [Detection(bbox_tlwh[i], conf, features[i], labels[i])
for i, conf in enumerate(confidences) if conf > self.min_confidence]
label = track.label # 新增此处,通过track.label取到track的label
confs = track.confs * 100 # 新增此处,通过track.confs取到track的confs
# 输出时,保存的数据类型是np.int32,为了避免不同格式麻烦,把confs乘100后,按整数保存
outputs.append(np.array([x1, y1, x2, y2, label, track_id, confs], dtype=np.int32))
# detection.py中
# confidence就是置信度,不需要额外增加__init__参数列表,只需额外加个参数
def __init__(self, tlwh, confidence, feature, label): # 新增label
self.tlwh = np.asarray(tlwh, dtype=np.float32) # x1, y1, w, h
self.confidence = float(confidence)
self.feature = np.asarray(feature, dtype=np.float32)
self.label = label # 新增此行
self.confs = confidence # 新增此行
# tracker.py中
def __init__(self, metric, max_iou_distance=0.7, max_age=70, n_init=3, label=None,
confs=None):
self.label = label # 新增此行
self.confs = confs # 新增此行
# update中
for track_idx, detection_idx in matches:
self.tracks[track_idx].update(self.kf, detections[detection_idx])
self.tracks[track_idx].label = detections[detection_idx].label # 新增此行
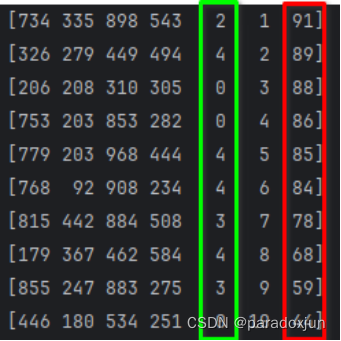
self.tracks[track_idx].confs = detections[detection_idx].confs # 新增此行修改后的输出结果,绿色框内是类别标签,红色框是内置信度(×100),二者之间是追踪ID:
3.2 修改配置文件
配置文件路径:/ultralytics/cfg/trackers/deep_sort.yaml,设置数值大小思路:
1.实际决定目标是否有效(置信度高低)在检测模型中已经设置,MIN_CONFIDENCE尽可能小。
2.不同物体可能完全重叠(箱子里有钱),这也是检测模型决定,所以极大值阈值设为1.0。
3.本项目IoU大,则大概率是一个目标,所以MAX_IOU_DISTANCE设为1.0。
DEEPSORT:
REID_CKPT: "ultralytics/trackers/deep_sort/deep/checkpoint/ckpt.t7"
MAX_DIST: 0.2 # 设置关联矩阵中余弦距离的最大阈值。较小值使关联更严格,较大相似度的检测框才关联。
MIN_CONFIDENCE: 0.1 # 只有置信度高于此阈值的检测结果才会被用于跟踪。
NMS_MAX_OVERLAP: 1.0 # 极大值抑制,重合比例上限,1.0时即使完全重合也不抑制。
MAX_IOU_DISTANCE: 1.0 # 设置检测框和跟踪目标之间的最大IoU。较大值允许更大重叠区域,使关联更为宽松。
MAX_AGE: 70 # 设置跟踪器中一个跟踪目标的最大未更新帧数。超过这个帧数未更新的跟踪目标将被删除。
N_INIT: 3 # 设置一个目标在确认前需要被连续检测到的帧数。只有经过这段时间的检测,目标才会被正式跟踪。
NN_BUDGET: 100 # 设置用于近邻搜索的最大特征数。如果特征数超过这个值,最旧的特征将被删除。4.多个YOLOv8模型+deep_sort实现类别跟踪
4.1 跟踪完整代码
文件路径:ultralytics/trackers/tracker_deep_sort.py
get_video():获取视频流,优先级:摄像头 > 指定文件路径 > 配置文件路径。
image_track(): 返回跟踪结果,检测结果,消耗时间。
plot_track():返回绘制检测框+类别+置信度+跟踪ID的图片。
make_save_dir(): 创建保存文件的文件夹。
save_track():保存生成的跟踪文件,绘制的图片、xyxy+cls+conf、xywh+cls+conf、跟踪结果。
det_track_pipline():读取视频,检测,追踪,绘制,保存全流程。
"""
代码参考DeepSORT_YOLOv5_Pytorch
"""
from ultralytics.utils.torch_utils import time_sync
from ultralytics.utils import yaml_load
from ultralytics.utils.plotting import colors as set_color
from ultralytics.trackers.deep_sort import build_tracker
from ultralytics.task_bank.predict import BankDetectionPredictor
from ultralytics.task_bank.utils import get_config
from pathlib import Path
from datetime import datetime
import os
import sys
import time
import cv2
import numpy as np
import torch
import torch.backends.cudnn as cudnn
currentUrl = os.path.dirname(os.path.dirname(__file__))
sys.path.append(os.path.abspath(os.path.join(currentUrl)))
cudnn.benchmark = True
class VideoTracker:
def __init__(self, track_cfg, predictors):
self.track_cfg = yaml_load(track_cfg) # v8内置方法读取track.yaml文件为字典
self.deepsort_arg = get_config(self.track_cfg["config_deep_sort"]) # 读取deep_sort.yaml为EasyDict类
self.predictors = predictors # 检测器列表
use_cuda = self.track_cfg["device"] != "cpu" and torch.cuda.is_available()
if self.track_cfg["save_option"]["txt"] or self.track_cfg["save_option"]["img"]: # 需要保存文本或图片时创建
self.save_dir = self.make_save_dir()
self.deepsort = build_tracker(self.deepsort_arg, use_cuda=use_cuda) # 实例化deep_sort类
print("INFO: Tracker init finished...")
