






AI 幻觉,也被称为AI 虚构或 AI 编造,是指人工智能系统,尤其是像大型语言模型这类先进的 AI 技术,生成看似合理但实际上与事实严重不符或毫无根据的内容的现象。(一本正经的胡说八道)
AI 幻觉的 5 中类型
-
数据误用:有数据可用,但理解能力深度低,语境精确度高,外部信息整合能力高,逻辑推理和抽象能力中等。表现为误用已有数据,回答部分不符或细节错误 。
-
语境误解:有数据可用,理解能力深度高,语境精确度低,外部信息整合能力高,逻辑推理和抽象能力中等。表现为对问题意图理解错误,回答偏离主题。
-
信息缺失:无数据可用,理解能力深度中等,语境精确度高,外部信息整合能力低,逻辑推理和抽象能力中等。表现为未能正确获取或整合外部信息。
-
推理错误:部分数据可用,理解能力深度高,语境精确度高,外部信息整合能力中等,逻辑推理和抽象能力低。表现为逻辑推理存在漏洞或有错误假设。
-
无中生有:无数据可用,理解能力深度低,语境精确度中等,外部信息整合能力低,逻辑推理和抽象能力低。表现为在无数据支持下,生成完全虚构的信息。
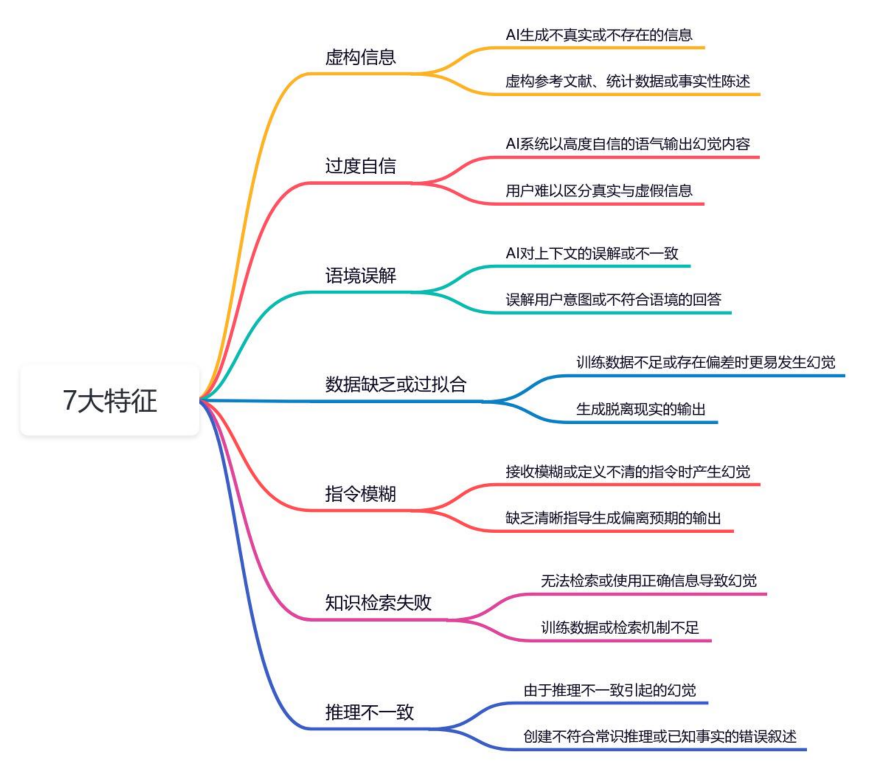
AI 幻觉的 7 个特性
如何降低 DeepSeek“幻觉”
DeepSeek“幻觉”为什么高?
R1在强化学习阶段去掉了人工干预,减少了大模型为了讨好人类偏好而钻空子,但单纯的准确性信号反馈,或许让R1在文科类的任务中把“创造性”当成了更高优先级。
首先需要声明一下:DeepSeek-R1 产生幻觉的概率比其他模型高……为什么?
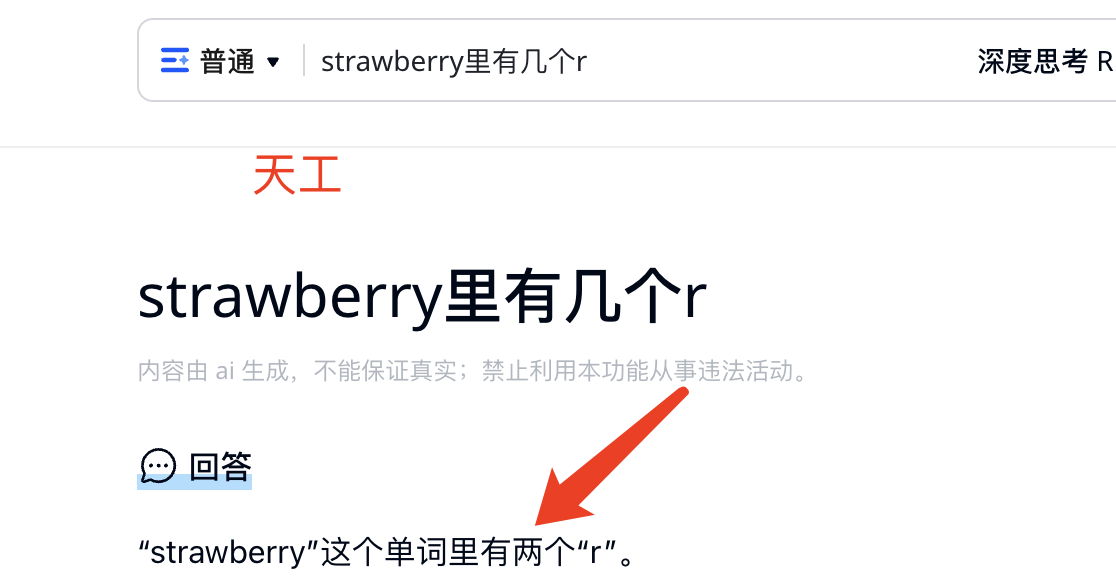
我们先看一个例子:
将问题:“strawberry里有几个r” 扔改大模型
豆包:

