







论文题目:Neural 3D Mesh Renderer (CVPR 2018)
项目地址:https://hiroharu-kato.com/
源代码地址:https://github.com/hiroharu-kato/neural_renderer
目录
文章目录
一、论文的原理
背景知识
1 可微渲染
可微渲染指可以对各类三维表示进行合理渲染并回传渲染颜色关于渲染参数的梯度的一类渲染方法。基本上,需要用到三维表示的渲染结果关于渲染参数的梯度的地方都可以使用可微渲染。包括基于网格的可微渲染、基于点云的可微渲染、基于体素的可微渲染和基于隐式表示的可微渲染。
2 基于网格的可微渲染
网格模型的传统渲染管线包括一个叫作光栅化的步骤,此过程计算与每个图元 (对于三角网格是三角形) 相关的像素,是关于网格几何与像素位置的不连续函数,因此是不可微的。解决光栅化过程不可微的途径有两种:
-
保持渲染管线不变,对微分过程进行近似
-
修改渲染管线,绕过不可微的光栅化
论文概述
哪种三维表示在从2D图像建模3D世界的时候更合适?常见的表示方法有点云、体素和网格,其中多边形网格具有良好的紧致性和几何性质。然而,使用神经网络无法直接从二维图像生成一个三维网格,因为传统渲染管线中光栅化的过程阻止了反向传播。因此,作者提出了光栅化的近似梯度,使渲染集成到神经网络,并将这个渲染器称为Neural Renderer。使用这个渲染器,实现了轮廓图监督的单图像三维网格重建,重建效果比现有基于体素的方法更好;也可以实现二维图像监督下基于梯度的三维网格编辑,例如2D到3D的风格迁移和3D的DeepDream。
论文简介
从二维图像理解三维世界是计算机视觉的基本问题之一。从三维世界生成图像的过程叫做渲染。它位于三维世界和二维图像之间的边界,在计算机视觉中至关重要。近年来,卷积神经网络(convolutional neural networks, CNNs)在二维图像理解方面取得了很大的成功。因此,将渲染融入神经网络对三维理解具有很大的潜力。
那种三维表示更适合建模3D世界?通常使用体素、点云和多边形网格。体素作为像素的三维扩展,可以被CNN处理,因此在机器学习中使用最广泛;但很难处理高分辨率体素,因为它们一般从三维空间中采样得到,存储效率很很低。点云是三维点的集合,它基于不规则采样,因此可扩展性相对较高;但点云没有表面,很难实现纹理和照明。多边形网格由一组顶点和表面组成的,是可伸缩的,而且有表面,因此本文采用多边形网格三维表示。使用多边形网格表示有两个好处:第一个需要的参数少,模型和数据集也相应比较小;第二个是适合几何变换,对象的旋转、平移和缩放由顶点上的简单操作表示。这个属性也有助于训练三维理解的模型。
可以像训练神经网络一样训练一个包括渲染的系统吗?这是一个具有挑战性的问题。渲染包括将网格的顶点投影到屏幕坐标系上,并通过规则采样生成图像。尽管前者是可微的,但后者很难整合到其中,因为栅格化这种离散操作阻止了反向传播。为实现渲染的反向传播,文章提出了一种神经网络特有的渲染梯度近似方法,并将此渲染器称作Neural renderer。此渲染器可以使梯度流到纹理、光照、相机和物体形状等参数,因此适用于广泛的问题。
这篇论文主要有三个方面的贡献:
- 提出了一个对梯度进行近似的可微网格渲染器,使渲染集成到神经网络
- 实现了单图像三维网格重建,并且没有3D监督,其相对于基于体素方法更有优势
- 首次实现了基于梯度的三维网格编辑,包括2D到3D的风格迁移和3D的DeepDream
论文原理介绍
本节介绍论文所提出的对渲染梯度进行近似的原理。
1. 单面光栅化
