







联邦学习的威胁模型和攻防现状
前言
上篇博文讲述了联邦学习的基本概念、三种框架和应用场景,本篇主要从联邦学习的威胁模型和攻防现状入手,对联邦学习的安全隐私问题进行总结记录
参考: On the Security & Privacy in Federated Learning
一、威胁模型
尽管联邦学习的框架的使用保证了基本的安全隐私,如加入同态加密、安全多方计算和差分隐私等机制来保护安全隐私,但现实中仍然存在安全隐私的泄露问题,如下是对联邦学习的威胁模型:

自联邦学习于2016年推出以来,没有一款针对攻击和防御的统一分类法能够帮助联邦学习进行安全和隐私评估。需要统一的分类来系统化联邦学习中安全和隐私现状【攻防现状】,以便于为以后的研究提供思路
二、攻防现状
1、分类标准
机密性:保障数据不被未授权的用户访问或泄露
完整性:保证不被未授权的篡改,或者被篡改后能被迅速发现
可用性:保障已授权用户合法访问数据的权利
2、攻击现状
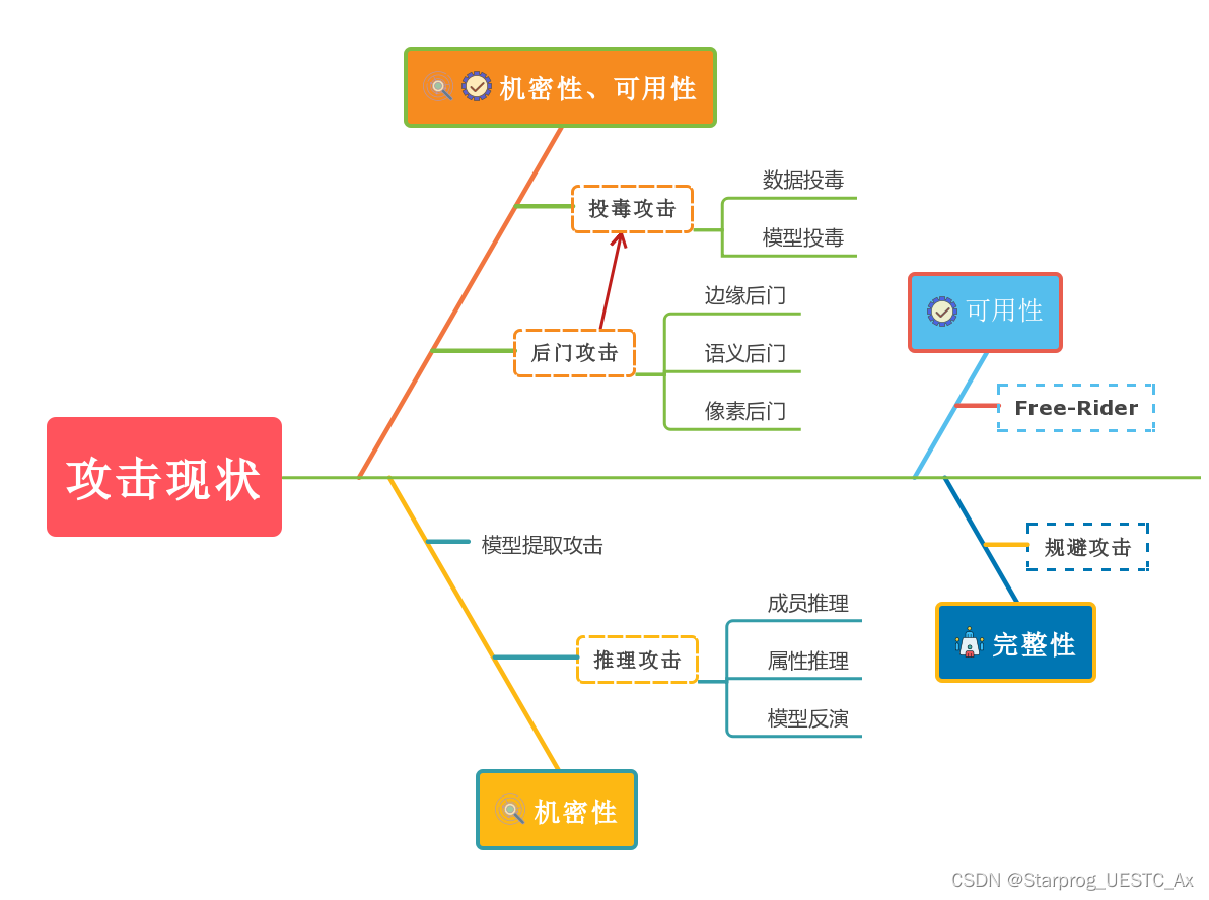
破坏机密性和可用性
投毒攻击:
可以在迭代一次的过程中,投毒一个客户端的一个模型,也可以在多轮迭代中,对多个客户端的模型进行投毒,这依据攻击者掌握的不同资源和技术进行
①数据投毒一般修改本地数据集的标签,传入聚合器时就会影响整体的训练
②模型投毒一般是修改训练中的附加参数,用boosting增加客户端的贡献来优化模型,增强攻击力
后门攻击
边缘后门,比如白色条纹的绿色汽车这类标签,可以从边缘案例(容易判错)中构造边缘案例数据集,执行本地训练,提高攻击准确性
语义攻击,把白色条纹的绿色汽车标签标记为鸟类,并boosting让这些标签也能起到干扰的作用
