








Abstract
对于二维图像背后的三维世界的建模,哪种三维表示法最合适?多边形网格因其紧凑性和几何特性而成为一个有希望的候选者。然而,使用神经网络从二维图像建立多边形网格模型并不简单,因为从网格到图像的转换,或者说转折,涉及到一个被称为栅格化的离散操作,这阻碍了反向传播的进行。因此,在这项工作中,我们提出了一个光栅化的近似梯度,使渲染与神经网络相结合。使用这种渲染器,我们在剪影图像的监督下进行单图像三维网格的重新构建,我们的系统优于现有的基于体素的方法。此外,我们首次在二维监督下进行了基于梯度的三维网格编辑操作,如二维到三维的风格转换和三维DeepDream。这些应用证明了将网格渲染器整合到神经网络中的潜力,以及我们所提出的渲染器的有效性。
1、介绍
从二维图像中理解三维世界是计算机视觉的基本问题之一。人类利用视网膜上的图像在大脑中建立三维世界的模型,并利用所构建的模型进行日常的生活。机器也可以通过明确地对二维图像背后的三维世界进行建模而更加智能地行动。
从三维世界生成图像的过程被称为渲染。因为它位于三维世界和二维图像之间的边界上,所以在计算机视觉中是至关重要的。
近年来,卷积神经网络(CNN)在二维图像下取得了相当大的成功[7, 13]。因此,将渲染纳入神经网络在三维理解方面有很大的潜力。
哪种类型的三维表示法最适合于为三维世界建模?常用的三维格式是体素、点云和多边形网格。体素是像素的三维扩展,是机器学习中最广泛使用的格式,因为它们可以被CNN处理[2, 17, 20, 24, 30, 31, 34, 35, 36]。然而,处理高分辨率的体素是很困难的,因为它们是从三维空间有规律地取样的,其内存效率很差。点云是三维点的集合,其可扩展性相对较高,因为点云是基于不规则采样的。然而,由于点云没有表面,所以很难应用纹理和照明。多边形网格,由顶点和表面组成,是有希望的,因为它们是可扩展的,并且有表面。因此,在这项工作中,我们使用多边形网格作为我们的三维格式。
在三维理解中,多边形网格相对于其他代表的一个优势是其紧凑性。例如,为了表示一个大的三角形,多边形网格只需要三个顶点和一个面,而体素和点云需要在面上有许多采样点。由于多边形网格以少量的参数来表示三维形状,因此可以使三维理解的模型大小和数据集大小更小。
另一个优点是它适合于几何变换。物体的旋转、平移和缩放是通过对顶点的简单操作来表示的。这一特性也有利于训练三维理解模型。
我们能不能把包括渲染在内的系统训练成一个神经网络?这是一个具有挑战性的问题。渲染包括将网格的顶点投射到屏幕坐标系上,并通过有规律的网格采样生成图像[16]。虽然前者是一个可微分的操作,但后者,即栅格化,是很难整合的,因为离散操作阻止了反向传播。
因此,为了实现渲染的反向传播,我们提出了一个神经网络特有的近似梯度的渲染方法,这有利于系统的端到端训练,包括渲染。我们提出的渲染器可以将梯度流入纹理、照明和相机以及物体形状。因此,它可以适用于广泛的问题。我们将我们的渲染器命名为 "神经渲染器"。
在计算机视觉和机器学习的生成方法中,问题是通过对数据生成的过程进行建模和垂直化来解决的。图像是通过三维世界的渲染产生的,而多边形网格是一种高效、丰富和直观的三维表示。因此,网格渲染器的 "后向传递 "是非常重要的。
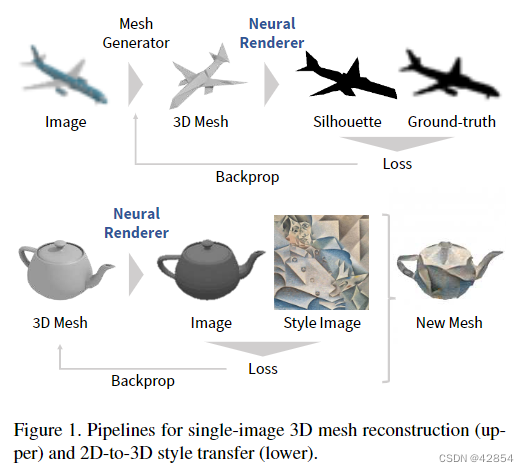
在这项工作中,我们提出了图1中所示的两个应用。第一个是用剪影图像监督的单图像三维网格重建。尽管三维重建是计算机视觉的主要问题之一,但很少有研究从单一图像中重建网格,尽管这种方法具有潜在的能力。另一个应用是基于梯度的三维网格编辑与二维监督。这包括一个三维版本的风格转移[6]和DeepDream[18]。由于体素或点云没有光滑的表面,没有可微分的网格渲染器就无法实现这一任务。
