






VMamba: Visual State Space Model
VMamba:视觉状态空间模型
论文链接:http://arxiv.org/abs/2401.10166
代码链接:https://github.com/MzeroMiko/VMamba
1、摘要
借鉴了最近引入的状态空间模型SSM,提出了Visual State Space Model(VMamba),它实现了线性复杂度,同时保持了全局感受野。为解决遇到的方向敏感性问题,引入了Cross-Scan Module(CSM),它遍历空间域,将任何非因果视觉图像转换为有序的patch序列。大量的实验结果表明,VMamba不仅在各种视觉感知任务中展现出良好的能力,而且随着图像分辨率的提高,相对于现有基准,它还显示出了更明显的优势。

2、关键问题
-
注意力机制在处理图像大小时需要二次复杂度
-
由于视觉数据的非因果性,直接将这种策略应用于分块并展平的图像会导致受限的感受野,因为无法估计与未扫描区域的关系。(方向敏感性)
3、创新点
(1)提出了VMamba,一个具有全局感受野和动态权重的视觉状态空间模型,为视觉表征学习提供了新的选择,超越了现有的CNNs和ViTs。
(2)引入了Cross-Scan Module(CSM),弥合了1-D数组扫描与2-D平面遍历之间的差距,使得S6能够扩展到视觉数据,同时保持接收域的完整性。
(3)展示了VMamba在包括图像分类、对象检测和语义分割在内的各种视觉任务中表现出色,无需额外复杂性。这些结果表明VMamba有潜力成为一个稳健的视觉基础模型。
SSMs以其对动态系统的强大建模能力而闻名,它们通过将系统的状态和其演变过程结合,有效地捕捉了数据的内在结构。在视觉领域,这可能意味着捕捉图像中的空间和时间关系,或者在处理序列数据时捕捉上下文信息。
4、原理
Preliminaries
状态空间模型(State Space Models, SSMs)通常被视为线性时不变系统,它们将刺激 x ( t ) ∈ R L x(t) ∈ R^{L} x(t)∈RL映射到响应 y ( t ) ∈ R L y(t) ∈ R^{L} y(t)∈RL。数学上,这些模型通常用**线性常微分方程(ODEs)**来表示(式1),参数包括 A ∈ C N × N A ∈ C^{N \times N} A∈CN×N, B , C ∈ C N B, C ∈ C^{N} B,C∈CN(对于一个状态大小N),以及跳跃连接 D ∈ C 1 D ∈ C^{1} D∈C1。状态变化率为: h ′ ( t ) = A h ( t ) + B x ( t ) , h'(t) = Ah(t) + Bx(t), h′(t)=Ah(t)+Bx(t),输出为 y ( t ) = C h ( t ) + D x ( t ) . ( 1 ) y(t) = Ch(t) + Dx(t).\ (1) y(t)=Ch(t)+Dx(t). (1)
离散化Discretization:作为连续时间模型,状态空间模型在融入深度学习算法时面临挑战。因此,离散化过程变得至关重要。
离散化的主要目标是将ODE转化为离散函数,以使模型与输入数据中底层信号的采样率相匹配,从而实现计算效率的提升。对于输入
x
k
∈
R
L
×
D
x_{k} ∈ R^{L \times D}
xk∈RL×D,按照[17]的方法,使用零阶保持规则,ODE(式1)可以离散化为:
h
k
=
A
ˉ
h
k
−
1
+
B
ˉ
x
k
,
y
k
=
C
ˉ
h
k
+
D
ˉ
x
k
,
A
ˉ
=
e
Δ
A
,
B
ˉ
=
(
e
Δ
A
−
I
)
A
−
1
B
,
C
ˉ
=
C
.
(
2
)
h_{k} = \bar{A} h_{k-1} + \bar{B} x_{k}, y_{k} = \bar{C} h_{k} + \bar{D} x_{k}, \bar{A} = e^{\Delta A}, \bar{B} = (e^{\Delta A} - I)A^{-1}B, \bar{C} = C. \ (2)
hk=Aˉhk−1+Bˉxk,yk=Cˉhk+Dˉxk,Aˉ=eΔA,Bˉ=(eΔA−I)A−1B,Cˉ=C. (2)
其中
B
,
C
∈
R
D
×
N
B,C ∈ R^{D \times N}
B,C∈RD×N和 $\Delta ∈ R^{D}
。在实践中,文中按照
[
12
]
的方法,使用一阶泰勒级数近似
。在实践中,文中按照[12]的方法,使用一阶泰勒级数近似
。在实践中,文中按照[12]的方法,使用一阶泰勒级数近似B$:
B
=
(
e
Δ
A
−
I
)
A
−
1
B
≈
(
Δ
A
)
(
Δ
A
)
−
1
Δ
B
=
Δ
B
.
(
3
)
B = (e^{\Delta A -I})A^{-1} B ≈ (\Delta A)(\Delta A)^{-1} \Delta B = \Delta B. \ (3)
B=(eΔA−I)A−1B≈(ΔA)(ΔA)−1ΔB=ΔB. (3)
选择性扫描机制Selective Scan Mechanism:与主要关注线性时不变(LTI)状态空间模型的传统方法不同,文中提出的VMamba通过引入选择性扫描机制(S6)[12]作为核心SSM操作,实现了差异化。在S6中, B ∈ R B × L × N B ∈ R^{B \times L \times N} B∈RB×L×N, C ∈ R B × L × N C ∈ R^{B \times L \times N} C∈RB×L×N,以及 Δ ∈ R B × L × D Δ ∈ R^{B \times L \times D} Δ∈RB×L×D都来自输入数据 x ∈ R B × L × D x ∈ R^{B \times L \times D} x∈RB×L×D。这意味着S6能够利用输入中的上下文信息,确保机制内权重的动态性。
2D Selective Scan

