







BBN:用于长尾视觉识别的累积学习双边分支网络
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
1. 论文信息
| 标题 | BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition |
|---|---|
| 会议 | CVPR 2020 |
| 原文链接 | BBN: Bilateral-Branch Network With Cumulative Learning for Long-Tailed Visual Recognition (thecvf.com) |
| 代码链接 | Megvii-Nanjing/BBN: The official PyTorch implementation of paper BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition (github.com) |
| 领域 | 长尾学习 (类别平衡重新采样 Re-sampling 方向) |
| 性能 | 错误率: 33.71 33.71 33.71 (iNaturalist 2018) , 36.61 36.61 36.61 (iNaturalist 2017) |
2.问题描述
- 解决长尾分布问题的再平衡 (re-balance) 方法,虽然能显著地促进分类器的学习,但同时会破坏所学到的深度特征的表达能力 (representative ability)。
2.1 BBN网络在两个基准长尾数据集上的错误率
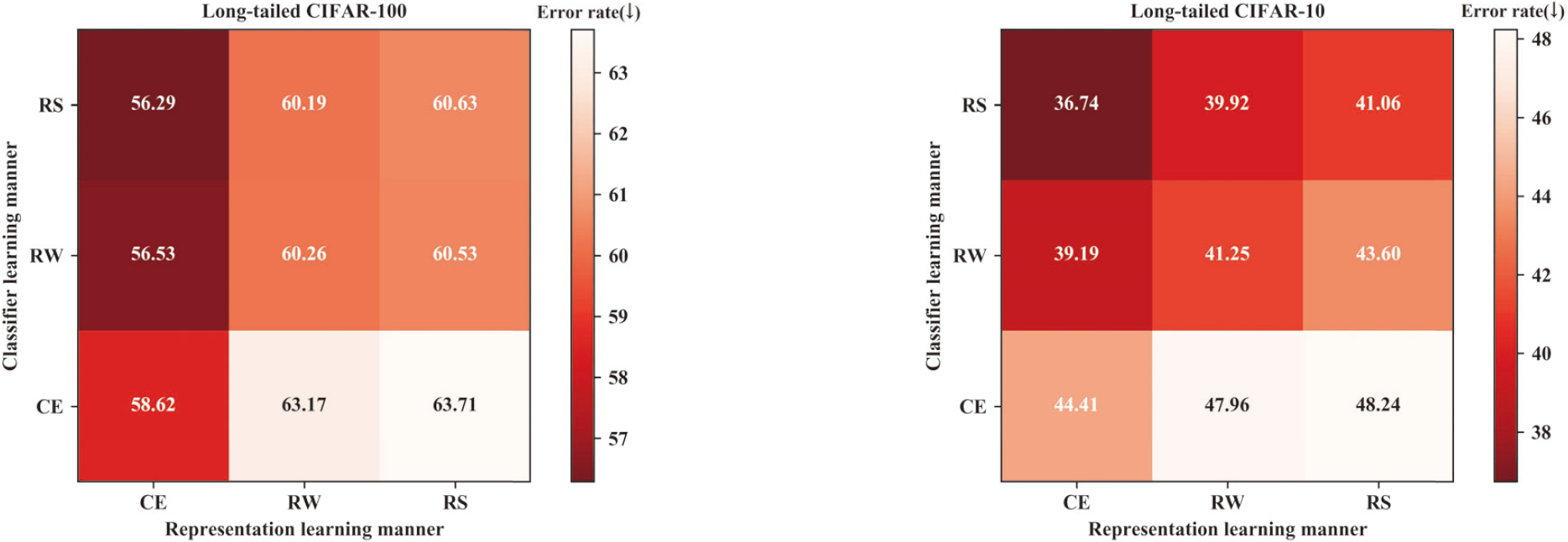
上图展示了在两个长尾数据集 CIFAR-100-IR50 和 CIFAR-10-IR50 上,三种不同学习方式的表征学习和分类器学习的最高错误率 (值越小越好)。CE (Cross-Entropy) 、RW (Re-Weighting) 和 RS (Re-Sampling) 是上述提到的三种不同的学习方法。横轴是表征学习;纵轴是分类器学习。
- 从上图中可以看到,在采用特定表征学习的情况下 (对比垂直方向的三个区块的错误率),采用 RS 和 RW 训练的分类器的错误率要明显小于采用 CE 的,这说明 RS 和 RW 确实可以改善分类器的学习。
- 而在采用特定分类器学习的情况下 (对比水平方向的三个区块的错误率),采用 CE 训练的表征的错误率竟然比用 RW 和 RS 训练的表征还要低,这说明在原始不平衡的数据集上采用普通训练,可以根据其更好的特征获得更好的结果。而 RS 和 RW 两种重新平衡方法则破坏了特征的学习,从而导致表征能力下降,错误率变高。
2.2 其他问题
- 具体地说,重新采样 (re-sampling) 既会因过度采样 (over-sampling),在尾部数据上出现过拟合的风险;也会因欠采样 (under-sampling),在整个数据集上出现欠拟合的风险。
- 而重新加权 (re-weighting) 则会通过直接改变、甚至颠倒数据出现的频率,扭曲了数据的原始分布。
3. 解决思路(创新点)
- 提出一个双边分支网络 (Bilateral-Branch Network, BBN) 。其中一个分支负责表征学习 (representation learning);另一个分支负责分类器学习 (classifier learning)。这样就能同时兼顾表征学习和分类器学习。
- 提出一个新的累积学习策略,该策略首先学习普遍模式,然后逐步关注尾部数据。