主要贡献可归纳为以下几点:
- 我们提出了一种近似梯度的网格渲染方法,它可以将渲染工作整合到神经网络中。
- 我们在没有三维监督的情况下从单一图像进行三维网格重建,并证明我们的系统比基于体素的方法更有优势。
- 我们首次使用 2D 监督执行基于梯度的 3D 网格编辑操作,例如 2D 到 3D 样式转换和 3D DeepDream。
- 我们将发布神经渲染器的代码。
2、相关工作
在这一节中,我们简要介绍了三维代表如何被整合到神经网络中。我们还总结了与我们两个应用相关的工作。
2.1. 神经网络中的三维表征
三维表示法分为光栅化和几何形式。栅格化形式包括体素和多视图RGB(D)图像。几何形式包括点云、多边形网格和基元集。
栅格化的形式被广泛使用,因为它们可以被CNN处理。体素是像素的三维扩展,被用于分类[17, 20, 24, 34, 35]、三维重建和生成[2, 30, 31, 34, 36]。由于体素的记忆效率很差,一些再中心的工作已经纳入了更有效的代表[24, 30, 32]。多视图RGB(D)图像,通过一组图像代表一个三维场景,被用于识别[20, 27]和视图合成[29] 。
几何形式需要进行一些修改才能被纳入神经网络中。例如,处理点云的系统必须对点的顺序不发生变化。点云已经被用于识别[12, 19, 21]和重建[5]。基于基元的表示法,即用一组基元(如立方体)来表示三维物体,也被研究过[14, 39]。
多边形网格将一个三维物体表示为一组顶点和表面。因为它的内存效率高,适合于几何变换,并且具有曲面,所以它是计算机图形(CG)和计算机辅助设计(CAD)中事实上的标准形式。然而,由于多边形网格的数据结构是一个复杂的图形,它很难集成到神经网络中。虽然识别和分割已经被研究过了[10, 38],但基因分析任务要困难得多。Rezende等人[23]将OpenGL渲染器纳入一个用于三维网格重建的神经网络。使用REINFORCE[33]来估计黑盒渲染器的梯度。相比之下,我们的渲染器中的梯度是以几何为基础的,可能会更准确。OpenDR[15]是一个可微分渲染器。与这个通用的渲染器不同,我们提出的梯度是为神经网络设计的。
2.2. 单一图像的三维重建
从图像中估计三维结构是计算机视觉中的一个传统问题。随着机器学习算法的最新进展,从单一图像进行三维重建已成为一个活跃的研究课题。
大多数方法利用 ground truth 的三维模型学习二维到三维的映射函数。虽然有些作品通过深度预测来重建三维结构[4, 25],但其他作品则直接预测三维形状[2, 5, 30, 31, 34]。
单一图像的三维重建可以在没有三维监督的情况下实现。透视变换器网(PTN)[36]利用多个视角的剪影图像学习三维结构。我们的三维重建方法也是基于剪影图像的。然而,我们使用多边形网格,而他们使用体素。
2.3. 通过梯度下降进行图像编辑
使用一个可微分的特征提取器和损失函数,可以通过反向传播和梯度下降生成一个损失最小的图像。DeepDream[18]是这种系统的一个早期例子。一个初始图像被反复更新,使其图像特征的幅度变大。通过这个过程,狗和汽车等物体逐渐出现在图像中。
图像风格转移[6]可能是最熟悉和实用的例子。给定一个内容图像和风格图像,就会生成一个具有指定内容和风格的图像。
我们的渲染器提供了与网格的顶点和纹理有关的图像梯度。因此,通过使用二维图像上的损失函数,来实现网格的 Deep-Dream 和样式迁移。
3、用于渲染的近似梯度