尽管S6具有独特的特性,它以因果方式处理输入数据,因此只能捕获数据扫描部分的信息。这使得S6在涉及时间序列数据的自然语言处理任务中表现出色,但在适应非因果数据,如图像、图、集合等时,却面临重大挑战。解决这个问题的一个直接方法是沿两个不同方向(即前向和后向)扫描数据,这样它们可以互补彼此的接收场,而不会增加计算复杂度。
尽管具有非因果性,图像与文本不同,它们包含二维空间信息(如局部纹理和全局结构)。S4ND [35]建议通过将SSM与卷积相结合,并通过外积outer-product直接将1D卷积扩展到2D。然而,这种修改导致权重失去动态性(即输入独立),从而牺牲了基于上下文的数据建模能力。因此,文中选择保持动态权重,坚持选择性扫描方法[12],但这限制了我们不能像S4ND那样融入卷积操作。
为解决这个问题,文中提出Cross-Scan Module(CSM),如图2所示。选择将图像块沿行和列展开成序列(扫描扩展),然后沿四个方向(从左上到右下、从右下到左上、从右上到左下、从左下到右上)进行扫描。这样,每个像素(如图2中的中心像素)可以从不同方向的其他像素中获取信息。然后,将每个序列重塑为单个图像,所有序列合并形成一个新的图像,如图3所示(扫描合并)。S6与CSM的结合,称为S6块,是构建视觉状态空间(VSS)块的核心元素,VSS块构成了VMamba的基本构建单元(将在下一节中详细说明)。文中强调,S6块继承了选择性扫描机制的线性复杂性,同时保持了全局接收场,这符合本文构建此类视觉模型的初衷。