4. 技术路线
4.1 网络设计
第 1 阶段 -【表征学习】
- 分别采用直接训练 (传统的 cross-entropy )、re-weighting 和 re-sampling 三种学习方式,来获取相应的学习到的表征 (learned representations)。
第 2 阶段 -【分类器学习】
- 首先,固定第 1 阶段已经收敛的表征学习的参数 (即 back-bone 层) 。
- 然后,同样分别采用上述三种学习方式,从头开始重新训练这些网络的分类器 (即全连接层) 。
4.2 网络框架
双边分支网络 (BBN) 的模型框架如下图所示:

- BBN 模型由两个分支组成:分别是 “常规学习分支” (Conventional Learning Branch,上图蓝色框) 和 “再平衡分支” (Re-Balancing Branch,上图红色框) ,分别负责表征学习 (Representation Learning) 和分类器学习 (Classifier Learning) 。
- 【常规学习分支】配备了用于原始长尾数据分布的均匀采样器 (Uniform Sampler) ,负责学习用于识别的通用模式。
- 【再平衡分支】配备了一个反向采样器 (Reversed Sampler) ,用来对尾部数据进行建模。
- 然后,通过一个自适应权衡参数
α
\alpha
α ,将上述双边分支的预测结果聚合到累积学习部分 (Cumulative Learning,上图绿色框) 。参数
α
\alpha
α 是由 “适配器” (上图 Adaptor) 根据训练 epochs 的多少自动生成的。
- 当 Epoch 较小时 (即训练刚开始时) ,参数 α \alpha α 的值较大,意味着 BBN 模型首先更多关注【常规学习分支】的预测结果 (即先从原始长尾分布中学习通用特征) ;
- 随着 Epoch 逐渐增加,参数 α \alpha α 逐渐变小,意味着 BBN 模型逐步关注【再平衡分支】的预测结果 (即逐步关注尾部数据) 。
- 更重要的是,参数 α \alpha α 可以进一步控制每个分支的参数更新。例如,参数 α \alpha α 可以避免模型在训练后期因注重尾部数据而破坏已学习到的通用特征。
5 实验结果
5.1 实验条件
| 数据集 | Long-tailed CIFAR-10 和 CIFAR-100 | iNaturalist2017 和 iNaturalist 2018 |
|---|---|---|
| Back-bone | ResNet-32 | ResNet-50 |
| Optimizer | SGD | - |
| 初始学习率 | 0.1 0.1 0.1 | - |
| 权重衰减 | 2 × 1 0 − 4 2×10^{-4} 2×10−4 | - |
| Momentum | 0.9 0.9 0.9 | - |
| 显卡要求 | GTX1080Ti × 1 × 1 ×1 | GTX1080Ti × 4 × 4 ×4 |
| Epoch | 200 | - |
| Batch Size | 128 | 128 |
5.2 Long-tailed CIFAR的实验结果
作者对三种不同不平衡率 (imbalance ratios, β = N m a x N m i n \beta=\cfrac{N_{max}}{N_{min}} β=NminNmax) 的 Long-tailed CIFAR 数据集进行了实验,分别是 β = 10 , 50 和 100 \beta=10,50 和100 β=10,50和100 .
