







文章目录
多模态
多模态(Multimodal)通常指的是包含来自多个模态的数据或信息的情况,其中模态是指信息的不同表现形式或类型。在多模态学习中,涉及的模态可以是图像、文本、音频、视频、传感器数据等。多模态系统通过整合这些不同的模态信息,期望实现比单一模态更强的表现力和更好的性能。
常见模态包括:
视觉模态:比如,使用图像识别技术从图像中提取特征。
听觉模态:比如,语音识别技术可以将语音转化为文本。
文本模态:比如,使用自然语言处理技术对文本进行分类或生成。
不同模态的数据提供不同的视角。结合多个模态能够消除单一模态的局限性。通过多模态数据的融合,模型能够捕捉更丰富的特征,提高学习效果。
多模态的核心技术一般分为:特征提取、融合策略、训练策略。
Connector
在多模态学习(Multimodal Learning)中,connector通常指的是用于将来自不同模态(如文本、图像、音频等)的信息进行融合或连接的组件。
视觉——文本
MLLMs
MLLMs使用了视觉-语言投影器(Vision-Language Projector),原理分为以下几个步骤:
(1)视觉模型(如ViT)将输入图像分解成多个补丁(patches),每个补丁被编码成一个向量,形成视觉补丁嵌入( Z v Z_v Zv)
(2)视觉-语言投影器通过一个映射函数 P P P将这些视觉补丁嵌入转换为与文本特征空间对齐的视觉嵌入( H v H_v Hv):
H v = P ( Z v ) H_v = P(Z_v) Hv=P(Zv)
(3)为了减少计算复杂度和内存消耗,投影器通常会减少视觉嵌入的令牌数量。这可以通过多种方法实现,例如使用点卷积层(point-wise convolution layers)、平均池化(average pooling)等技术。
(4)为了保留视觉信息的空间结构,投影器会增强视觉嵌入的位置信息。这可以通过添加位置编码(positional encoding)来实现,确保模型能够理解不同视觉特征在图像中的相对位置。
(5)转换后的视觉嵌入( H v H_v Hv)与文本嵌入( H q H_q Hq)被拼接在一起,作为语言模型的输入。语言模型通过自回归方式生成最终的响应序列( Y a Y_a Ya):
p ( Y a ∣ H v , H q ) = ∏ L i = 1 p ( y i ∣ H v , H q , y < i ) p(Y_a|H_v, H_q) = \underset{i=1}{\overset{L}{\prod}}p(y_i|H_v, H_q, y_{<i}) p(Ya∣Hv,Hq)=i=1∏Lp(yi∣Hv,Hq,y<i)
此外还使用了视觉令牌压缩(Vision Token Compression)技术,减少多模态大语言模型(MLLMs)处理高分辨率图像时的计算负担:
(1)多视图输入:为了利用低分辨率视觉编码器,同时使多模态大模型(MLLMs)能够感知详细信息,通常采用多视图高分辨率图像输入的方法。这包括全局视图(通过调整大小获得的低分辨率图像)和局部视图(从图像中分割出的图像块)。
(2)LLaVA-UHD 提出了一个压缩模块,进一步压缩来自视觉编码器的图像令牌,显著减少计算负载。此外,它还提出了一种空间模式来组织切片令牌,以便于 LLMs 处理。