Claude:

天工:
智谱:

DeepSeek-R1:
深度思考了将近 2 分钟!


R1在数学相关的推理上极强,而在涉及到创意创造的领域非常容易胡编乱造。非常极端。
通过上面的例子我们可以看出,绝大多数大模型会回答“2个”。
因为这是模型之间互相“学习”传递的谬误,也说明了LLM的“黑盒子”境地,它看不到外部世界,甚至看不到单词中的最简单的字母。
而DeepSeek在经历了来回非常多轮长达100多秒的深度思考后,终于选择坚信自己推理出来的数字“3个”,战胜了它习得的思想钢印“2个”。
而这种强大的推理能力(CoT深度思考能力),是双刃剑。在与数学、科学真理无关的任务中,它有时会生成出一套自圆其说的“真理”,且捏造出配合自己理论的论据。
据腾讯科技,出门问问大模型团队前工程副总裁李维认为,R1比V3幻觉高4倍,有模型层的原因:
V3: query --〉answer
R1: query+CoT --〉answer
对于V3已经能很好完成的任务,比如摘要或翻译,任何思维链的长篇引导都可能带来偏离或发挥的倾向,这就为幻觉提供了温床。
降低幻觉的小技巧
如果是自己本地部署和自己训练数据,确保训练数据的高质量和多样性。
训练数据应做到标注来源、时效性和引用链,使用准确、权威的数据源,避免偏见和错误信息的引入。
此外,建立行业共享的“幻觉”黑名单库,杜绝使用可能会产生“幻觉”的内容。
使用的时候:
- 提问要具体:别问"怎么做菜",要问"番茄炒蛋的步骤"
- 像教小孩一样追问:当回答可疑时,继续问"这个数据是哪来的?"
- 看它有没有"证据":靠谱的回答应该像论文一样标明参考来源
小技巧:
- 使用 DeepSeek 的时候,先不要开 r1,先使用普通模式和他进行几轮对话,然后再开 r1进行对话
- 在提示词中加上“让我们一步步思考”,就能生成chain-of-thought(CoT),提高推理的准确性,减少幻觉。
- RAG,也就是检索增强生成,是先从一个数据集中检索信息,然后指导内容生成。
- 如果发现DeepSeek有自己脑补的内容,就可以直接告诉它,“说你知道的就好,不用胡说”
DeepSeek 它像一位固执的天才,既能用缜密逻辑推翻谬误,又可能在无拘无束的想象中构建空中楼阁。



















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