下表展示了各种方法的错误率 (Error Rate,越低越好) :
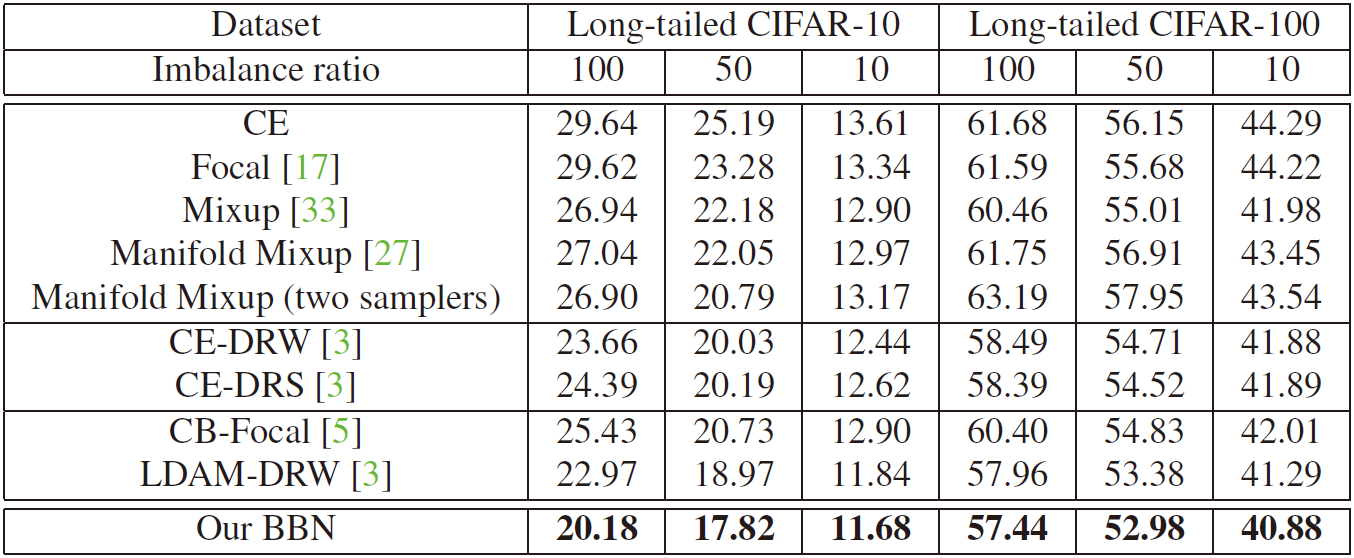
上表证明,在参与比较的所有方法中, BBN 模型在所有 Long-tailed CIFAR 数据集上都取得了最好的结果。
对比的方法包括两阶段微调策略 (即 CE-DRW 和 CE-DRS) 、一系列的 mixup 算法 (即 mixup、manifold mixup 和带有与 BBN 相同的两个采样器的 manifold mixup) 、以及先前的最先进方法 (即 CB-Focal 和 LDAM-DRW ) 。
特别是在 Imbalance ratios =100 (即极度不平衡的情况) 的 Long-tailed CIFAR-10 数据集上,BBN 得到了 20.18 20.18 20.18 的错误率,比 LDAM-DRW 还要低 2.79% 。此外,上表中还可以发现:两阶段微调策略 (即 CE-DRW 和 CE-DRS) 是有效的,因为它们与最先进的方法相比,可以获得相似甚至更好的结果。
5.3 iNaturalist的实验结果
两个大规模长尾数据集 iNaturalist 2018 和 iNaturalist 2017 的实验结果如下表所示:
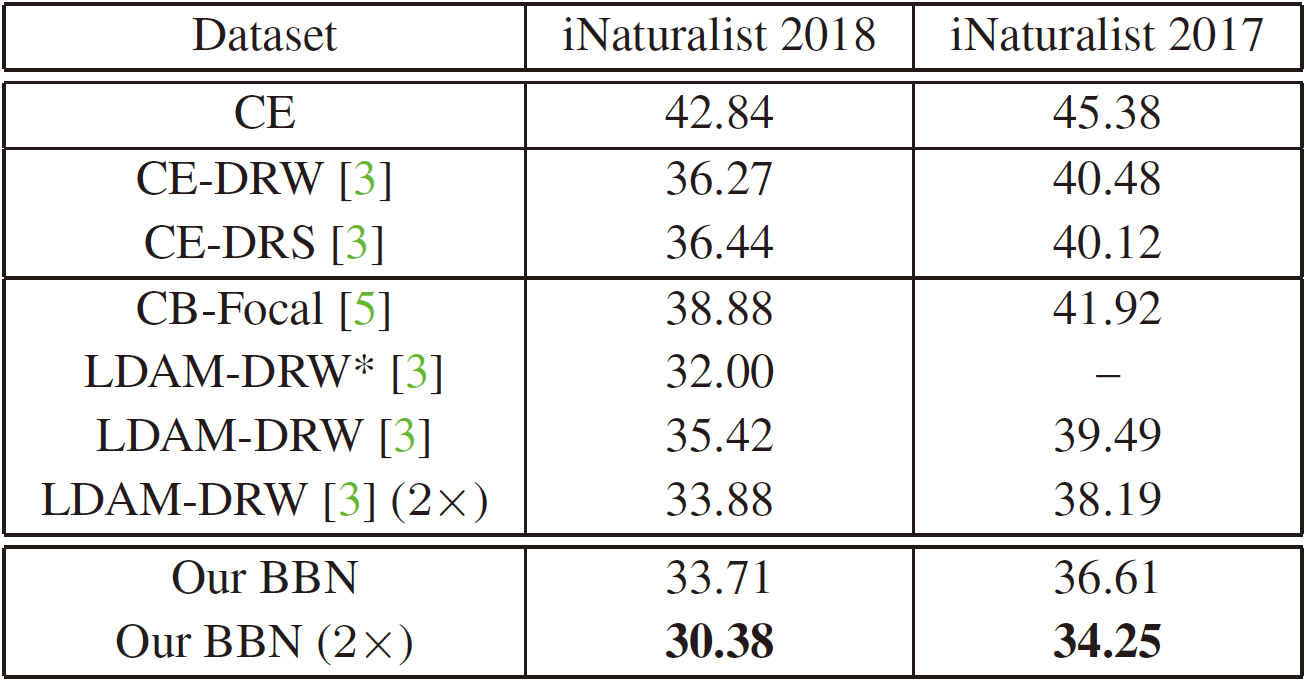
“*” 号表示 LDAM-DRW 原文中的实验结果, 不带则表示 BBN 作者自己用 LDAM-DRW 源代码跑的结果,并表示复现不出原文的实验结果。