def get_video(self, video_path=None): # 获取视频流(优先级:摄像头 > 指定文件路径 > 配置文件路径)
if video_path is None: # 读取输入
if self.track_cfg["camera"] != -1: # 使用摄像头获取视频
print("INFO: Using webcam " + str(self.track_cfg["camera"]))
v_cap = cv2.VideoCapture(self.track_cfg["camera"])
else: # 使用文件路径获取
assert os.path.isfile(self.track_cfg["input_path"]), "Video path in *.yaml is error. "
v_cap = cv2.VideoCapture(self.track_cfg["input_path"])
else:
assert os.path.isfile(video_path), "Video path in method get_video() is error. "
v_cap = cv2.VideoCapture(video_path)
return v_cap
def image_track(self, img): # 生成追踪目标的id
t1 = time_sync()
det_person = self.predictors[0](source=img)[0] # 官方预训练权重,检测人的位置
det_things = self.predictors[1](source=img)[0] # 自己训练的权重,检测物的位置
t2 = time_sync()
bbox_xywh = torch.cat((det_person.boxes.xywh, det_things.boxes.xywh)).cpu() # xywh目标框
bbox_xyxy = torch.cat((det_person.boxes.xyxy, det_things.boxes.xyxy)).cpu() # xyxy目标框
confs = torch.cat((det_person.boxes.conf, det_things.boxes.conf)).cpu() # 置信度
cls = torch.cat((det_person.boxes.cls + 4, det_things.boxes.cls)).cpu() # 标签,多检测器需要调整类别标签,这里简化实现
if len(cls) > 0:
deepsort_outputs = self.deepsort.update(bbox_xywh, confs, img, cls) # x1,y1,x2,y2,label,track_ID,confs
# print(f"bbox_xywh: {bbox_xywh}, confs: {confs}, cls: {cls}, outputs: {outputs}")
else:
deepsort_outputs = np.zeros((0, 6), dtype=np.int32) # 或者返回空
t3 = time.time()
return deepsort_outputs, [bbox_xywh, bbox_xyxy, cls, confs], [t2 - t1, t3 - t2]
def plot_track(self, img, deepsort_output, offset=(0, 0)): # 在一帧上绘制检测结果(类别+置信度+追踪ID)
for i, box in enumerate(deepsort_output):
x1, y1, x2, y2, label, track_id, confidence = list(map(int, box)) # 将结果均映射为整型
x1, y1, x2, y2 = x1 + offset[0], y1 + offset[1], x2 + offset[0], y2 + offset[1] # 文本框偏移(二次检测中再优化)
# 设置显示内容:文本框左上角为“标签名:置信度”,右上角为“跟踪id”,文本框颜色由类别决定
color = set_color(label * 4) # 设置颜色
cv2.rectangle(img, (x1, y1), (x2, y2), color, 2) # 基本矩形检测框
label_text = f'{self.track_cfg["class_name"][label]}:{round(confidence / 100, 2)}' # 左上角标签+置信度文字
cv2.putText(img, label_text, (x1 - 60, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 2)
track_text = f"ID: {track_id}" # 右上角追踪ID文字
cv2.putText(img, track_text, (x2, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 2)
return img
def make_save_dir(self): # 创建保存文件的文件夹
root_dir = Path(self.track_cfg["save_option"]["root"]) # 保存根路径
if not root_dir.exists(): # 根路径一定要自己指定
raise ValueError(f"设置存储根目录失败,不存在根路径:{root_dir}")
save_dir = os.path.join(root_dir, self.track_cfg["save_option"]["dir"]) # 实际保存路径
if os.path.exists(save_dir): # 存在也保存到这里
print(f"INFO: 当前保存路径 [{save_dir}] 已经存在。")
else:
os.makedirs(save_dir)
print(f"INFO: 当前保存路径 [{save_dir}] 不存在,已创建。")
for sub_dir in ["image_plot", "txt_track", "txt_xyxy", "txt_xywh"]: # 分目录保存不同结果
sub = os.path.join(save_dir, sub_dir)
if not os.path.exists(sub):
os.makedirs(sub)
return save_dir
def save_track(self, i=0, img=None, deepsort_output=None, det_res=None): # 传入帧数,绘制结果,追踪结果,检测结果
if not self.track_cfg["save_option"]["save"]:
return
if img is not None and self.track_cfg["save_option"]["img"]:
img_save = os.path.join(self.save_dir, "image_plot", "img_" + str(i).zfill(5) + ".jpg")
cv2.imwrite(img_save, img)
if self.track_cfg["verbose"]:
print(f"INFO: 已经保存[{img_save}].")
