








目录
摘要
在本文中,作者介绍了 GPT Reddit 数据集(GRiD),这是一个由Generative Pretrained Transformer ((GPT)生成的新型文本检测数据集,旨在评估检测模型在识别 ChatGPT 生成的回复方面的性能。
该数据集由基于 Reddit 的各种上下文-提示对组成,其中既有人工生成的回复,也有 ChatGPT 生成的回复。
作者对数据集的特点进行了分析,包括语言多样性、上下文复杂性和回复质量。
为了展示该数据集的实用性,在该数据集上对几种检测方法进行了基准测试,证明了这些方法在区分人类回复和 ChatGPT 生成的回复方面的有效性。
该数据集是评估和改进 ChatGPT 检测技术的资源,有助于确保互联网上负责任和可信赖的人工智能通信。
最后,提出了 GpTen,这是一种基于张量的新型 GPT 文本检测方法,具有半监督性质,因为它只能访问人类生成的文本,其性能与全监督基线相当。
1 INTRODUCTION
GPT-3 生成的类人文本可以无缝集成到各种应用程序和平台中[1]。然而,这些生成的内容可能会被滥用于错误信息、垃圾邮件或其他恶意目的,这就提高了检测 GPT 生成文本的重要性[2]。在社交媒体、客户服务和内容生成等各种环境中,区分人类撰写的文本和人工智能生成的文本对于维护信任、安全和在线对话的完整性至关重要。检测 GPT 生成的文本有助于降低传播虚假信息的风险,确保人工智能的道德使用,并在利用人工智能语言模型的应用中提高内容质量和可靠性。
GPT 检测有很多方法[2]。可以将大多数方法分为几类:传统的监督机器学习、深度学习方法、迁移学习方法和无监督方法。
传统的监督机器学习方法已被广泛用于 GPT 检测[ 6 ]。这些方法利用标记数据集,将人类生成和机器生成的文本样本用于训练分类器。这种方法的主要优势之一是其可解释性,因为它允许检查分类器用于预测的特征。然而,传统的监督方法通常需要大量的人工标注工作来创建标注数据集,这可能会耗费大量时间和资源。此外,这些方法还需要大量的训练数据,存在过度拟合的风险,而且可能难以适应不断发展的 GPT 模型及其多样化的使用方式,因此在现代网络等动态环境中效果不佳。
深度学习方法因其从数据中自动学习复杂模式的能力而备受瞩目[6]。神经网络等这些方法可以有效捕捉 GPT 生成文本的细微特征。深度学习模型在处理非结构化数据方面表现出色,但它们往往对数据要求较高,可能需要大量的训练数据集才能获得最佳性能。这些模型因其鲁棒性和适应性而被广泛使用,尤其是在有大量标注数据的情况下。