(3)多尺度信息融合:利用多尺度图像信息对于视觉特征提取至关重要。这种方法允许模型捕捉小尺度中的细粒度细节和大尺度中的广泛上下文。例如,Mini-Gemini 采用双编码器结构,一个用于高分辨率图像,另一个用于低分辨率视觉嵌入。它通过交叉注意力机制使用低分辨率视觉嵌入作为查询,从高分辨率候选中检索相关视觉线索。
(4)LLaVA-PruMerge 和 MADTP 提出了一种自适应视觉令牌减少方法,通过动态选择重要令牌来减少令牌数量。
(5)视频理解需要处理大量帧,这在 LLMs 的上下文窗口中可能是一个显著的计算挑战。例如,Elysium 提供了性能和视觉令牌消耗之间的权衡,通过引入 T-Selector 作为视觉令牌压缩网络,使 LLMs 能够区分各个帧,同时减少视觉令牌的使用。
(6)为了提高视觉-语言连接器的表示能力,一些研究发现使用多层感知机(MLP)比简单的线性投影效果更好。例如,LLaVA-1.5 使用了一个两层的MLP来改进视觉-语言连接器的表示能力。
VoCo-LLaMA
VoCo-LLaMA在连接视觉和文本模态方面相较于传统的大型语言模型(LLMs)做了以下改进:
(1)引入视觉压缩令牌(VoCo tokens):VoCo-LLaMA 通过在视觉和文本令牌之间插入视觉压缩令牌(VoCo tokens),将视觉和文本模态隔离。这种设计使得模型可以专注于压缩视觉令牌,并将压缩后的信息通过 VoCo tokens 传递给文本模态。
(2)注意力机制的修改:VoCo-LLaMA 修改了注意力机制,使得 VoCo tokens 仅与输入的文本令牌交互。这建立了一个无缝的路径,使压缩后的视觉信息能够与文本模态对齐,而无需专门的跨模态对齐模块。
(3)内在的令牌提炼:通过视觉指令调优阶段,VoCo-LLaMA 将 LLMs 对视觉令牌的理解提炼到处理压缩令牌的过程中。这种方法不仅提高了视觉压缩的有效性,还保持了较低的性能损失。
(4)高效的推理:VoCo-LLaMA 模型通过将视觉 tokens 压缩成更少的 VoCo tokens,可以在推理时缓存这些压缩后的激活。当处理新的输入时,模型可以直接使用这些缓存的激活,从而减少计算量和存储需求。例如,模型可以实现高达 576 倍的压缩率,同时减少 94.8% 的浮点运算(FLOPs)和 69.6% 的推理时间。
LoTLIP
为了改进语言-图像预训练模型在长文本理解上的表现,研究者们在文本输入中引入了称为角令牌(corner tokens)的可学习令牌。角令牌被插入到文本输入的[CLS]令牌之后。通过这种方式,角令牌可以与文本中的其他令牌进行交互,但不会直接与[CLS]令牌交互。这种设计有助于角令牌提取更多代表性的特征,从而增强模型对长文本和短文本的理解能力。
[CLS]令牌通常用于表示整个文本的全局特征,而角令牌则用于捕捉文本中的局部特征。通过限制角令牌与[CLS]令牌之间的直接交互,可以避免信息冗余,确保每个令牌都能专注于不同的特征提取任务。
具体形式为:[CLS], [Cor 1] … [Cor m], · · · [SEP], · · · [SEP]
对比学习
这个模型中,连接图像和文本信息的connector主要是通过对比学习(contrastive learning)实现的。具体来说,模型使用了图像编码器和文本编码器来分别提取图像和文本的特征。这两个编码器通过对比损失(contrastive loss)进行优化,确保配对的图像和文本特征在嵌入空间中距离较近,而未配对的特征则距离较远。
Transfusion
