






pytorch训练网络需要注意的细节(以及模板)
笔记:https://www.zybuluo.com/CQUyh/note/2234948
标签(空格分隔): Pytorch
以细胞分割图为例(Unet和Convnext)
1.model的搭建
这个不多说,是独立的模块,只需要注意输出输出是什么,输入通道和输出通道;一个小技巧,使用monai的框架,十分方便,但是注意load_weights时读取方式。
2.整个代码架构
model、dataset作为存放模型的文件,其中每一个epcoh(训练和测试)单独写在utils,这是工具文件夹。而整体的代码写在跟目录的train.py
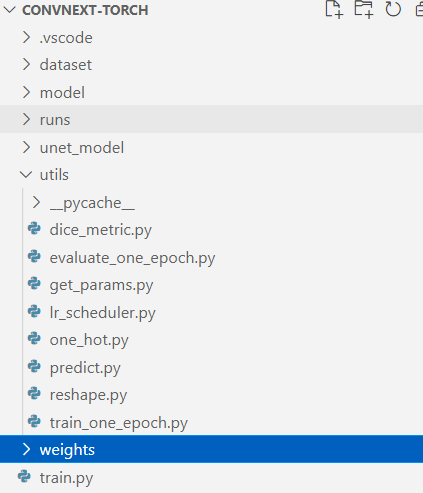
train.py:
①路径以及文件读取
②transform和dataset、dataloader
③定义模型,损失函数,优化器
④定义for训练,epcoh的for循环,最大层
main函数里面设置参数
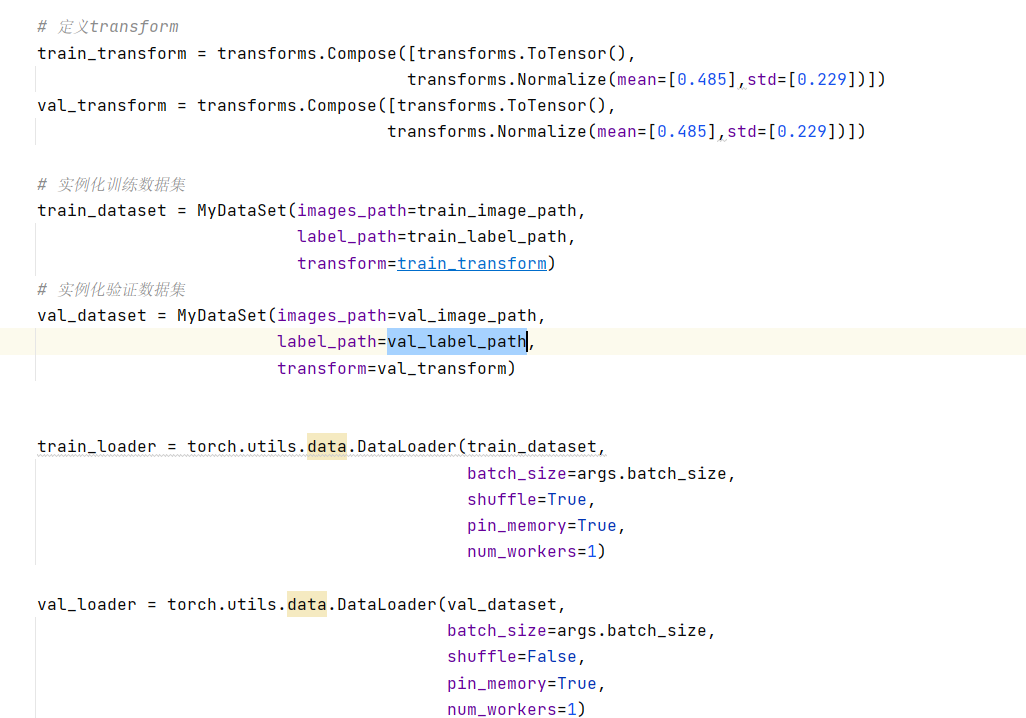

3.dataset(自定义)细节
①Transform
数据归一化一定要有(常用的参数),不然模型不收敛,对于简单的unet,收敛很慢很慢,对于复杂的,都不会变化。有没有决定你的模型好坏。(神经网络不收敛的原因:https://blog.csdn.net/weixin_39586997/article/details/118699735)