在这一节中,我们将介绍Neural Renderer,它是一个带有梯度流的3D网格渲染器。
3.1. 渲染管线及其衍生物
一个三维网格由一组顶点{vo1, vo2, …, voNv }和面{f1, f2, …, fNf }组成,其中物体有Nv个顶点和Nf个面。 voi∈R3代表第i个顶点在三维物体空间中的位置,fj∈N3代表对应于第j个三角形面的三个顶点的索引。为了渲染这个物体,物体空间中的顶点{voi }被转换为屏幕空间中的顶点{vsi },vsi∈R2。这种变换是由可微分变换的组合来表示的[16]。
一个图像是由{vsi }和{fj }通过采样产生的。这个过程被称为光栅化。图2(a)说明了单个三角形的光栅化情况。在光栅化过程中,每个像素都被涂上与之相邻的三角形面的颜色。由于这是一个离散的操作,像素的颜色不能通过面的位置来区分。这就造成了反向传播中的一个问题。
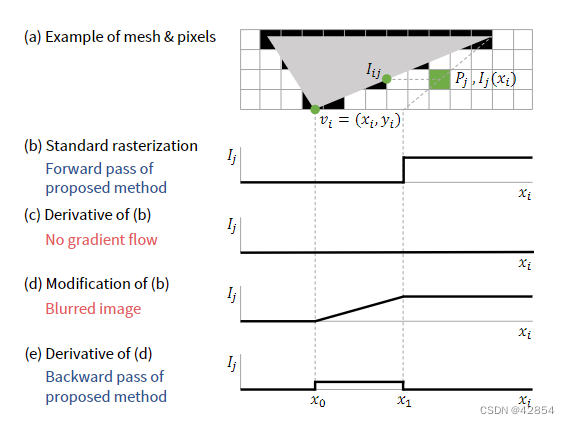
图 2. 我们方法的说明。 vi = {xi, yi} 是面的一个顶点。 Ij 是像素 Pj 的颜色。 xi 的当前位置是 x0。 x1 是当 xi 向右移动时面边缘与 Pj 中心碰撞的 xi 位置。当 xi = x1 时,Ij 变为 Iij
3.2. 单面光栅化
为了便于解释,我们用屏幕空间中单个顶点vi = vsi的x坐标xi和单个灰度像素Pj来描述我们的方法。我们认为Pj的颜色是一个关于xi的函数Ij (xi),并冻结除xi以外的所有变量。
首先,我们假设Pj在面之外,如图2(a)所示。当xi在当前位置x0时,Pj的颜色是I(x0)。如果xi向右移动并到达点x1,即面的一条边与Pj的中心相撞,Ij(xi)突然变成了撞击点Iij的颜色。让δxi为xi走过的距离,让δxi = x1 - x0,让δIj代表颜色的变化δIj = I(x1)-I(x0)。如图2(b-c)所示,部分导数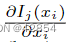 几乎到处都是零。
几乎到处都是零。
因为梯度为零,如果xi向右移动δxi,Ij (xi)可以被δIj改变的信息就不会传递给xi。这是因为Ij(xi)突然发生了变化。因此,我们用线性插值法在x0和x1之间的逐渐变化来代替突然变化。然后,∂Ij /∂xi变成x0和x1之间的δI j/ δxi,如图2(d-e)所示。
Ij (xi)的导数在x0的右边和左边是不同的。应该如何定义xi = x0处的导数?我们建议使用误差信号δPj反向传播到Pj来切换数值。δPj的符号表示Pj是应该更亮还是更暗。为了使损失最小化,如果δPj>0,那么Pj必须是暗的。另一方面,δIj的符号表示Pj是否可以变亮或变暗。如果δIj>0,Pj通过拉入xi变得更亮,但Pj不能通过移动xi变得更暗。因此,如果δPj>0且δIj>0,则梯度不应该流动。从这个角度出发,我们定义∂Ij(xi) /∂xi |xi=x0如下。
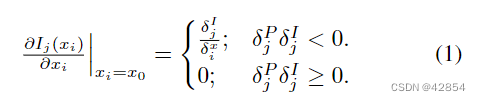
有时,无论xi在哪里移动,面都不会与Pj重叠。这意味着x1并不存在。在这种情况下,我们定义
我们使用图2(b)进行正向传递,因为如果我们使用图2(d),脸部的颜色就会漏到脸部之外。因此,我们的光栅器产生的图像与标准光栅器相同,但它的梯度不为零。
通过交换上述讨论中的x轴和y轴,可以得到相对于yi的导数。
