






You Only Look Once:Unified, Real-Time Object Detection
简介
提出了yolo目标检测模型,
- 将目标检测问题作为边框和相关类别概率的回归问题
- 它是端到端网络,直接从整张图像预测
- 速度非常快,基础的网络达到45FPS,更小的网络达到155FPS,但精度没有达到STOA,mAP约为63.4%
- 它的泛化能力从自然图像到艺术作品比较好。
一、创新点
- yolo 简单,使用一个网络同时预测目标边框和类别概率
- yolo快,无复杂的pipeline
- yolo在整张图像做推理,利于编码上下文信息,而不是基于sliding window 和 region proposal局部。
- yolo可以学习到泛化的表征,如从自然图像迁移到艺术图像
缺点:
- 对小目标检测效果不行,因为一个grid cell 只能预测两个框,这两个框只能一个类。当小目标聚集在一起时,检测效果就很差
- 预测的bounding box 没有提前设定好大小,形状,很难泛化到不同寻常的目标
- 主要问题还是定位不准(correct class,0.1 < IOU <0.5),因为是直接预测bbox,而不像其他是基于先前设定的anchor,预测偏移的
总结
- 精度没有达到STOA,mAP约为63.4%
- FPS:45 frames/s(基础),155 frames/s(smaller)
- 进行了5组实验
- 提出了one-stage 的目标检测算法
二、论文链接
原文链接
[1506.02640] You Only Look Once: Unified, Real-Time Object Detection (arxiv.org)
代码链接
论文投稿期刊
2016 CVPR
相关论文
三、论文评价
- 行文:
- 在introduction中,介绍了当前两个主流方法并凸显不足,再分段展现自己方法的优势,在该章节末,稍提了自己的缺点,也说明做了一些权衡。
- 与多个其他模型的Comparison,分析的可以
- 其中有精度比它高的faster rcnn,论文就比较速度
- 有个实验是将yolo与Fast R-CNN 结合(因为两者主要error类型不同),提高mAP,体现yolo可以优势互补
- 创新:one-stage 的模型训练,将所有的预测参数都继承在一个预测层上,而不用分阶段训练,从简便模型训练和推理的角度去创新
四、模型
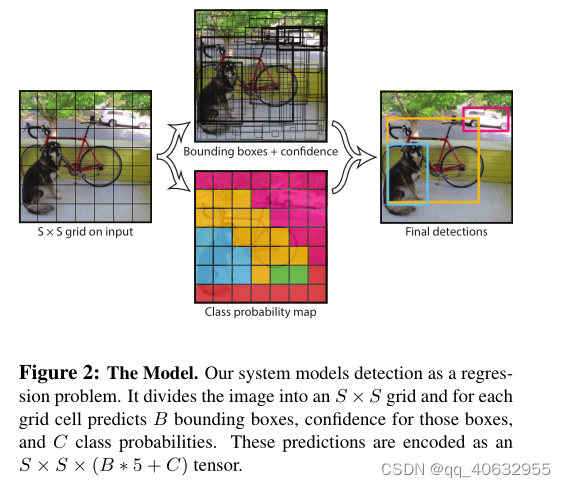
- 将图像分成S*S网格(即经过backbone,得到S×S的特征图),当一个目标的中心落在某个网格中(每个gred cell在原图上都有一个感受野),那么该网格就负责预测这个目标(在target中设置)。(论文PASCAL VOC, S=7,B = 2,C = 20)
- 全连接层的 predictions 最后输出形式(S×S×(B*5+C))
- 每个bounding box 包含x,y,w,h,和confidence,共5个
- x, y是相对于该grid cell 的坐标
- w, h是相对于整个图片的坐标
- confidence: P r ( O b j e c t ) ∗ I O U p r e d t r u t h Pr(Object)* IOU^{truth}_{pred} Pr(Object)∗IOUpredtruth
- B是bounding box的个数,C是类别概率
- 每个grid cell 一组类别概率,与bounding box的个数无关
- 这里的类别不包含背景(不同Faster RCNN),背景用 P ( O b j e c t ) P(Object) P(Object) 来区分。
- 每个grid cell 会有多个bounding box,但只会回归与gtbox的IOU最大的bounding box
- 每个bounding box 包含x,y,w,h,和confidence,共5个
- 每张图片预测49*2=98个框,(Selective Search 会产生2000个框)


- 在测试时,用 P ( C l a s s ) ∗ I O U P(Class)*IOU P(Class)∗IOU表示针对类别的自信度分数
- backbone

- 两个交叉箭头表示的是全连接层计算,7×7×30=1470, 图中的应该是经过reshape了
- 这里因为目标检测需要更细腻度的信息,因此将图像放大至2倍
model = vgg16()
model.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 1470),
)
-
激活函数:最后一层是线性激活(y=x),其他层是leaky relu
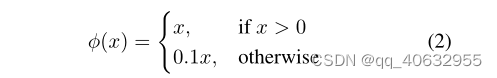
-
loss function
-