Overall Architecture

VMamba-Tiny的架构概述如图4(a)所示。VMamba首先通过一个类似于ViT的stem模块将输入图像分割成小块,但不进一步将这些小块展平成一维序列,这保持了图像的二维结构,生成一个具有
H
4
×
W
4
×
C
1
\frac{H}{4} \times \frac{W}{4} \times C_{1}
4H×4W×C1维度的特征图。接着,VMamba在特征图上堆叠多个VSS块,保持相同的维度,构成“Stage 1”。VMamba通过在“Stage 1”中通过patch merge操作对特征图进行下采样,构建了层次化的表示。随后,更多的VSS块被加入,输出分辨率变为
H
8
×
W
8
\frac{H}{8} \times \frac{W}{8}
8H×8W,形成了“Stage 2”。这个过程重复进行,以创建分辨率分别为
H
16
×
W
16
\frac{H}{16} \times \frac{W}{16}
16H×16W和
H
32
×
W
32
\frac{H}{32} \times \frac{W}{32}
32H×32W的“Stage 3”和“Stage 4”。所有这些阶段共同构建了类似于流行CNN模型(如[19,22,41,29,42])以及某些ViT(如[27,48,6,56])的层次化表示。这种架构在实际应用中可以作为其他视觉模型的通用替代,满足类似需求。文中设计了三个不同规模的VMamba:VMamba-Tiny(VMamba-T)、VMamba-Small(VMamba-S)和VMamba-Base(VMamba-B)。详细的架构规格见表1。所有模型的计算量(FLOPs)基于
224
×
224
224 \times 224
224×224的输入尺寸评估。作者将在未来的更新中引入更大规模的模型。

VSS Block
VSS块的结构如图4(b)所示。输入首先经过一个线性嵌入层,输出分为两个信息流。其中一个流通过一个 3 × 3 3 \times 3 3×3 DW Conv,接着由SiLU激活函数[37]处理,然后进入核心的SS2D模块。SS2D模块的输出经过层归一化处理,然后与另一个信息流经过Silu激活后的输出相加,生成VSS块的最终输出。
与视觉Transformer不同,由于VMamba的因果特性,文中避免使用位置嵌入偏置。设计结构与典型的视觉Transformer结构有所区别,通常在一个块中采用Norm(归一化)→注意力→Norm→MLP(多层感知器)的序列操作,而VMamba摒弃了这种模式。
5、实验
本节进行了一系列实验,旨在评估并比较VMamba与流行模型,如卷积神经网络(CNNs)和视觉Transformer(ViTs)。实验评估涵盖了广泛的任务,包括ImageNet-1K上的图像分类、COCO上的物体检测以及ADE20K上的语义分割。接着,深入进行分析实验,以更深入地理解VMamba的架构特性。
Image Classification on ImageNet-1K
实验设置:在ImageNet-1K [7] 上评估VMamba的图像分类性能。遵循[27]中的配置,VMamba-T/S/B 从头开始训练300个 epoch(前20个epoch用于预热),使用1024的批量大小。训练过程采用AdamW优化器,设置动量为0.9,beta为(0.9, 0.999),采用余弦衰减学习率调度器,初始学习率为 1 × 1 0 − 3 1 \times 10^{-3} 1×10−3,权重衰减为0.05。还应用了标签平滑Label Smooth(0.1)和指数移动平均(EMA)等额外技术。除此之外,没有应用其他额外的训练技术。
结果:如表2所示,VMamba的性能达到83.2%,比RegNetY-16G高出0.3%,比DeiT-B高出0.1%。这些显著的结果强调了VMamba作为强大基础模型的潜力,它超越了传统的卷积神经网络模型和视觉Transformer,展现出更广泛的优势。

Object Detection on COCO
本节通过MSCOCO 2017数据集[26]来评估VMamba在目标检测任务上的性能。训练框架基于mmdetection库[2],并且遵循Swin[27]中使用的超参数,采用Mask-RCNN检测器。具体来说,使用AdamW优化器,并对在ImageNet-1K上预训练的分类模型进行12和36个epoch的微调。VMamba-T/S/B的drop path率分别设置为0.2%、0.2%和0.2%。初始学习率设为 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4,在第9和11个epoch时减半。实验实施多尺度训练和随机翻转,每批大小为16。这些设置与目标检测评估中的常用实践相符。
COCO数据集的结果总结见表3:在
1280
×
800
1280 \times 800
1280×800尺寸输入下的对象检测和实例分割结果。
A
P
b
AP_{b}
APb 和
A
P
m
AP_{m}
APm 分别代表边界框AP和分割AP。"1×"表示模型经过12个epoch的微调,而"3×MS"表示在36个epoch内使用多尺度训练。VMamba在对象检测任务上达到了48.5% / 49.7%的mAP,在实例分割上达到了43.2% / 44.0%的mIoU,这些效果突显了VMamba在密集预测下游任务中的潜力。