接下来,我们考虑Pj在面内的情况,如图3(a)所示。在这种情况下,当xi向右或向左移动时,I(xi)会发生变化。图3(b-e)中显示了标准栅格化、其导数、插值函数及其导数。我们首先计算x0的左右两边的导数,并让它们的总和成为x0处的梯度。具体来说,使用图3中的符号,δIa j = I(xa 1) - I(x0), δIb j = I(xb 1) - I(x0), δax = xa 1 - x0 和 δbx = xb 1 - x0,我们定义损失如下。
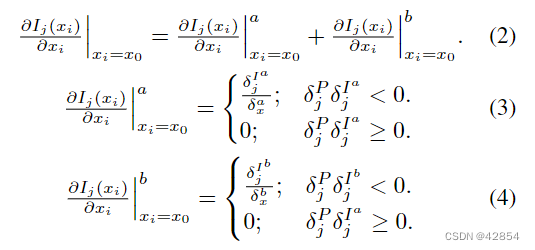
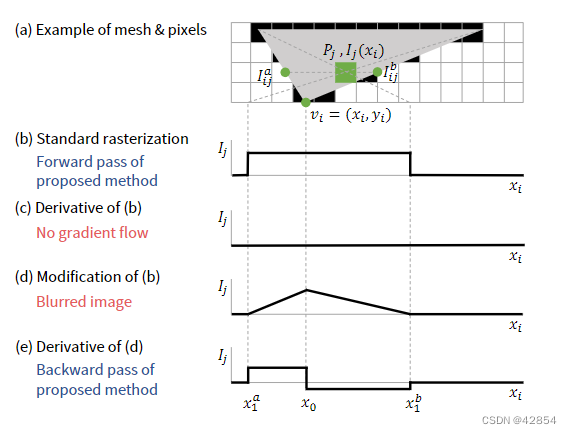
图3. 在Pj位于面内的情况下,我们的方法的说明。当xi向右或向左移动时,Ij发生变化。
3.3. 多个面的光栅化
如果有多个面,我们的光栅器在每个像素上只绘制最前面的面,这与标准方法[16]相同。在反向传播过程中,我们首先检查是否绘制了交叉点 Iij 、 Iaij 和 Ibij ,如果它们被不包括 vi 的表面遮挡,则不流动梯度。
3.4. 纹理
纹理可以被映射到面部。在我们的实现中,每个面都有自己的纹理图像,大小为st ×st ×st。我们使用中心点坐标系统确定纹理空间中对应于三角形{v1, v2, v3}上一个位置p的坐标。换句话说,如果p被表示为p = w1v1 + w2v2 + w3v3,让(w1, w2, w3)成为纹理空间中的相应坐标。双线性插值被用于从纹理图像中取样。
3.5. 照明
照明可以直接应用在网格上,而不像像素和点云。在这项工作中,我们使用一个简单的环境光和没有阴影的方向光。让la和ld分别是环境光和方向光的强度,nd是表示方向光方向的单位向量,nj是表面的法向量。然后,我们将表面上一个像素Ilj的修正颜色定义为Ilj = (la + (nd - nj ) ld) Ij。
在这个公式中,梯度也流入强度 la 和 ld,以及定向光的方向 nd。因此,光源也可以作为优化目标。
4、神经渲染器的应用
我们将我们提出的渲染器应用于(a)带有剪影图像监督的单图像3D 重建和(b)基于梯度的 3D 网格编辑,包括 3D 版本的样式转移 [6] 和 DeepDream [18]。从一个视角φi渲染的网格m的图像被表示为R(m, φi)。
4.1. 单一图像的三维重建
Yan等人[36]证明了在没有三维训练数据的情况下也可以实现单幅图像的三维重新构建。在他们的设定中,图像x上的三维生成函数G(x)被训练成这样:假设视角{φi}是已知的,预测的三维形状的剪影{ˆsi=R(G(x), φi)}与 ground truth 剪影{si}相匹配。这个管道在图1中得到说明。Yan等人[36]生成的是体素,而我们生成的是网格。
虽然体素可以通过扩展现有的图像生成器[8, 22]来生成三维空间,但网格的生成却不是那么简单。在这项工作中,我们不是从头开始生成网格,而是对预定义的网格进行变形来生成一个新的网格。具体来说,我们使用一个具有642个顶点的各向同性的球体,使用局部偏置向量bi和全局偏置向量c将每个顶点vi移动为vi+bi+c。面{fi}是没有变化的。因此,G(x)的中间输出是b∈R^642×3和 c∈R^1×3。我们使用的网格是由642×3的参数指定的,这远远小于典型的体素表示,其大小为 32^3。这种低维度估计对形状估计是有利的。
生成函数G(x)是用剪影损失Lsl和平滑度损失Lsm训练的。 剪影损失表示重建的剪影{ˆsi}与正确的剪影{si}有多大差别。平滑度损失代表了网格表面的平滑程度,并作为一个正则器发挥作用。目标函数是这两个损失函数的加权和 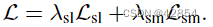 。
。