-

- 这里的损失函数全部使用的是sum-squared error,将目标检测全部作为归回问题,
- 框回归loss和类别预测loss 的weight不应该等同,有无object的grid cell 数量也不一致,应该将权重较多的分配给比较困难的框回归loss、较少的分配给no-object预测的loss
- λ c o o r d = 5 \lambda_{coord}=5 λcoord=5, λ n o o b j = 0.5 \lambda_{noobj}=0.5 λnoobj=0.5
- 大目标框预测的偏移和小目标框的,如果是同等偏移,所带来的的IOU是不一样的,对于小目标来说,效果更差一点
- 所以在预测框时使用根号,求差值。这样偏移相等时,所带来的的差值是不一样的,使得更加专注小目标的损失
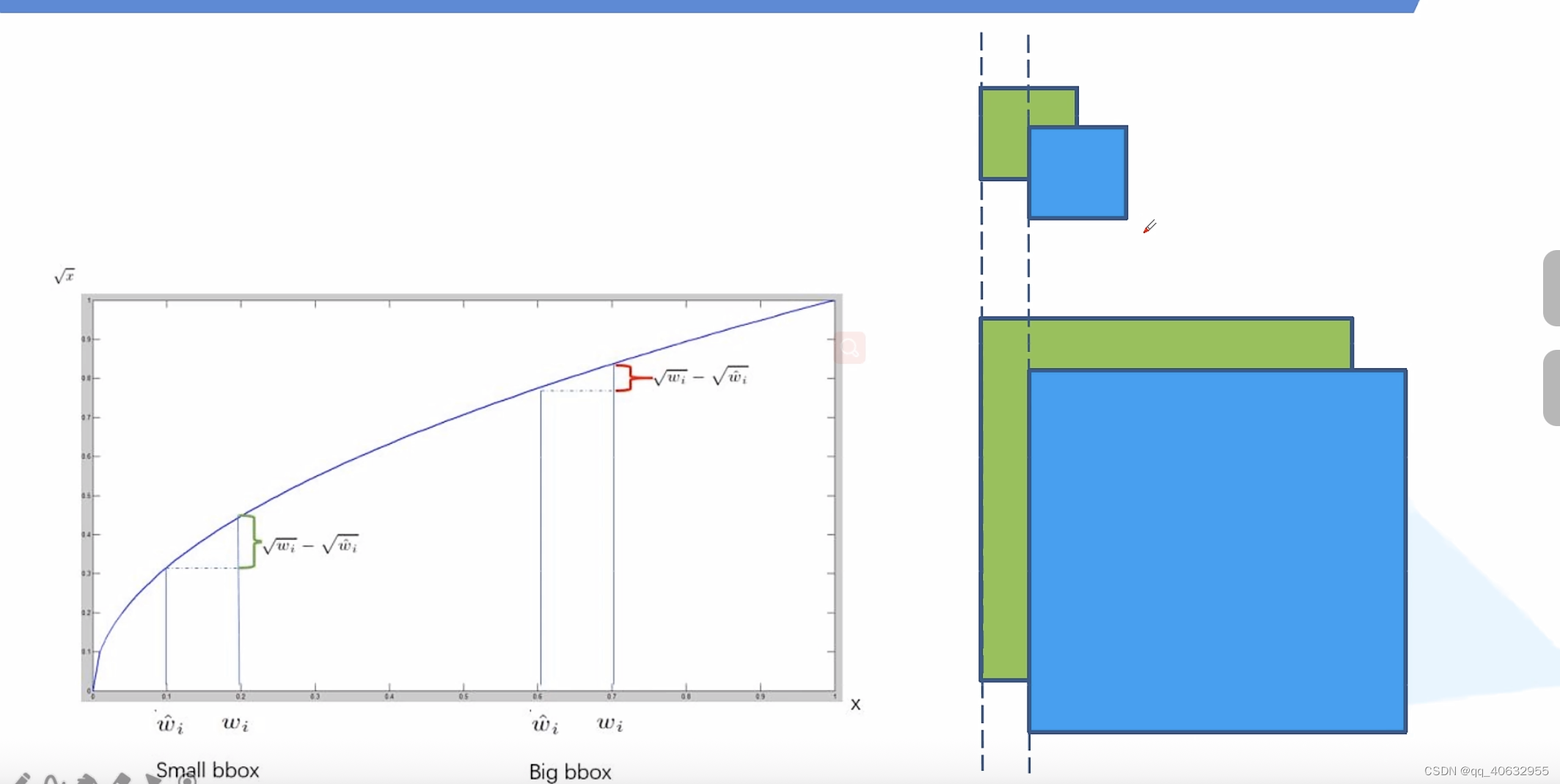
- 所以在预测框时使用根号,求差值。这样偏移相等时,所带来的的差值是不一样的,使得更加专注小目标的损失
- 在coding 时,使用的掩码将对应位置的预测取出来,进行对应位置的损失计算
五、实验
数据集
- PASCAL VOC 2007 & 2012
- Picasso and People-Art datasets
训练
- epochs:135
- batch size:64
- SGD
- momentum :0.9
- decay: 0.0005
- learning rate:
- the first epochs: 1 0 − 3 − > 1 0 − 2 10^{-3} -> 10 ^{-2} 10−3−>10−2
- 75 epochs: 1 0 − 2 10 ^{-2} 10−2
- 30 epochs: 1 0 − 3 10^{-3} 10−3
- 30 epochs: 1 0 − 4 10^{-4} 10−4
- dropout:0.5 after the first connected layer
- data augmentation
- scaling and translations 20%
- exposure and saturation in HSV
具体实验
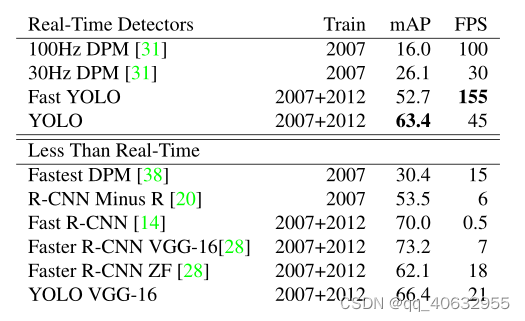
实验1(Comparison to Other Real-Time Systems)
实验2(VOC 2007 Error Analysis)