迁移学习方法已成为一种非常实用的 GPT 检测解决方案。通过利用预训练模型并在特定任务中对其进行微调,迁移学习可以有效利用可用资源,同时继承预训练模型的知识和能力,这在训练数据有限的情况下尤为有利[7]。然而,迁移学习方法并不总能很好地推广到不同的 GPT 变体和应用中,这可能会限制其实用性。
无监督方法代表了一种不同的模式,即无需标记数据即可实现 GPT 检测。这些方法依靠各种统计和语言线索来识别机器生成的内容。无监督方法具有独立于标记数据集的优势,但与有监督或深度学习方法相比,其准确性和鲁棒性可能较差。由于其局限性,特别是在面对不断发展的 GPT 模型和复杂的对抗技术时,它们在实践中的使用并不普遍。
传统的监督机器学习和深度学习方法因其准确性和适应性而受到普遍青睐,而迁移学习方法则在数据效率和有效性之间实现了务实的平衡。无监督方法虽然不太常用,但它提供了一种无标签的替代方法,但在准确性和鲁棒性方面可能会落后,尤其是在复杂和不断变化的 GPT 环境中。作者在本文中的贡献是:
数据集:作者提出了 GPT Reddit 数据集 (GRiD),这是一个为 GPT 检测而设计和构建的数据集。作者将公开我们的数据集。
- 新方法:作者提出了 GpTen:一种基于张量的半监督式新方法,其 GPT 检测结果可与现有的全监督式方法相媲美
- 实验评估:广泛评估了最先进的现有方法在我们的数据集上的表现。
数据集和实现方法在 https: //github.com/madlab-ucr/GriD 上找到。
2 GPT Reddit 数据集描述
人类生成的数据使用 PRAW Python 库从 Reddit 收集,GPT 生成的内容则从 OpenAI API 收集。作者从三个不同的子网站获取 Reddit 数据: AskHistorians、AskScience 和 ExplainLikeImFive。
要考虑每个 Reddit 子版块的帖子,必须满足以下所有条件:
(1) 帖子日期必须在 2022 年 11 月之前。
(2)帖子必须至少有 1000 分(向上投票)。
(3) 帖子不包含成人内容。
(4) 帖子使用英语。
(5) 帖子标题格式为问题。
(6) 帖子本身不能被删除。
可以分别对每项标准进行论证。以下是每个标准的理由说明:
(1) ChatGPT 于 2022 年 11 月正式向公众发布。为了确保 GPT 在人工生成的数据中具有最小的代表性,只考虑了该日期之前的帖子。
(2)只考虑每个子reddit的热门帖子。一般来说,至少有 1000 个向上投票的帖子才适合数据集。
(3) 由于数据集是用于学术研究目的,避免了任何成人帖子。
(4) 目前该数据集仅包含英文内容。