Semantic Segmentation on ADE20K
设置:遵循Swin方法[28],在预训练模型的基础上构建一个UperHead[50]。实验使用AdamW优化器[30],将学习率设置为
6
×
1
0
−
5
6 \times 10^{-5}
6×10−5。整个微调过程总共进行160,000个迭代,每批大小为16。默认的输入分辨率是
512
×
512
512 \times 512
512×512,文中还提供了使用
640
×
640
640 \times 640
640×640输入和多尺度(MS)测试的实验结果。
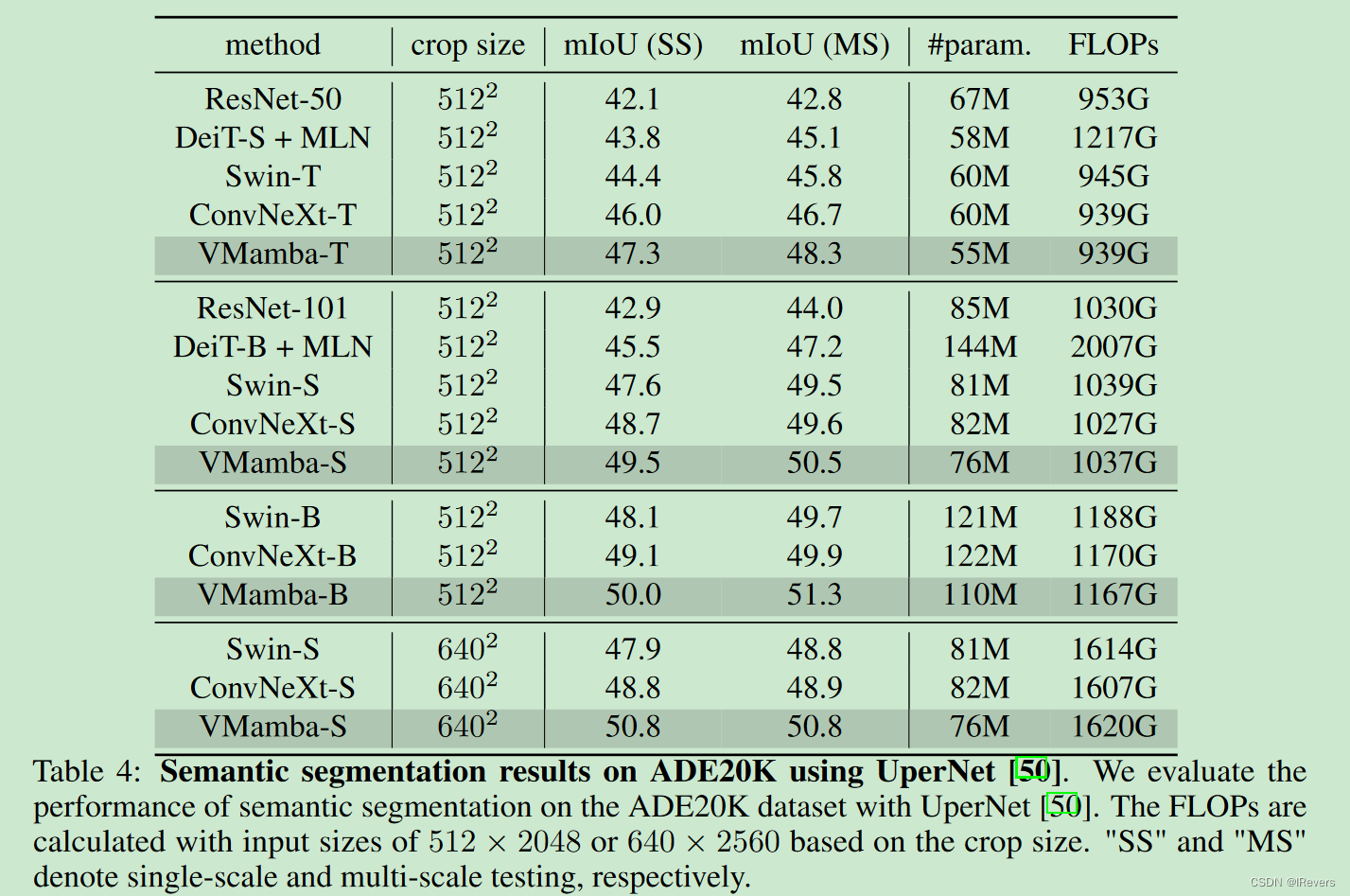
结果在表4中展示。VMamba一如既往地展现出卓越的精度,特别是VMamba-T模型在 512 × 512 512 \times 512 512×512分辨率下达到了47.3%的mIoU,使用多尺度(MS)输入时提升至48.3%。这些成绩超越了所有竞争对手,包括ResNet[19]、DeiT[45]、Swin[28]和ConvNeXt[29]。值得注意的是,即使在 640 × 640 640 \times 640 640×640分辨率的输入下,VMamba-S/B模型的优势依然明显。表4:在ADE20K上使用UperNet[50]进行语义分割的结果。实验评估了在ADE20K数据集上使用UperNet[50]进行语义分割的性能。计算FLOPs时,依据裁剪大小,使用 512 × 2048 512 \times 2048 512×2048或 640 × 2560 640 \times 2560 640×2560的输入尺寸。"SS"和"MS"分别代表单尺度和多尺度测试。
Analysis Experiments


