






一、引言
在神经科学研究中,研究者经常需要分析大量的脑电(EEG)、功能性近红外光谱(fNIRS)或功能性磁共振成像(fMRI)数据。例如,在一项研究中,研究者试图比较不同实验条件下若干脑区的活跃程度。通过统计分析,他们需要检验多个脑区之间是否存在显著差异。然而,随着检验次数的增加,出现假阳性结果的概率也显著提高。这种现象被称为“多重比较问题(multiple comparison problem)”。如果不加以处理,研究者可能会因随机波动误判结果的显著性,从而得出错误的科学结论。
随着数据分析技术的进步,研究者可以获取并处理越来越大规模的数据集。数据扩增使得统计检验的数量大幅增加,同时,问题的复杂化和多样化也带来了更复杂的分析需求。在这种情况下,多重比较校正成为科学研究中不可或缺的步骤。无论是在医学、生物学还是社会科学中,多重比较校正的应用频率在学术论文中迅速上升。
然而,多重比较校正并非“一刀切”的工具,不同的研究场景和分析目的对校正方法有着不同的要求。在错误率控制与检验灵敏度之间找到平衡是一个需要谨慎考量的过程。因此,明确什么情况下需要使用多重比较校正以及如何正确选择合适的方法,是研究者提升分析可靠性和结果解释力的重要一步。
本篇博客将以通俗易懂的方式,结合具体案例,深入探讨多重比较校正的核心问题、常用方法及其适用情境,希望能为广大研究者提供清晰的指导。
二、多重比较问题
2.1 多重比较问题是什么?
多重比较问题(Multiple Comparison Problem)指的是在同时进行多次统计检验时,随着检验次数的增加,出现假阳性(Type I Error)的概率也会显著提高。具体来说,在单次检验中,假设我们将显著性水平(α)设置为0.05,那么我们有5%的概率错误地拒绝原假设。然而,当进行多次独立检验时,假阳性率会随着检验次数的增多累积,从而导致更多不准确的结果。
例如,在神经科学研究中,研究者可能会分析多个脑区的激活水平,或者比较多个实验条件下的时间序列数据。如果在每个比较中都单独使用显著性水平0.05进行检验,不进行任何校正,那么整体的假阳性率将远高于5%,这可能会导致研究者误认为某些无意义的结果具有统计显著性。
2.2 为什么会出现多重比较问题?
多重比较问题的核心在于检验的次数。假阳性率随着检验次数的增加呈指数增长。例如,在 n 次独立检验中,至少出现一次假阳性的概率可以用以下公式表示:
当 n 较大时,这个概率会迅速接近 1。以下是一个简单的示例来说明这个问题:假设我们比较某个脑区与其他 20 个脑区的激活水平,假设原假设成立且检验之间独立,则至少出现一次假阳性的概率为:
这意味着,我们有 64% 的概率在分析中得出至少一个假阳性结果,远高于单次检验的 5%。
2.3 Python 示例:多重比较问题案例
我们通过模拟一个案例来说明 多重比较问题 的出现,以及如何通过校正方法(如 Bonferroni 和 FDR)来控制假阳性率。
2.3.1 假设
- 数据背景:假设有 20 个脑区,每个脑区生成 300 个数据点,所有数据点均来自标准正态分布(均值为 0,标准差为 1)。
- 原假设:每个脑区的数据均值为 0(即数据来自同一分布,无显著差异)。
- 显著性水平:设定显著性水平 α=0.05。
2.3.2 预期结果
-
在无多重比较校正的情况下:
- 即使原假设成立,仍然可能在 20 次 t 检验中出现若干假阳性(p 值小于 0.05)。
- 假阳性的概率随着检验次数增加而累积。
-
在校正后的情况下:
- Bonferroni 和FDR 校正后,假阳性不再出现
2.3.3 运行结果
代码运行结果如下:可以发现Region_4出现了假阳性,在多重比较校正后,假阳性消失。
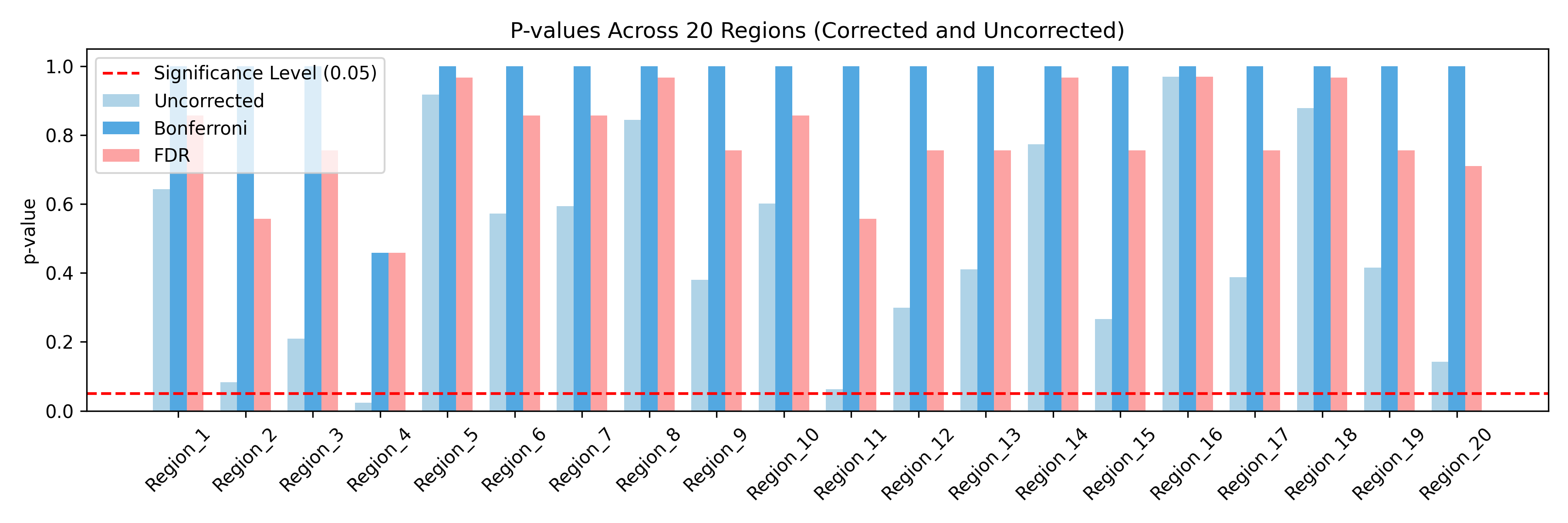
我们进一步验证出现假阳性的情况,与检验次数的关系,发现:
- 随着检验次数(脑区数)增加,未校正的假阳性结果数会显著上升。
- 校正后,假阳性结果数量大幅减少

2.3.4 结果解释
运行上述代码后,我们会发现部分脑区的 p 值低于 0.05(显著性水平),尽管数据完全是随机生成的,且理论上不应该出现显著性差异。这说明多重比较问题确实存在,即便在没有任何真实效应的情况下,也可能因为多次检验而得出显著结果,且假阳性出现次数随检验次数增加而累积。
为了解决这一问题,多重比较校正方法(如 Bonferroni 校正、FDR 校正等)被广泛应用。在接下来的章节中,我们将讨论典型使用多重比较校正的场景以及适用方法。
Python源代码
demo1:
import os.path
import numpy as np
import scipy.stats as stats
import statsmodels.stats.multitest as smm
import pandas as pd
import matplotlib.pyplot as plt
# 设置随机种子,生成模拟数据
np.random.seed(52)
# 模拟数据:20 个脑区,每个脑区生成 300 个数据点
n_regions = 20
n_samples = 300
data = np.random.normal(0, 1, (n_regions, n_samples))
# 对每个脑区进行单样本 t 检验(检验均值是否为 0)
p_values = []
for i in range(n_regions):
_, p = stats.ttest_1samp(data[i], 0)
p_values.append(p)