Transfusion的新方法,用于训练一个处理离散数据(如文本)和连续数据(如图像)的单一多模态模型。Transfusion结合了语言建模中的下一个标记预测任务和扩散模型的训练目标,以训练一个统一的Transformer模型来处理混合模态序列。
多模态融合过程为:
(1)文本字符串被分词成一系列离散的token,每个token用一个整数表示。
(2)图像被编码为潜在补丁(latent patches),使用预训练的变分自编码器(VAE)进行编码。每个补丁表示为一个连续向量,补丁按从左到右、从上到下的顺序排列,形成一个补丁向量序列。
(3)在文本序列中插入图像序列时,每个图像序列前后分别添加特殊的开始图像(BOI)和结束图像(EOI)token,从而形成一个包含离散元素(文本token)和连续元素(图像补丁)的单一序列。
然后使用注意力机制:
(1)文本:使用因果掩码(causal masking),确保每个文本token只能看到之前的token。
(2)图像:使用双向注意力(bidirectional attention),允许图像中的每个补丁看到其他补丁。这使得图像中的每个补丁可以相互条件化,但只能条件化于之前出现的文本或图像补丁。
(3)混合模态:结合了文本的因果注意力和图像的双向注意力。具体来说,每个图像补丁可以条件化于同一图像中的其他补丁,但只能条件化于之前出现的文本或图像补丁。
BLIP-2
BLIP-2是一种高效的视觉和语言预训练方法,通过利用预先训练好的冻结图像编码器和大型语言模型来减少计算成本。
Q-Former
BLIP-2 使用了一个轻量级的查询转换器(Querying Transformer,简称 Q-Former)作为连接视觉和语言的connector。
Q-Former的设计包括两个主要的Transformer子模块,它们共享相同的自注意力层:
(1)图像Transformer:与冻结的图像编码器交互,提取图像特征。
(2)文本Transformer:与文本令牌交互,生成文本
Q-Former通过以下方式工作:
(1)自注意力层:查询向量之间可以相互作用,但不能直接与文本令牌交互。
(2)交叉注意力层:这些层允许查询向量关注图像编码器的输出,从而提取与问题相关的视觉特征。
(3)多模态因果自注意力掩码:控制查询向量与文本令牌之间的交互,确保查询向量首先提取视觉信息,然后再传递给文本令牌。
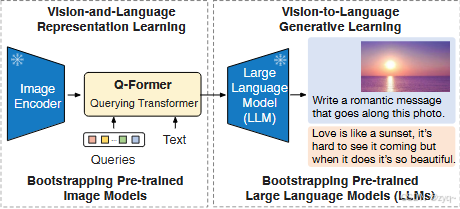
Q-Former的输入包括从冻结的图像编码器中提取的图像特征和可学习的查询向量。这些查询向量通过自注意力层相互作用,并通过交叉注意力层与冻结的图像特征相互作用。此外,Q-Former还可以接收文本作为输入,以引导其提取与问题更相关的图像特征。
Q-Former的输出是输出查询表示,这是一个固定数量的特征向量,每个向量的维度为768(与Q-Former的隐藏维度相同)。这些输出查询表示作为软视觉提示,被线性投影到与LLM的文本嵌入相同的维度,然后与输入文本嵌入连接,以条件化LLM在Q-Former提取的视觉表示上生成语言。
InternVL
InternVL模型将视觉基础模型的参数规模扩展至60亿,并逐步与其对应的大型语言模型(LLM)对齐。该模型使用来自各种来源的网络级图像文本数据进行预训练,能够在32个通用视觉-语言基准上实现最先进的性能。这些任务包括图像分类、像素级识别、零样本图像/视频分类、零样本图像/视频-文本检索以及与LLM结合创建多模态对话系统等。