设{si}和{ˆsi}为 binary masks,θi为包括G(x)中第i条边在内的两个面之间的角度,E为G(x)中所有边的集合,⊙为元素相乘。我们将损失函数定义为:
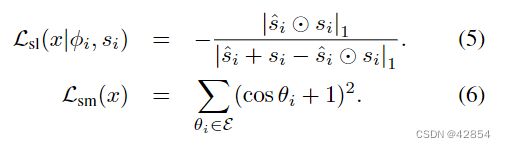
Lsl对应于真实的和重建的剪影之间的负交集(IoU)。Lsm确保所有面孔的交角都接近180度。
我们假设图像中的物体区域是通过预处理来分割的,这与现有的工作[5, 31, 36]相同。我们将物体区域的 mask 作为RGB图像的一个附加通道输入生成器。
4.2. 基于梯度的三维网格编辑
基于梯度的图像编辑技术[6, 18]通过梯度下降使二维图像x上的损失函数L(x)最小化来生成图像。在这项工作中,我们不是生成一个图像,而是根据其渲染的图像R(m|φi)来优化一个由顶点{vi}、面{fi}和纹理{ti}组成的三维网格m。(从一个视角φi渲染的网格m的图像被表示为R(m, φi)。)
4.2.1 2D-to-3D style transfer
在本节中,我们提出了一种将图像xs的风格转移到网格mc上的方法。
对于二维图像,风格转移是通过同时最小化内容损失和风格损失来实现的[6]。具体来说,内容损失是用一个特征提取器fc(x)和内容图像xc定义为Lc(x|xc) = |fc(x) - fc(xc)|2 2。风格损失是用另一个特征提取器fs(x)和风格图像xs定义的,即Ls(x|xs) = |M (fs(x)) - M (fs(xs))|2 F 。M (x)将一个向量转化为一个 Gram 矩阵。
在二维到三维的风格转换中,内容被指定为三维网格mc。为了使生成的网格形状与mc相似,假设两个网格的顶点与面的关系{fi}相同,我们重新定义content loss为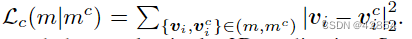 。我们使用与二维应用中相同的风格损失。具体来说,
。我们使用与二维应用中相同的风格损失。具体来说,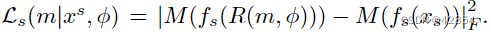 。我们还使用正则器来降低噪音。让P表示图像R(m, φ)中所有相邻像素对的颜色集合。我们把这个损失定义为Lt(m|φ) =∑ {pa,pb}∈P |pa - pb|2 2。
。我们还使用正则器来降低噪音。让P表示图像R(m, φ)中所有相邻像素对的颜色集合。我们把这个损失定义为Lt(m|φ) =∑ {pa,pb}∈P |pa - pb|2 2。
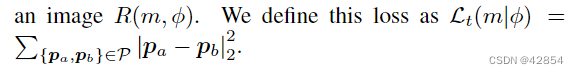
目标函数为L = λcLc + λsLs + λtLt。我们设定m的初始解为mc,并使L相对于{vi}和{ti}最小。
(顶点{vi}、面{fi}和纹理{ti}组成的三维网格m)
4.2.2 3D DeepDream
让f (x)成为一个函数,输出图像x的特征图。对于二维图像,图像x0的DeepDream是通过梯度下降从x=x0开始最小化-|f (x)|2 F来实现的。迭代几次后,优化就停止了。按照类似的过程,我们对{vi}和{ti}最小化-|f (R(m, φ))|2 F。
5、实验
在本节中,我们通过这两个应用程序评估渲染器的有效性。
5.1. 单一图像的三维重建
5.1.1 实验设置
为了比较我们的基于网格的方法和Yan等人[36]的基于体素的方法,我们使用了与他们几乎相同的数据集1。我们使用了ShapeNetCore[1]数据集中的13个类别的三维物体。在相同的相机设置和照明设置下,使用Blender从24个方位角和一个固定的仰角对图像进行渲染。渲染尺寸为64×64像素。我们使用的训练、验证和测试集与[36]中使用的相同。