(5) 每个帖子的标题都会作为提示信息输入 GPT,以减少噪音并提高人工生成内容与 GPT 生成内容之间的一致性。
(6) Reddit 上的一些帖子被子 Reddit 的版主删除,但其元数据仍存在于子 Reddit 上。为了公平起见,将这些帖子从数据集中过滤掉。
在当前数据集中,作者收集了每个子论坛中符合上述条件的前 500 个帖子。对于每个帖子,最多收集 基于分数(up票数)前5 条的热门评论,然后将帖子标题输入 GPT 并存储相应的回复。每条评论只需满足一个较简单的条件即可被考虑:(1)评论为英文;(2)评论未被删除。
2.2 数据集处理
无论是人工生成的数据还是 GPT 生成的数据,都需要处理到可接受的状态。由于数据来源不同,所采用的处理技术也不同。
2.2.1 Reddit 数据处理。
为了减少人为生成内容的不必要偏差,删除了 Reddit 数据中存在的、GPT 数据中不存在的任何特征。
具体来说,删除了 Reddit 数据中的链接和任何其他非文本多模态信息。链接既可以以 markdown 格式(文本)[link] 存在,也可以以一般的 URL 格式存在,因此必须对两者进行独特处理。从标记符格式的链接中提取文本,并删除链接和特殊字符。对于通用 URL,由于 GPT3.5 不会生成链接,因此只需删除它们即可。
不代表典型标点符号的特殊字符也会被删除。例如,markdown 中的粗体字符就是用 * 字符封装的。还删除了人工生成内容中的换行符,因为 GPT 生成的文本中没有换行符。人类生成的内容中还存在其他偏差,如个人轶事和细微的上下文理解,但这些偏差可以利用来辨别人类生成的内容 和 GPT 生成的内容,因为 GPT 可以尝试通过更先进的提示技术来消除这些偏差。
作者使用 better-profanity 库过滤掉了含有亵渎或其他不当内容的 Reddit 数据,因为除非特别提示,否则 GPT 通常不会使用任何亵渎或生成不当内容。better-profanity 库可以自动过滤大部分不适当的内容,但剩余的数据都经过了人工过滤。作者还过滤掉任何长度在 100 个字符以下的人工生成内容,因为这些评论很短,而且通常缺乏实质内容。
2.2.2 GPT 数据处理。
在使用 GPT 数据之前,需要对其进行一些最基本的处理。为了与 Reddit 评论的典型长度相匹配,GPT 的输出被限制为 100 个 token,以避免长度上的偏差。由于token限制可能导致句子不完整,因此 GPT 回复中的任何不完整句子都会被删除。为了确保保留底层模式,同时也避免在 GPT 数据中引入人为偏差,没有进行任何进一步处理。
3 提出的方法