这个模型的连接器(connector)是通过一个MLP(多层感知机)层实现的。具体来说,InternVL模型通过MLP层与现有的大型语言模型(如Vicuna或InternLM)连接,并进行监督微调(SFT)。这样可以确保模型在多模态任务中的表现更加出色。
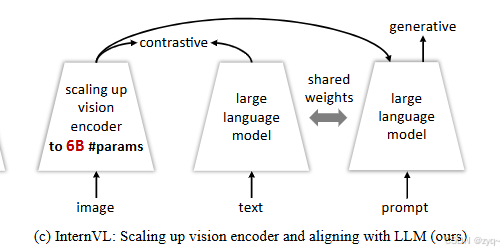
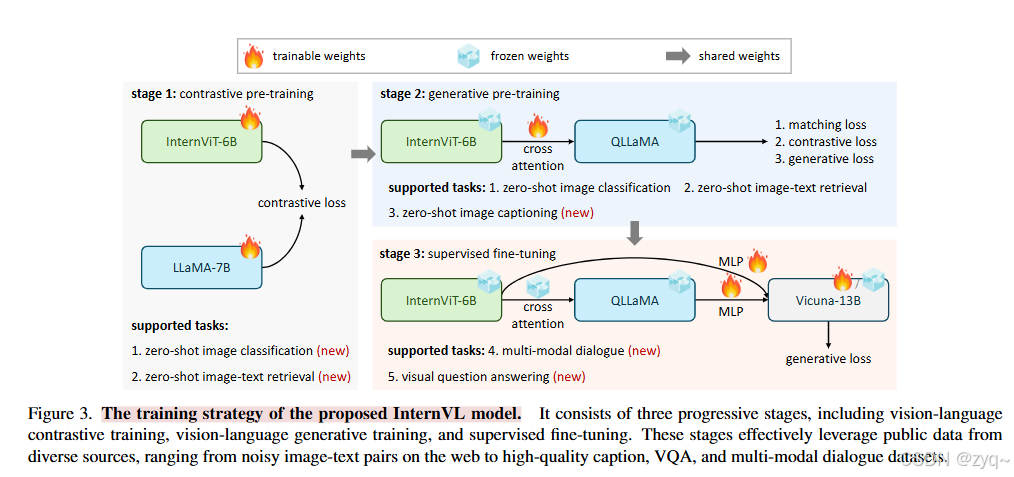
MLP层,即多层感知器(Multi-Layer Perceptron)层,在InternVL模型中扮演了重要的角色。具体来说,MLP层用于连接视觉编码器(InternViT-6B)和语言中间件(QLLaMA),以及在多模态对话系统中连接InternVL与现成的LLM解码器(如Vicuna或InternLM)。其结构为:
(1)输入:MLP层的输入通常是视觉编码器生成的特征向量。
(2)隐藏层:MLP层包含一个或多个隐藏层,每个隐藏层由多个神经元组成,这些神经元通过激活函数(如ReLU)进行非线性变换。
(3)输出:MLP层的输出是经过变换后的特征向量,这些特征向量可以被语言模型进一步处理。
所以MLP层的作用之一是让视觉向量映射到能与语言向量对齐的向量,此外还有加快微调等功能。
OneLLM
OneLLM通过一个统一的多模态编码器和逐步多模态对齐管道实现这一目标。具体步骤包括:
(1)首先训练图像投影模块连接视觉编码器与语言模型;
(2)然后构建通用投影模块(UPM)结合多个图像投影模块和动态路由;
(3)最后逐步将更多模态对齐到语言模型中。
为了充分利用OneLLM在指令执行中的潜力,研究人员还创建了一个包含来自图像、音频、视频等八个模态的200万项指令的数据集。
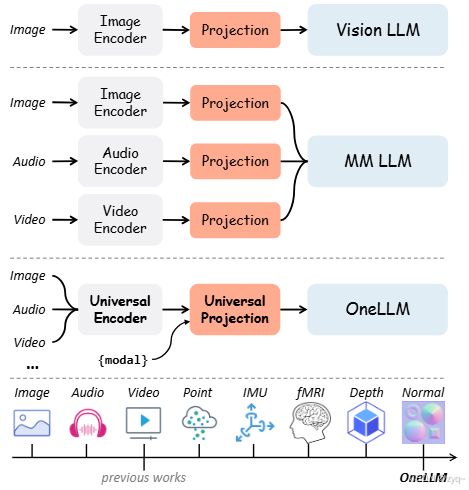
通用投影模块(UPM)
OneLLM 使用的connector是通用投影模块(UPM)。这个模块通过混合多个图像投影模块和动态路由来构建,能够有效地将不同模态的数据对齐到语言模型中。
UPM(Universal Projection Module)的具体结构如下:
(1)投影专家(Projection Experts):UPM 包含 K 个投影专家,每个专家由 8 个 Transformer 块组成,参数量为 88M。这些专家负责将不同模态的输入信号投影到 LLM 的嵌入空间中。
(2)动态模态路由器(Dynamic Modality Router):为了控制每个专家的贡献,UPM 引入了一个动态模态路由器 R。路由器 R 是一个多层感知器(MLP),接收输入 tokens 并计算每个专家的路由权重。这些权重通过 SoftMax 函数进行归一化,确保所有专家的权重之和为 1。
(3)模态 tokens(Modality Tokens):为了在不同模态之间进行切换,UPM 引入了可学习的模态tokens { q m } m ∈ M \set{q_m}_{m\in M} {
qm}m∈
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2895
2895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