if deepsort_output is not None and self.track_cfg["save_option"]["txt"]:
deepsort_save = os.path.join(self.save_dir, "txt_track", "deepsort_" + str(i).zfill(5) + ".txt")
np.savetxt(deepsort_save, deepsort_output, fmt='%d')
if self.track_cfg["verbose"]:
print(f"INFO: 已经保存[{deepsort_save}].")
if det_res is not None and self.track_cfg["save_option"]["txt"]:
xywh, xyxy, cls, confs = det_res # torch.Size([n, 4]) torch.Size([n, 4]) torch.Size([n]) torch.Size([n])
xywh_save = os.path.join(self.save_dir, "txt_xywh", "xywh_" + str(i).zfill(5) + ".txt")
xyxy_save = os.path.join(self.save_dir, "txt_xyxy", "xyxy_" + str(i).zfill(5) + ".txt")
xywh_np = torch.cat([xywh, cls.view(-1, 1), confs.view(-1, 1)], dim=1).numpy()
xyxy_np = torch.cat([xyxy, cls.view(-1, 1), confs.view(-1, 1)], dim=1).numpy()
np.savetxt(xywh_save, xywh_np, fmt='%.6f')
if self.track_cfg["verbose"]:
print(f"INFO: 已经保存[{xywh_save}].")
np.savetxt(xyxy_save, xyxy_np, fmt='%.6f')
if self.track_cfg["verbose"]:
print(f"INFO: 已经保存[{xyxy_save}].")
def det_track_pipline(self, video_path=None): # 读取视频,检测,追踪,绘制,保存全流程
cap = self.get_video(video_path=video_path)
if not cap.isOpened():
print("INFO: 无法获取视频,退出!")
exit()
# 获取视频的宽度、高度和帧率
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = int(cap.get(cv2.CAP_PROP_FPS))
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 编码格式
current_time = datetime.now().strftime('%Y-%m-%d-%H-%M')
video_plot_save_path = os.path.join(self.save_dir, "video_plot_" + current_time + ".mp4")
out = cv2.VideoWriter(video_plot_save_path, fourcc, fps, (width, height)) # 初始化视频写入器
yolo_time, sort_time, avg_fps = [], [], []
t_start = time.time()
idx_frame = 0
last_deepsort = None # 跳过的帧不绘制,会导致检测框闪烁
while True:
ret, frame = cap.read()
t0 = time.time()
if not ret or cv2.waitKey(1) & 0xFF == ord('q'): # 结束 或 按 'q' 键退出
break
if idx_frame % self.track_cfg["vid_stride"] == 0:
deep_sort, det_res, cost_time = vt.image_track(frame) # 追踪结果,检测结果,消耗时间
last_deepsort = deep_sort
yolo_time.append(cost_time[0]) # yolo推理时间
sort_time.append(cost_time[1]) # deepsort跟踪时间
if self.track_cfg["verbose"]:
print('INFO: Frame %d Done. YOLO-time:(%.3fs) SORT-time:(%.3fs)' % (idx_frame, *cost_time))
plot_img = vt.plot_track(frame, deep_sort) # 绘制加入追踪框的图片
vt.save_track(idx_frame, plot_img, deep_sort, det_res) # 保存跟踪结果
else:
plot_img = vt.plot_track(frame, last_deepsort) # 帧间隔小,物体运动幅度小,就用上一次结果
out.write(plot_img) # 将处理后的帧写入输出视频