此外,由于 iNaturalist 数据集是大规模的,作者还额外用 2 × 2× 2× scheduler 进行网络训练。同时,为了保证公平,作者还对 LDAM-DRW 使用 2 × 2× 2× scheduler 进行网络训练。结果表明:在采用 2 × 2× 2× scheduler 的情况下,BBN 比没有采用 2 × 2× 2× scheduler 的 BBN 取得了更好的结果。此外,与 LDAM-DRW ( 2 × 2× 2× ) 相比,BBN 在 iNaturalist 2018 和 iNaturalist 2017 上分别取得了 3.50 3.50 3.50% 和 3.94 3.94 3.94% 的提升。
此外,即时是不使用 2 × 2× 2× scheduler 的 BBN 仍然是取得最好的结果 (忽略 LDAM-DRW 原文中的实验结果的情况下) 。
6. 我的体会与思考
BBN 提出的这个会随着训练 Epoch 增大而不断变小的自适应权衡参数 α \alpha α 真是非常巧妙地实现了:先在训练前期采纳 【常规学习分支】的预测结果,再在训练后期采纳【再平衡分支】的预测结果。从而完美兼顾了表征学习和分类器学习。既能提高分类器在尾部数据的性能表现,又能避免再平衡方法破坏整体特征的表达能力。一箭双雕,妙哉妙哉~















 4547
4547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