GpTen 是一种新颖的异常检测方法,它利用张量分解来识别数据中的潜在模式。
具体来说,利用的是这样一个事实,即如果张量分解后与原始张量之间存在显著差异,那么将张量分解后重建的张量与原始张量进行比较,可能会发现原始张量中存在异常。
这种类型的张量表示法已成功应用于两种截然不同的语言任务:假新闻检测[3] 和幽默识别[9]。
因此,这种方法也可以直接应用于 GPT 检测,这也是合情合理的。作者提出的方法是一个管道式结构,由几个主要部分组成。根据第一步,这种方法被认为是半监督式的。
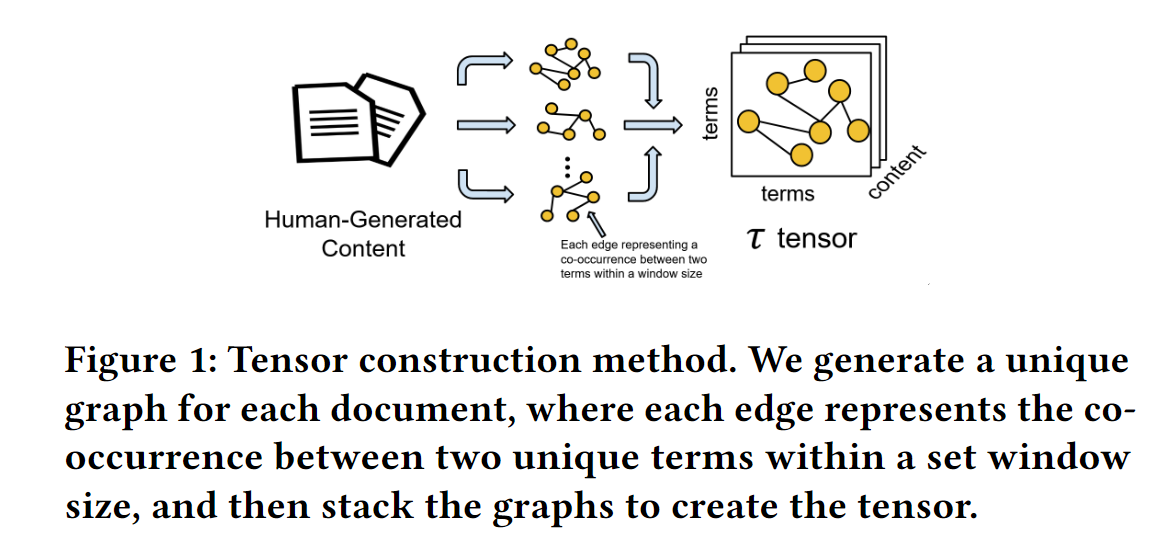
管道的第一步是构建相应输入数据的三维张量。在大多数情况下,张量应代表内分布数据。在这种情况下,任何正向数据点都将从张量中排除,因此采用了半监督方法。构建张量的方法如下:
对于数据中的每份文档,都会在一个窗口大小(通常为 5 到 10)内为每个术语及其邻近词建立一个共现矩阵。每个共现矩阵为M × M矩阵,其中 M 代表整个文档集合中唯一术语的数量。因此,给定一个包含文档的集合,将构建一个N × M × M张量,张量的每个片段都是文档的M × M共现;这样的共现矩阵有很多(图 1)。
一个重要的区别是,只使用人类生成的内容来构建张量。由于需要有token的非 GPT 数据来构建张量,因此作者认为这种方法是半监督式的。同时,只使用人工生成内容中的术语来构建共现矩阵,以避免来自测试集的任何潜在污染。
管道的第二步是分解张量。作者采用了 Canonical Polyadic Decom- position(CPD)[3] 将张量分解为因子矩阵。
管道的第三步是使用分解后的因子矩阵投影并重建张量的每个切片。具体来说,要构建一个长度向量,其中包含张量中每个切片的重建误差(图 2)。由于输入张量是三维的,CPD 分解计算出三个相应的因子矩阵 A、B 和 C,维数分别为M × r、M×r、N×r,其中 r 表示分解的秩。
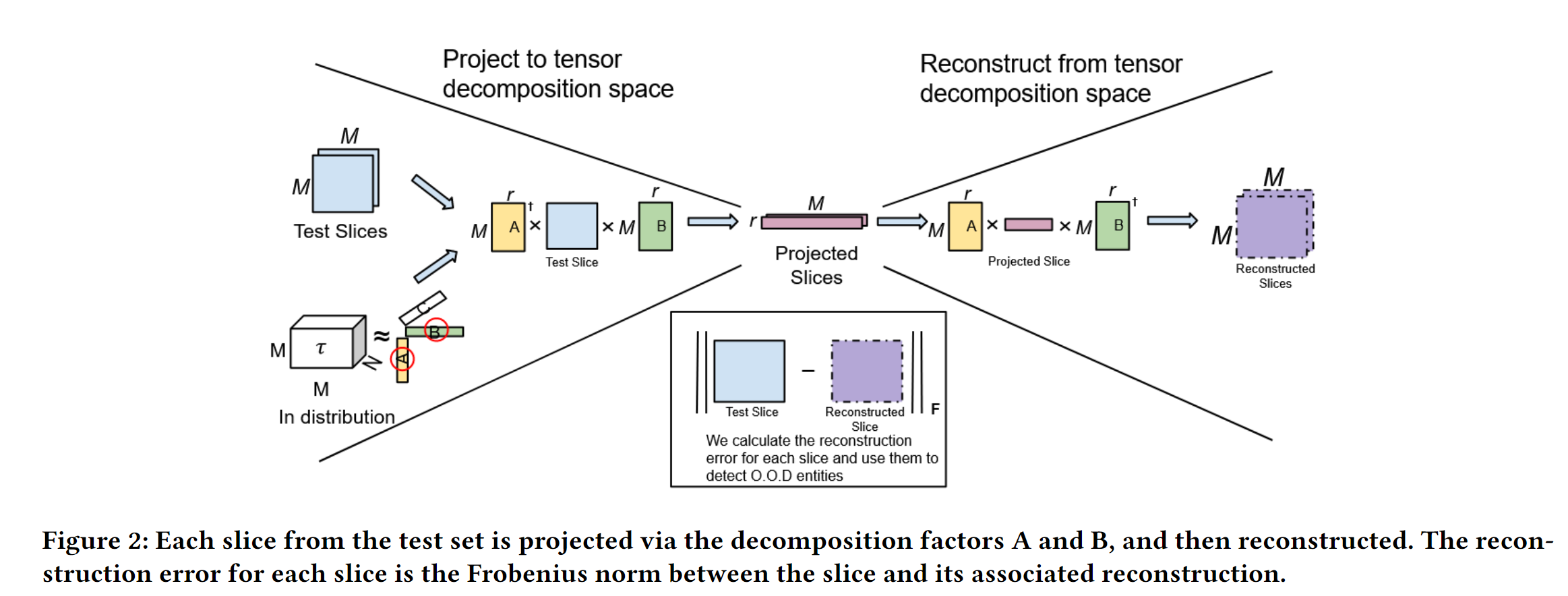
然后,将通过因子矩阵 A 和 B 对张量的每个片段(记为 )进行投影,得到投影
,即
![]() 。然后,可以计算出每个切片
。然后,可以计算出每个切片 的重建
,即
![]()
重建的维度为
,与
相同。 然后,可以利用弗罗贝尼斯准则计算每个切片
的重建误差:
![]() 。
。
重建误差遵循可以通过监督模型和无监督模型建模的分布,但是,鉴于方法只能访问负标签(即人类生成的文本),采用无监督异常检测来对重建误差分布进行建模,并且将正数(即 GPT 生成的文本)识别为 O.O.D 点.