有效感受野分析为了评估不同模型的有效感受野(ERFs)[32],实验在输入尺度上进行了比较分析,如图6所示。首先,实验研究了在不同图像分辨率(从 64 × 64 64 \times 64 64×64到 1024 × 1024 1024 \times 1024 1024×1024)下,使用 224 × 224 224 \times 224 224×224输入大小训练的流行模型的推理性能,如图6(a)所示。VMamba在整个输入图像尺寸变化中表现出最稳定的性能。值得注意的是,当输入尺寸从 224 × 224 224 \times 224 224×224增大到 384 × 384 384 \times 384 384×384时,只有VMamba系列(VMamba-S达到84%)显示出性能提升的趋势,这突显了其对输入图像尺寸变化的鲁棒性。在图6(b)中,实验评估了不同分辨率(同样从64×64到1024×1024)下的计算量。正如预期的那样,VMamba系列的复杂度呈现线性增长,与卷积神经网络模型相符。VMamba的复杂度与精心设计的视觉Transformer,如Swin[28]保持一致。然而,值得注意的是,只有VMamba实现了全局有效感受野(ERF)。尽管DeiT也具有全局ERF能力,但其复杂度却呈平方增长。
6、总结
文中提出了Visual State Space Model (VMamba),一种融合了卷积神经网络(CNNs)的局部感受野优势和视觉Transformer(ViTs)的全局视野和动态权重的新型视觉表示学习架构。VMamba通过引入视觉状态空间模型的概念,实现了线性复杂度,从而在保持高效的同时,实现了对视觉信息的高效处理。文中设计的**Cross-Scan Module (CSM)**有效地解决了方向敏感性问题,使得模型能够处理有序的图像区域序列,从而提高了模型的性能。VMamba为视觉领域的模型设计提供了一个新的视角,它在保持计算效率的同时,实现了对视觉信息的深度理解和高效处理。VMamba的提出将为视觉计算领域带来新的突破。



















 2300
2300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