假设 v i = ( x i , y i ) v_i=(x_i,y_i) vi=(xi,yi)是屏幕坐标系上某一顶点, I j I_j Ij是像素 P j P_j Pj的灰度值。假设 y i y_i yi是固定的,只考虑 I j I_j Ij随 x i x_i xi的变化。
- 当像素 P j P_j Pj位于三角面外侧,如图Figure 2所示,图(b)和©显示了 I j I_j Ij关于 x i x_i xi的函数和偏导数,当 v i v_i vi从 x 0 x_0 x0向右移动到 x 1 x_1 x1,像素 P j P_j Pj的颜色突变为覆盖它的面的颜色 I i j I_{ij} Iij。可以发现标准光栅化情况下,偏导数 ∂ I J ∂ x i \frac{\partial I_J}{\partial x_i} ∂xi∂IJ几乎处处为0。
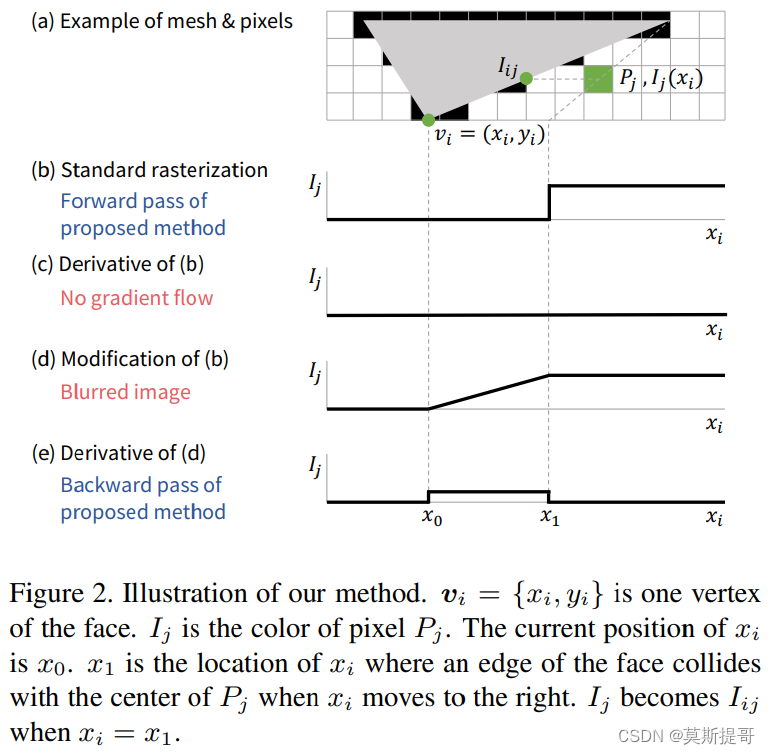
本文修改后的
I
j
I_j
Ij关于
x
i
x_i
xi的函数和偏导数如图(d)和(e)所示,作者对边缘部分进行了模糊处理,通过线性插值用连续的变化代替突变,进而产生了梯度值。设
δ
i
x
=
x
1
−
x
0
\delta^x_i=x_1-x_0
δix=x1−x0,
δ
j
I
=
I
(
x
1
)
−
I
(
x
0
)
\delta^I_j=I(x_1)-I(x_0)
δjI=I(x1)−I(x0),那么
x
0
x_0
x0和
x
1
x_1
x1之间的偏导数
∂
I
j
∂
x
i
=
δ
j
I
δ
i
x
\frac{\partial I_j}{\partial x_i}=\frac{\delta^I_j}{\delta^x_i}
∂xi∂Ij=δixδjI
设像素
P
j
P_j
Pj的误差值为
δ
j
P
\delta^P_j
δjP,该值表示像素
P
j
P_j
Pj应该变得更亮还是更暗。为减小误差,考虑以下情况,如果
δ
j
P
>
0
\delta^P_j>0
δjP>0,那么
P
j
P_j
Pj需要变得更暗;而
δ
j
I
\delta^I_j
δjI表示
P
j
P_j
Pj是否可以变得更亮或更暗,如果
δ
j
I
>
0
\delta^I_j>0
δjI>0,说明移动
x
i
x_i
xi只能使
P
j
P_j
Pj变得更亮。所以当
δ
j
P
>
0
\delta^P_j>0
δjP>0且
δ
j
I
>
0
\delta^I_j>0
δjI>0时,梯度不应该流动。因此,将
x
0
x_0
x0处的偏导数定义为
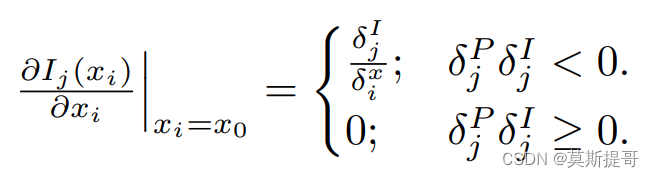
-
当像素 P j P_j Pj位于三角面内测,如图Figure 3所示, x 0 x_0 x0到 x 1 a x^a_1 x1a和 x 0 x_0 x0到 x 1 b x^b_1 x1b的导数依然通过线性插值得到。
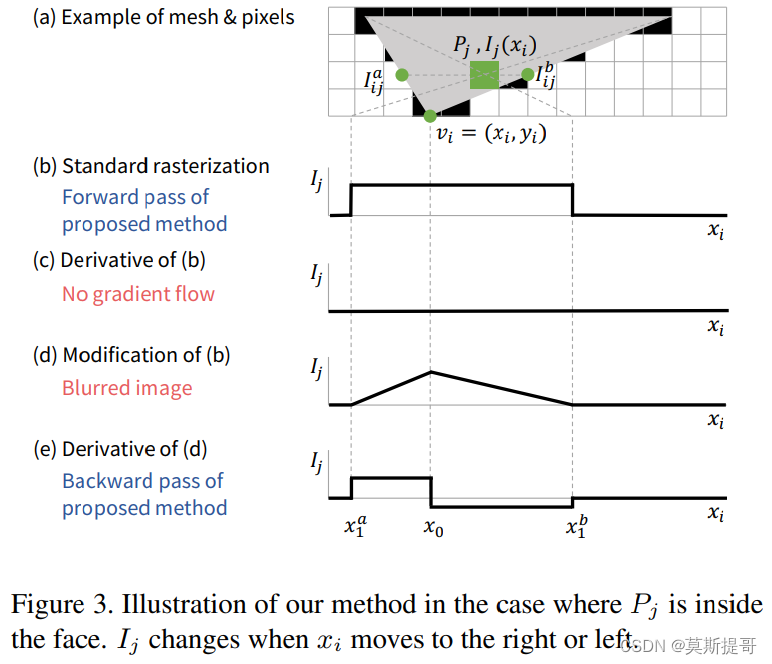
设 δ j I a = I ( x 1 a ) − I ( x 0 ) \delta^{I^a}_j=I(x^a_1)-I(x_0) δjIa=I(x1a)−I(x0), δ j I b = I ( x 1 b ) − I ( x 0 ) \delta^{I^b}_j=I(x^b_1)-I(x_0) δjIb=I(x1b)−I(x0), δ x a = x 1 a − x 0 \delta^a_x=x^a_1-x_0 δxa=x1a−x0, δ x b = x 1 b − x 0 \delta^b_x=x^b_1-x_0 δxb=x1b−x0,则 x 0 x_0 x0处的偏导数定义为