4 EXPERIMENTAL EVALUATION
4.1 基线方法
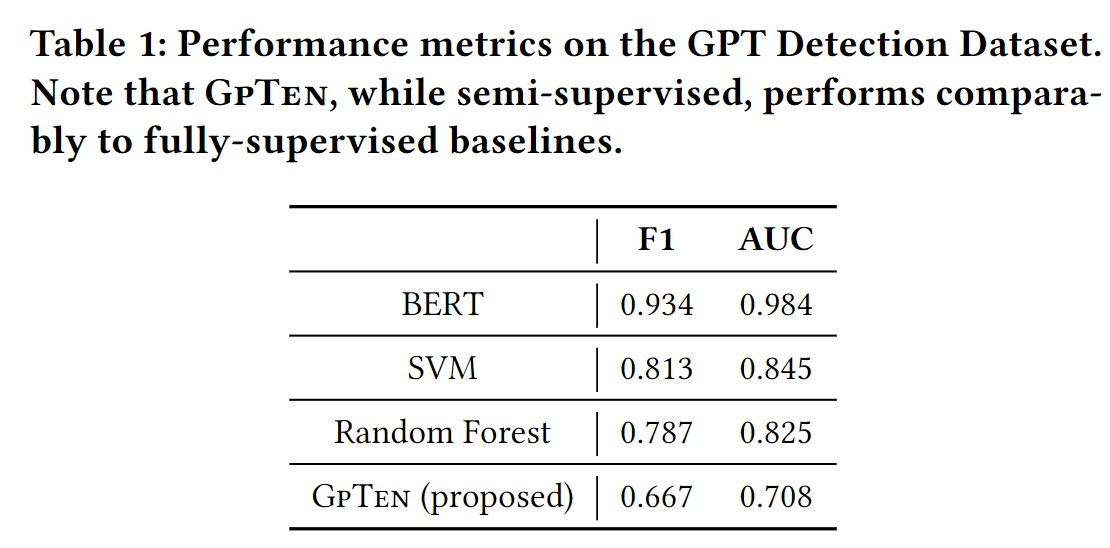
在数据集上使用三种不同的模型——随机森林、支持向量机(SVM)和 BERT 来评估它们在 GPT 生成的文本检测中的功效。选择这些模型的目的是探索一系列方法[2]。对于 SVM 和随机森林,应用了一个简单的 TF-IDF 矢量器将文本数据转换为数值数据[5],然后将其输入到两个模型中。所有结果均通过10倍交叉验证获得。
基于 BERT 的模型是自然语言处理领域最先进的模型,代表了基于深度学习的文本理解的前沿[2]。它能够将句子中的单词置于上下文中并掌握复杂的语义关系,这使其成为区分人类生成的文本和 GPT 生成的文本的任务的理想候选者。为此,选择了预训练的基线 BERT 模型进行实验。
5 CONCLUSIONS
推出了 GPT Reddit 数据集(GRiD),这是一个新颖的基准数据集,用于检测由 GPT 生成的文本,并对其进行分析。证明了完全监督方法的性能。此外,还提出了一种基于张量的方法 GpTen,这种方法只能访问人类生成的数据,其性能与完全监督基线相当。















 3367
3367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