②一般步骤
ToTensor和Normlization:只有训练图片需要ToTensor(作用进行归一化,全部变到0-1),标签不需要进行任何transform,to_tensor都不需要可能(分情况,看像素值和one-hot)。标签具体需不需要其实看你标签本来的像素,像细胞图,像素点为0和255,需要进行norm到0和1,这样才是标准的,只是说我们默认标签值为0,1,2,3,4。
③PIL读取图像
因为torchvision支持PIL,经过ToTensor后得到[1,512,512],这里不需要扩充维度,因为dataloader会根据batchsize在读取时生成为[n,c,d,w,(h)]
③自定义dataset
这里使用PIL读取,因为transform支持PIL读取,它读取出来是一个类,然后是(3,256,256),CV读取是矩阵(256,256,3),需要转置一下,并且注意这里不需要返回加上n,因为dataloader读取的时候会根据batchsize来设置n的大小。
④常用函数
torch.Tensor是转化为float32,不要用torch.tensor; torch.transpose(data,dim1,dim2),根据维度来转置 ; torch.unsqueeze(data,dim=0)扩展一个维度。实现[d,w]->[1,d,w]
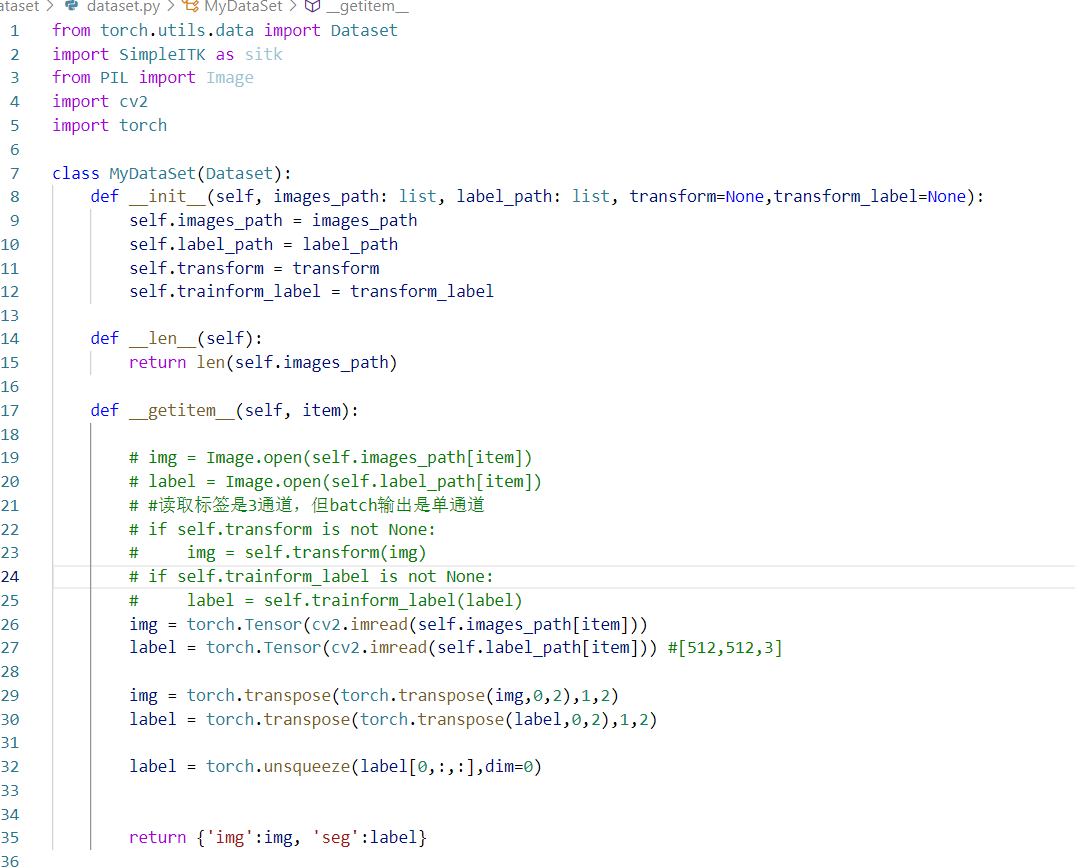
4.one-hot编码
①什么时候需要计算one-hot
首先是损失函数,之前总结过,哪些损失需要标签是one-hot,不需要one-hot,这个自己判断。然后就算计算dice是否需要one-hot(多分类一般都需要,保证pred和label一致channel)
②如何实现one-hot(亲测有效,多分类、二分类都可以,测试:one-hot ->argmax来imshow一下)
③细节:在one-hot那里对数据有要求,首先面前这个函数是正确的,以及用的v6的loss和dice计算不管几分类都是使用的通用模型。One-hot对细胞图,要求像素值小于分类数值,因此标准化为0,1;对于3d的数据,本来就是0,1,2,3,4,你还去ToTensor的话,就变成0.00XX,而one-hot那里要求数据转为long(),格式,会导致数据直接变为0,像素点全为0的后果。
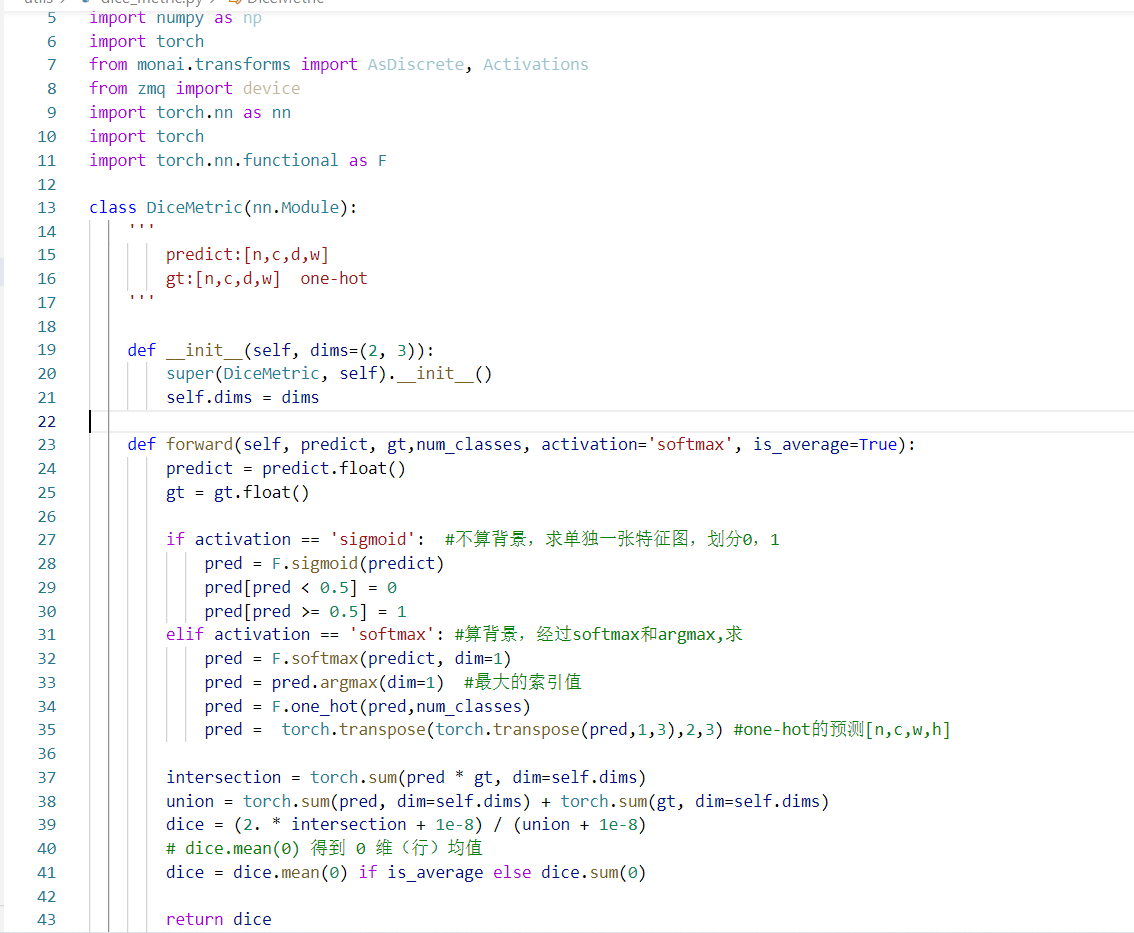
5.Dice计算方法
非常牛逼的计算方法,是几分类,就返回[背景,前景1,前景2,、、、]需要注意的是,里面选择sigmoid还是softmax,这个根据标签来选择,是否把背景看做一类,这个之前也总结过的。我习惯用softmax。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









