







pandas去重和填补、删除空值
接着之前那个介绍pandas索引与选取的文章写的。如果有错误欢迎指出,谢谢。 总结的可能不全,后续会补充。
我是不想把相关函数的每个参数都介绍一遍,只介绍最基本的去重删除等操作。
一、去重:
所有的操作基于如下数表:

pandas的去重函数:pd.drop_duplicates()。
pandas.DataFrame(Series).drop_duplicates(self, subset=None, keep='first', inplace=False)
具体用法示例:
df.drop_duplicates(['C']) # 对C列去重,保留下来的是第一行的数据。
df.drop_duplicates(['C','D']) # 对C,D列去重。去重后无变化,因为CD两列相同的值并不在同一行上。
df.drop_duplicates(['C','E']) # 对C,E列去重。会删去c这一行。
df.drop_duplicates() # 无变化。因为数表中并没有两行或以上完全相同的。二、空值处理:
基于以下数表:

- 要处理空值,首要的就是要找到空值。
pandas判断是否为空值的函数(会判断数表内的每一个单元格的数字):
df.isnull()
结果为:

df.isnull().any()
结果为:

任取一列的:
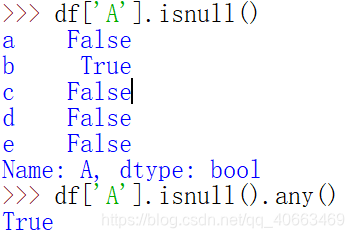
2. 找到空值之后,就要对空值进行处理:
**第一种处理方式:**利用pandas的处理空值的函数:

代码示例:
df.dropna() # 去掉所有有空值的行
df['B'].dropna() # 去掉B列里所有为空值的行**第二种处理方式:**利用pandas填充空值的函数:
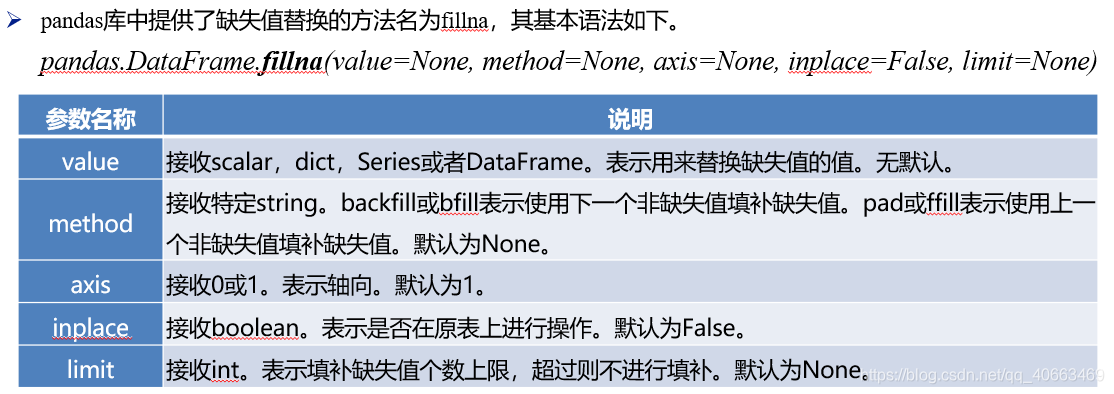
代码示例:
df.fillna(5) # 把所有的空值用5填充
df['B'].fillna(5) # 把B列里所有的空值用5填充**第三种处理方式:**利用isnull()函数和pandas的序列索引进行空值填充:。
需要注意的是这样的空值填充方式会直接改变原表。
df.loc[df['B'].isnull(),'B'] = 1234 # 把B列里所有的空值用1234填充
暂时想到的就这么多。

















 737
737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