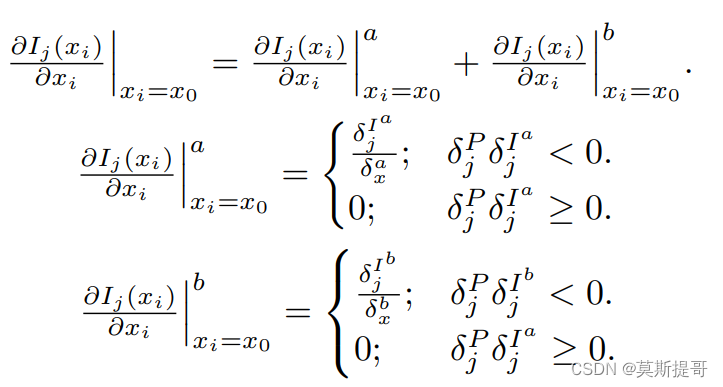
2. 多面光栅化
如果存在多个面,本文的渲染器在每个像素处,只绘制最前的面,在反向传播时,会首先检查是否绘制了与这个像素相对应的边上的交叉点 I i j I_{ij} Iij, I i j a I^a_{ij} Iija和 I i j b I^b_{ij} Iijb,如果它们被不包括 v i v_i vi的面遮挡,梯度不会流动。这是对网格模型传统渲染管线中,测试与混合步骤不可微的一种解决方案。
3. 纹理
本文的渲染器中,每个面都有一个大小为 s t × s t × s t s_t\times s_t\times s_t st×st×st的纹理图像。使用质心坐标确定三角面 { v 1 , v 2 , v 3 } \{v_1, v_2,v_3\} {v1,v2,v3}上某一点 p p p在纹理空间上的坐标。假设 p = w 1 v 1 + w 2 v 2 + w 3 v 3 p=w_1 v_1+w_2 v_2+w_3 v_3 p=w1v1+w2v2+w3v3,则该点对应纹理坐标是 ( w 1 , w 2 , w 3 ) (w_1,w_2,w_3 ) (w1,w2,w3)。显然,此过程是可微的。
4. 光照
本文渲染器使用了只包含了环境光
l
a
l^a
la和方向为
n
d
n^d
nd的平行光
l
d
l^d
ld的简单光照模型。像素颜色可表示为
I
j
l
=
(
l
a
+
(
n
d
∙
n
j
)
l
d
)
I
j
I_j^l=(l^a+(n^d∙n_j ) l^d ) I_j
Ijl=(la+(nd∙nj)ld)Ij
其中,
n
j
n_j
nj是表面法线方向。可见,梯度也可以流向光的强度
l
a
l^a
la和
l
d
l^d
ld,以及平行光方向
n
d
n^d
nd,光源也可以作为优化目标。
二、实验过程和结果
实验环境
硬件
- CPU:Intel® Core™ i7-9700K CPU @ 3.60GHz
- GPU:NVIDIA GeForce GTX 1660 Ti
软件
- Python3.9
- PyTorch 1.10.0
- Cuda 11.3
论文作者提供的源代码基于Chainer框架,仅支持python 2.x。于是,本次实验使用Nikos Kolotourosr的移植版本,该版本支持Python 2和Python 3,仅在Python 2.7+PyTorch 0.4.0上进行测试过。
环境配置与安装
为了使代码与Python 3,较新版本的PyTorch和Cuda兼容,需要对该版本的代码进行修改:
-
在下列C++源文件头部重定义宏AT_CHECK为TORCH_CHECK,以实现向上兼容
neural_renderer/neural_renderer/cuda/create_texture_image_cuda.cppneural_renderer/neural_renderer/cuda/load_textures_cuda.cppneural_renderer/neural_renderer/cuda/rasterize_cuda.cpp#include <torch/torch.h> // 重定义AT_CHECK宏为TORCH_CHECK #ifndef AT_CHECK #define AT_CHECK TORCH_CHECK #endif -
在下面的cuda源文件修改函数atomicAdd的定义