t1 = time.time()
avg_fps.append(t1 - t0) # 第1帧包含了模型加载时间要删除
# add FPS information on output video
text_scale = max(1, plot_img.shape[1] // 1000)
cv2.putText(plot_img, 'frame: %d fps: %.2f ' % (idx_frame, (len(avg_fps) - 1) / (sum(avg_fps[1:]) + 1e-6)),
(10, 20 + text_scale), cv2.FONT_HERSHEY_PLAIN, text_scale, (0, 0, 255), thickness=1)
cv2.imshow('Frame', plot_img)
idx_frame += 1
cap.release() # 释放读取资源
out.release() # 释放写入资源
cv2.destroyAllWindows()
avg_yolo_t, avg_sort_t = sum(yolo_time[1:]) / (len(yolo_time) - 1), sum(sort_time[1:]) / (len(sort_time) - 1)
print(f'INFO: Avg YOLO time ({avg_yolo_t:.3f}s), Sort time ({avg_sort_t:.3f}s) per frame')
total_t, avg_fps = time.time() - t_start, (len(avg_fps) - 1) / (sum(avg_fps[1:]) + 1e-6)
print('INFO: Total Frame: %d, Total time (%.3fs), Avg fps (%.3f)' % (idx_frame, total_t, avg_fps))
if __name__ == '__main__':
track_cfg = r'ultralytics/cfg/bank_monitor/track.yaml'
overrides_1 = {"task": "detect",
"mode": "predict",
"model": r'weights/yolov8m.pt',
"verbose": False,
"classes": [0]
}
overrides_2 = {"task": "detect",
"mode": "predict",
"model": r'weights/best.pt',
"verbose": False
}
predictor_1 = BankDetectionPredictor(overrides=overrides_1)
predictor_2 = BankDetectionPredictor(overrides=overrides_2)
predictors = [predictor_1, predictor_2]
vt = VideoTracker(track_cfg=track_cfg, predictors=predictors)
vt.det_track_pipline()
4.2 跟踪配置文件
文件路径:ultralytics/cfg/bank_monitor/track.yaml
input_path: '/ultralytics/assets/银行柜台监控_1.mp4'
save_option: # 保存设置
save: False # 是否保存
root: '.' # 保存的根目录
dir: 'runs/detect/track' # 当前运行保存的子目录
txt: True # 保存运行结果的 txt
img: True # 保存运行结果生成的图片
vid_stride: 1
config_deep_sort: 'ultralytics/cfg/trackers/deep_sort.yaml'
fourcc: mp4v
camera: -1 # 0使用摄像头,-1使用input_path
device: 0
verbose: True # 控制台打印,控制循环内的持续输出,False不打印
half: False # 暂未实现,控制推理精度
video_shape: [800, 800] # 暂未实现,resize视频
class_name:
0: ycj
1: kx
2: kx_dk
3: money
4: person4.3 跟踪脚本文件
文件路径:ultralytics/task_bank/utils.py
import cv2
import os
import yaml
from easydict import EasyDict
class YamlParser(EasyDict):
def __init__(self, cfg_dict=None, config_file=None):
if cfg_dict is None:
cfg_dict = {}
if config_file is not None:
assert (os.path.isfile(config_file))
with open(config_file, 'r', encoding='utf8') as fo:
cfg_dict.update(yaml.safe_load(fo.read()))
super(YamlParser, self).__init__(cfg_dict)
def merge_from_file(self, config_file):