- ShapeNetCore。这个数据集包含了来自55个常见物体类别的大约51,300个独特的3D模型[1]。每个三维模型在相同的相机和照明设置下,从24个方位角(步长为15◦)和固定仰角(30◦)进行渲染。
(1:我们使用的数据集与[36]中使用的数据集不完全相同。输入图像的渲染参数也略有不同。通常,我们的剪影图像是由Blender从ShapeNetCore数据集中的网格渲染出来的,而他们的图像是由他们的PTN使用体素化数据渲染出来的。)
我们比较了基于体素的方法和基于检索的方法[36]的重建精度。在基于体素的方法中,G(x)由一个卷积编码器和去卷积解码器组成。虽然他们的编码器是用Yang等人[37]的方法预训练的,但我们的网络不需要任何预训练就能很好地工作。在基于检索的方法中,使用预先训练好的VGG网络[26]的fc6特征来重新评价最近的训练图像。相应的体素被认为是预设的形状。请注意,基于检索的方法使用地面真实体素进行监督。
为了定量评估重建性能,我们对地面真实网格和生成的网格都进行了体素化,以计算体素之间的交集大于联合(IoU)。体素的大小被设定为323。对于测试集中的每个物体,我们使用24个视点的图像进行三维重建,计算IoU的分数,并报告平均分数。
我们对生成器G(x)使用了一个编码器-解码器结构。我们的编码器与[36]的编码器几乎相同,后者将输入图像编码为512D的向量。我们的解码器由三个全连接的层组成。隐藏层的大小为 1024 和 2048。
我们渲染器的渲染大小设置为 128 × 128 并将它们下采样到 64 × 64。我们只渲染了对象的剪影,而不使用纹理和照明。我们在 5.1.2 节中设置 λsl = 1 和 λsm = 0.001,在 5.1.3 节中设置 λsm = 0。我们使用 α = 0.0001 的 Adam 优化器 [11] 训练我们的生成器。批量大小设置为 64。在每个小批量中,我们在每个输入图像中包含来自两个视点的剪影。
5.1.2 定性评价
我们用每个类别的图像训练了13个模型。图4展示了我们基于网格的方法和基于体素的方法[36]2在测试集中的部分结果。更多的结果在补充材料中列出。这些结果表明,使用我们的方法可以从单个图像中正确地重建网格。

图4. 从单一图像进行的三维网格重建。结果从三个视角呈现。第一列:输入图像。第二列到第四列:网格重建(建议的方法)。第五列到第七列:体素重建[36] 。
与基于体素的方法相比,我们的方法重新构建的形状从两点来看更具有视觉吸引力。其一是网格可以用高分辨率表示小部件,如飞机机翼。另一个原因是,网格中没有立方体伪影。尽管低分辨率和伪影在机器人采摘等任务中可能不是问题,但对于计算机图形学、计算摄影和数据增强来说,它们是不利的。
如果不使用平滑度损失,我们的模型有时会产生非常粗糙的表面。这是因为表面的光滑度对剪影的影响很小。有了平滑度正则器,表面变得更平滑,看起来更自然。图5说明了正则器的有效性。然而,如果使用正则器,整个数据集的体素IoU变得略低。

图5. 使用/不使用平滑度正则器生成CRT显示器的背面。左:输入图像。中间:没有正则器的预测。右图:使用正则器的预测。
5.1.3 定量评价
我们使用所有类别的图像来训练一个单一的模型。重建的准确性见表1。我们基于网格的方法在13个类别中的10个类别中优于基于体素的方法[36]。在飞机、椅子、显示器、扬声器和沙发等类别中,我们的结果明显更好。扬声器和显示器类别的基本形状很简单。然而,尺寸和位置因物体而异。网格适合于缩放和平移的事实可能有助于这些类别的性能改进。飞机、椅子和沙发类别中的形状变化也相对较小。