neural_renderer/neural_renderer/cuda/rasterize_cuda_kernel.cu// 将下面的代码删除或者注释 /* // for the older gpus atomicAdd with double arguments does not exist #if __CUDA_ARCH__ < 600 and defined(__CUDA_ARCH__) static __inline__ __device__ double atomicAdd(double* address, double val) { unsigned long long int* address_as_ull = (unsigned long long int*)address; unsigned long long int old = *address_as_ull, assumed; do { assumed = old; old = atomicCAS(address_as_ull, assumed, __double_as_longlong(val + __longlong_as_double(assumed))); // Note: uses integer comparison to avoid hang in case of NaN (since NaN != NaN) } while (assumed != old); } while (assumed != old); return __longlong_as_double(old); } #endif */ // 替换为如下的代码 // for the older gpus atomicAdd with double arguments does not exist #if !defined(__CUDA_ARCH__) || __CUDA_ARCH__ >= 600 #else static __inline__ __device__ double atomicAdd(double* address, double val) { unsigned long long int* address_as_ull = (unsigned long long int*)address; unsigned long long int old = *address_as_ull, assumed; do { assumed = old; old = atomicCAS(address_as_ull, assumed, __double_as_longlong(val + __longlong_as_double(assumed))); } while (assumed != old); return __longlong_as_double(old); } #endif -
在项目根目录下使用命令
python setup.py install安装neural_renderer_pytorch模块。
实验过程及结果
Neural Renderer有4个样例代码,路径为neural_renderer/neural_renderer-master-pytorch/examples,通过输入以下命令分别运行样例代码:
python ./examples/example1.py
python ./examples/example2.py
python ./examples/example3.py
python ./examples/example4.py
-
样例1. 从多个视角绘制茶壶模型
朴素地从多个视角渲染茶壶模型,绘制结果为example1.gif,保存在./result文件夹中。其中两帧的绘制结果如下图:

-
样例2. 优化顶点
通过优化顶点坐标,将茶壶模型的指定视角拟合为参考图中的正方形。参考图片如下图:

损失函数为渲染的轮廓图与参考图之间残差的平方和(Square loss),因此重写的forward方法如下:
def forward(self): self.renderer.eye = nr.get_points_from_angles(2.732, 0, 90) # 相机距离,高度,方位角 image = self.renderer(self.vertices, self.faces, mode='silhouettes') loss = torch.sum((image - self.image_ref[None, :, :])**2) return loss优化结果如下:

-
样例3. 优化材质
通过将梯度流动到材质参数,为茶壶模型上色。参考材质图片如下图:

如论文所介绍,在此样例中每个面都有一个 4 × 4 × 4 4\times 4\times 4 4×4×4大小的材质(共2464个面),材质颜色包括RGB三个通道,因此材质参数量为 1 × 2464 × 4 × 4 × 4 × 3 1\times 2464 \times 4\times4\times4\times3 1×2464×4×4×4×3。因此,在初始化网络模型时对材质参数进行如下定义:
texture_size = 4 textures = torch.zeros(1, self.faces.shape[1], texture_size, texture_size, texture_size, 3, dtype=torch.float32) self.textures = nn.Parameter(textures)在前向传播时,随机设定一个渲染的相机方位角,然后计算该方位角下渲染的模型图像与参考图像的平方误差,重写的forward方法如下:
def forward(self): self.renderer.eye = nr.get_points_from_angles(2.732, 0, np.random.uniform(0, 360)) # 相机方位角随机 image, _, _ = self.renderer(self.vertices, self.faces, torch.tanh(self.textures)) loss = torch.sum((image - self.image_ref) ** 2) return loss优化得到的茶壶模型的渲染效果如下图:

-
样例4. 拟合相机参数
根据提供茶壶的参考图片,拟合该未知视角,解出视角值。参考图是茶壶在某视角下的图片。

初始化网络模型时,相机视角参数(距离、高度和方位角)的初始值分别设置为6、10和-14,该视角下的茶壶模型如下图所示:

其对应代码如下:
self.camera_position = nn.Parameter(torch.from_numpy(np.array([6, 10, -14], dtype=np.float32)))损失函数依然是当前相机视角下的轮廓图与参考视角图片的平方误差:
def forward(self): image = self.renderer(self.vertices, self.faces, mode='silhouettes') loss = torch.sum((image - self.image_ref[None, :, :]) ** 2) return loss优化得到的相机视角参数值为:

下图给出了茶壶在相机参数优化过程的渲染结果:

三、分析优缺点
优点
- 论文就传统网格模型渲染管线光栅化过程不可微的问题,提出了一种对光栅化梯度进行近似的方法,使得渲染管线可以集成到神经网络中。
- 使用本文提出的Neural renderer,可以使梯度流到纹理、光照、相机和物体形状等参数,适用于广泛的问题。
缺点
- 本文所提出的渲染器假定了网格模型顶点和面的对应关系不变,因此不能生成具有各种拓扑的对象。为了克服这个限制,在未来的工作中有必要动态生成面-顶点关系。
参考
[1] Kato H, Ushiku Y, Harada T. Neural 3d mesh renderer[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 3907-3916.
[2] 叶子鹏, 夏雯宇, 孙志尧, 等. 从传统渲染到可微渲染: 基本原理, 方法和应用[J]. 中国科学: 信息科学, 2021, 51(7): 1043-1067.
[3] 可训练的神经三维网格渲染器(Neural 3D Mesh Renderer)

















 4905
4905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