with open(config_file, 'r', encoding='utf8') as fo:
self.update(yaml.safe_load(fo.read()))
def merge_from_dict(self, config_dict):
self.update(config_dict)
def get_config(config_file=None):
return YamlParser(config_file=config_file)5.实现结果
5.1 整个视频
(用的gif,画面变小了)类别标签:[4: person] 用的官方在COCO上的预训练模型。

5.2 绘制一帧图片
image_plot/img_00012.jpg
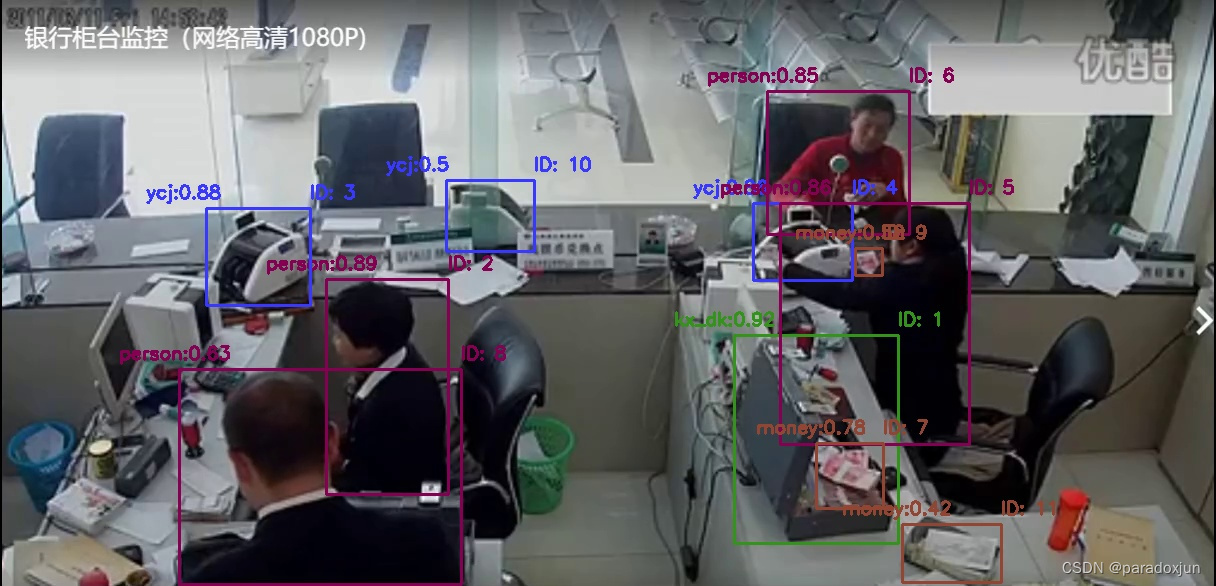
5.3 保存的txt文件
txt_track/deepsort_00006.txt:xyxy, label, track_id, confs * 100
734 335 898 543 2 1 91
326 279 449 494 4 2 89
206 208 310 305 0 3 88
752 203 852 282 0 4 86
780 203 969 444 4 5 85
767 92 909 234 4 6 84
815 442 884 508 3 7 78
178 367 462 584 4 8 67
855 247 883 275 3 9 60
446 180 534 251 0 10 43
902 523 1002 582 3 11 34
txt_xywh/xywh_00010.txt:xywh, label, confs
387.834015 387.347595 122.637573 215.331787 4.000000 0.895952
875.006836 323.983795 189.708008 241.087784 4.000000 0.864840
838.380127 161.900116 143.752869 141.049896 4.000000 0.857066
321.527405 476.840576 284.455353 214.561432 4.000000 0.713647
816.212769 439.757629 164.328918 207.742157 2.000000 0.919735
258.437622 256.812073 103.471252 96.869720 0.000000 0.887086
802.680542 241.751892 103.026306 76.692383 0.000000 0.864016
849.804504 475.763550 68.107300 65.051544 3.000000 0.794779
869.096680 262.049988 27.595703 27.738800 3.000000 0.595185
490.935913 216.030090 88.555939 71.627121 0.000000 0.535241
txt_xyxy/xyxy_00015.txt:xyxy, label, confs
326.236115 279.496338 449.115112 495.754913 4.000000 0.894121
780.437744 203.577209 970.630859 444.434509 4.000000 0.865519
766.563354 90.728043 910.448608 235.107712 4.000000 0.844082
179.622604 370.436951 464.225403 584.211487 4.000000 0.717400
734.871582 335.736328 898.211060 543.609619 2.000000 0.919196
206.664078 208.352371 310.117462 305.337036 0.000000 0.887828
751.260620 203.381668 854.233826 280.673706 0.000000 0.868569
815.634277 443.286102 883.870789 508.073608 3.000000 0.792141
855.348328 248.335007 882.242126 275.982758 3.000000 0.573794
446.587341 180.210602 535.139343 251.889969 0.000000 0.487832
902.419250 523.789673 1001.749451 582.822998 3.000000 0.284754
6. 后续改进
6.1 deep_sort改进
由于deep_sort基于reid训练,主要用于行人的跟踪,其中的编码网络较为简单。后续将替换特征编码网络为百度paddleclas的pp-lcnet,用于特征编码。
6.2 跟踪逻辑改进
基于卡尔曼滤波,获取了运动状态,实际可以利用这些运动状态,自定义加权当前状态,比如维护一个滑动窗口,计算n帧内的运动状态,再用匈牙利算法获取ID。因为在本场景中,行动状态较为固定,且即使发生遮挡,后续运动状态也较为容易估计出。

















 2314
2314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