- Correct: correct class and IOU > .5
- Localization: correct class, .1 < IOU < .5
- Similar: class is similar, IOU > .1
- Other: class is wrong, IOU > .1
- Background: IOU < .1 for any object
实验3(Combining Fast R-CNN and YOLO)

实验4(AP/per class on VOC 2012)
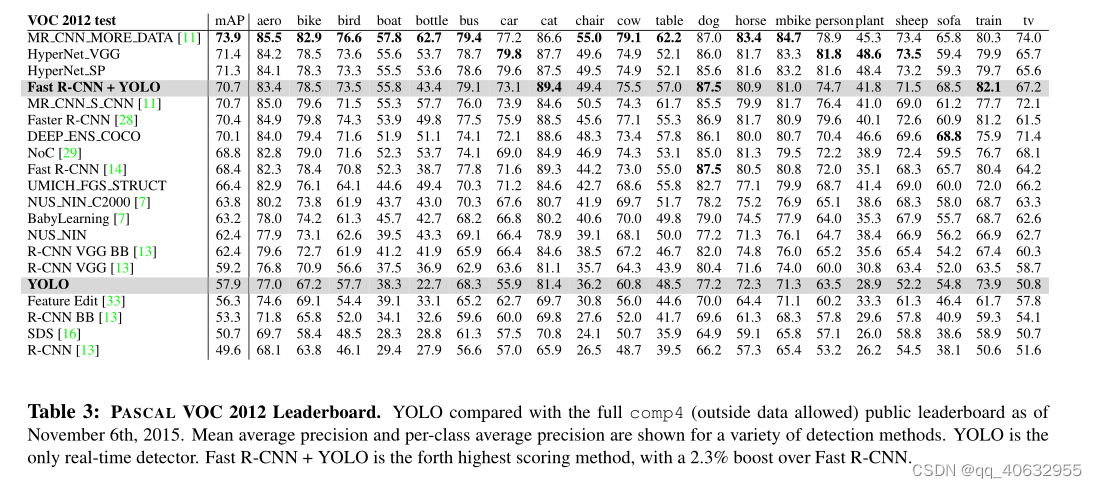
- 这是个排行榜,fast rcnn和yolo结合,精度就会上很多
实验5(Generalization results )
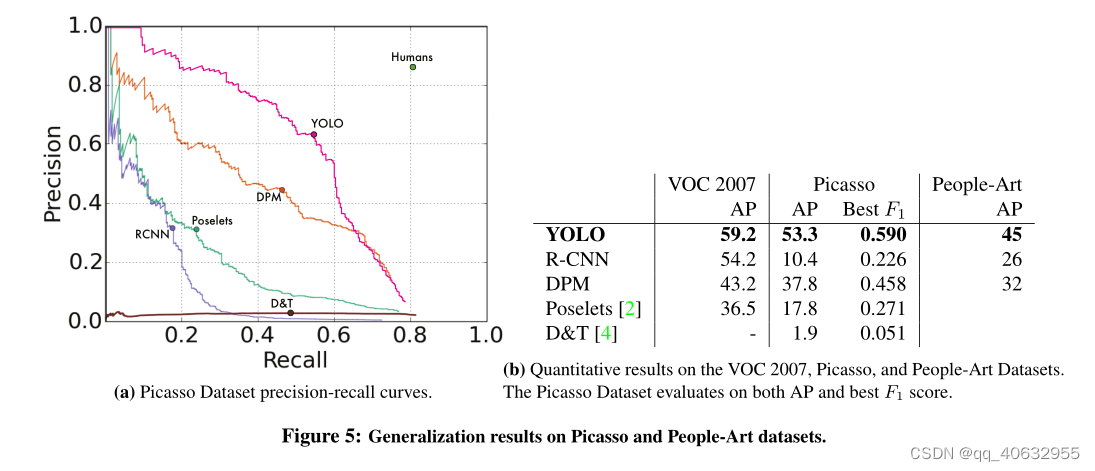















 1342
1342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