像素攻击,一般针对图象而言,修改单个像素,或一些敌对的样本和无误的样本一起训练,会有不错的效果
破坏机密性
推理攻击:
成员推理:推断某些数据是否属于训练数据集,提取私有信息后,修改本地模型参数
属性推理:利用模型的快照更新,比如经过训练的二进制分类器可以将属性与一些窃听所得的数据联系,判断更新是否拥有此目标属性
模型反演:给定标签进行反向推断,以确定模型的训练机理
模型提取攻击:
对手不知道模型内部的详细信息,即黑盒,模仿或完全复制目标模型,用oracle对模型的访问来迭代调整,最终重建模型执行攻击
破坏完整性
规避攻击:
就是精心制作现实世界存在的噪声,来绕过异常检测模型,来规避攻击(白盒)
破坏可用性
Free-Rider(搭便车攻击):
联邦学习中,每个贡献客户都可以获取金钱或最终模型作为奖励,可能存在一些客户端,为了获得更高权重贡献值而谎报参数,即搭便车者攻击
3、防御现状
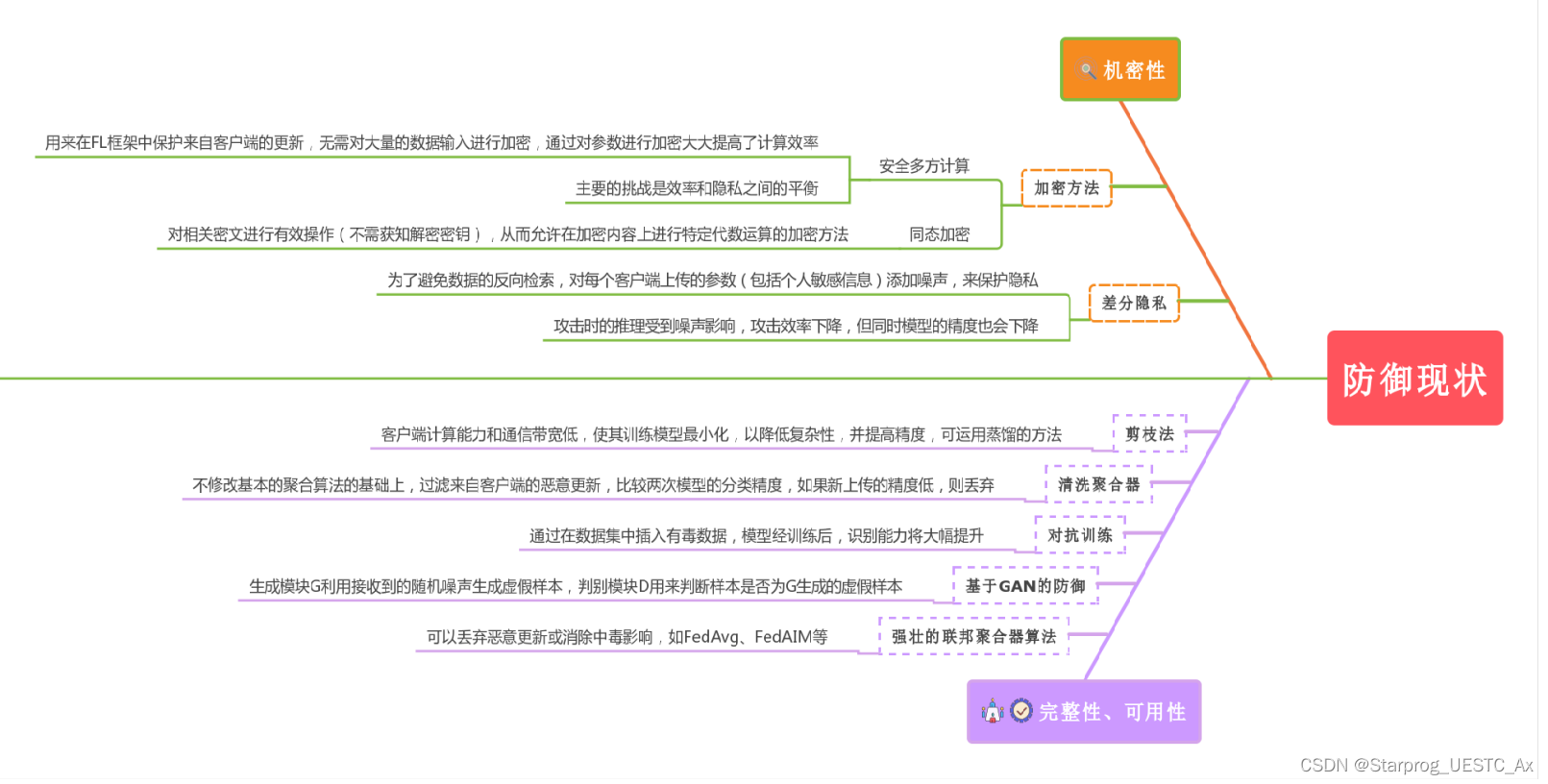
补充解释:上图中,差分隐私机制是针对推理攻击而言的,比如拿出100个人的数据去医院检测,测出10个人患病,第二天再拿出这100个人的99人去医院检测,测出9个人患病,那么经过推理,第二天没用到的那个人的一定是患病者,这就通过推理暴露了用户的安全隐私,从而可以被攻击者利用进行攻击。如果系统返回患病率而不返回具体的患病者(加入差分隐私算法),就会让攻击者攻击的概率大大降低,但我们得到的结果也不会那么精确,不知道具体患病是哪个人


















 137
137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