我们的方法在汽车、灯和桌子类别中表现得不是很好。这些类别中物体的形状相对复杂,很难通过变形球体来重建。
5.1.4 限制条件
尽管我们的重建方法在视觉效果和体素IU方面已经超过了基于体素的方法,但它有一个明显的缺点,即它不能生成具有各种拓扑结构的物体。为了克服这一限制,有必要动态地生成面与顶点的关系{fi}。这超出了本研究的范围,但这是未来重新搜索的一个有趣方向。
5.2. 通过二维损失进行基于梯度的三维编辑
5.2.1 实验设置
我们对图6所示的物体应用了二维到三维的风格转换和三维DeepDream。使用Adam优化器[11]进行优化,β1 = 0.9,β2 = 0.999。我们渲染了大小为448×448的图像,并将其降频为224×224以消除混叠。批量大小被设置为4。在优化过程中,图像以随机的仰角和方位角进行渲染。纹理大小被设置为st = 4。

图6. 风格转换和DeepDream中网格的初始状态。从六个角度进行渲染。
对于风格转移,我们使用的风格图像来自[3, 9]。 λc, λs, 和λt是为每个输入手动调整的。用于风格损失的特征提取器fs是来自VGG- 16网络[26]的conv1 2、conv2 3、conv3 3和conv4 3。灯光的强度为la=0.5和ld=0.5,灯光的方向在优化过程中是随机设置的。 对于Adam的{vi},{ti}的α值被设定为2.5e-4,5e-2。参数更新次数设置为 5, 000。
在DeepDream中,图像的渲染没有灯光。特征提取器是来自GoogLeNet[28]的inception 4c层。对于 {vi}、{ti},Adam 的 α 值设置为 5e-5、1e-2。优化在 1, 000 次迭代后停止。
5.2.2 2D 到 3D 风格转换
图7展示了二维到三维风格转换的结果。其他结果见补充材料。

图7.二维到三维的风格转换。最左边的图像代表风格。风格图像是《汤姆森第5号(黄色日落)》(D. Coupland,2011)、《巴别塔》(P. Bruegel the Elder,1563)、《呐喊》(E. Munch,1910)和《巴勃罗-毕加索肖像》(J. Gris,1912)。
绘画的风格被准确地转移到纹理和形状上。从兔子的轮廓和茶壶的盖子上,我们可以看到库普兰和格里斯的直线风格。蒙克的波浪形风格也被转移到了茶壶的侧面。有趣的是,巴别塔的侧面只被转移到兔子的侧面,而不是颠倒。
所提出的方法提供了一种直观和快速编辑3D模型的方法。这对产品设计以及艺术制作的快速原型打字很有用。
5.2.3 3D DeepDream
图8展示了DeepDream的结果。在兔子的脸上出现了鼻子和眼睛。茶壶的壶嘴扩大了,变成了鸟的脸,而身体则出现了类似巴士的样子。这些转换与每个物体的三维形状相匹配。

图 8. 3D 网格的 DeepDream。
6、结论
在本文中,我们通过提出一个近似梯度的渲染器,使三维网格的渲染整合到神经网络中。利用这个渲染器,我们提出了一种从单一图像重建三维网格的方法,其性能在视觉效果和体素IU度量方面优于现有基于体素的方法[36]。我们还提出了一种方法,根据三维网格的三维形状,用图像上的损失函数和梯度下降来编辑其顶点和纹理。这些应用证明了将网格渲染器集成到神经网络中的潜力以及所提出的渲染器的有效性。
我们的渲染器的应用并不限于本文所介绍的那些。其他问题将通过将我们的模块纳入其他系统而得到解决。
















 4569
4569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