# 转换为 DataFrame
df = pd.DataFrame({
"Region": [f"Region_{i+1}" for i in range(n_regions)],
"p_value": p_values
})
# 打印未校正的 p 值
print("P-values from t-tests:")
print(df)
# 计算 Bonferroni 校正后的 p 值
bonferroni_corrected_p = np.minimum(np.array(p_values) * n_regions, 1.0)
# 计算 FDR 校正后的 p 值
_, fdr_corrected_p, _, _ = smm.multipletests(p_values, alpha=0.05, method='fdr_bh')
# 添加校正结果到 DataFrame
df["Bonferroni Corrected"] = bonferroni_corrected_p
df["FDR Corrected"] = fdr_corrected_p
# 打印校正后的结果
print("Corrected P-values:")
print(df)
# 可视化校正后的结果
plt.figure(figsize=(12, 4))
width = 0.25
x = np.arange(len(df))
# 绘制原始、Bonferroni 和 FDR 校正后的 p 值
plt.bar(x - width, df["p_value"], width, label="Uncorrected", color="#afd3e7")
plt.bar(x, df["Bonferroni Corrected"], width, label="Bonferroni", color="#53a8e1")
plt.bar(x + width, df["FDR Corrected"], width, label="FDR", color="#fca3a3")
plt.axhline(y=0.05, color="red", linestyle="--", label="Significance Level (0.05)")
plt.xticks(x, df["Region"], rotation=45)
plt.ylabel("p-value")
plt.title("P-values Across 20 Regions (Corrected and Uncorrected)")
plt.legend()
plt.tight_layout()
folder = ''
plt.savefig(os.path.join(folder, '案例图.png'), dpi=300)
plt.show()
demo2:
import os
import numpy as np
import scipy.stats as stats
import statsmodels.stats.multitest as smm
import pandas as pd
import matplotlib.pyplot as plt
# 设置随机种子
np.random.seed(52)
# 参数设置
n_samples = 300
n_regions_list = [20, 50, 100, 150, 200, 250] # 不同脑区数(即检验次数)
alpha = 0.05 # 显著性水平
# 保存假阳性结果统计
results = []
for n_regions in n_regions_list:
# 模拟数据
data = np.random.normal(0, 1, (n_regions, n_samples))
# 进行单样本 t 检验
p_values = []
for i in range(n_regions):
_, p = stats.ttest_1samp(data[i], 0)
p_values.append(p)
# 计算校正后的 p 值
bonferroni_corrected_p = np.minimum(np.array(p_values) * n_regions, 1.0)
_, fdr_corrected_p, _, _ = smm.multipletests(p_values, alpha=alpha, method='fdr_bh')
# 统计显著结果
uncorrected_significant = sum(np.array(p_values) < alpha)
bonferroni_significant = sum(bonferroni_corrected_p < alpha)
fdr_significant = sum(fdr_corrected_p < alpha)
# 保存统计结果
results.append({
"n_regions": n_regions,
"Uncorrected": uncorrected_significant,
"Bonferroni": bonferroni_significant,
"FDR": fdr_significant,
})
# 转换为 DataFrame
results_df = pd.DataFrame(results)
# 打印结果
print("Significant results summary:")
print(results_df)
# 绘制假阳性数量与检验次数的关系
plt.figure(figsize=(10, 6))
plt.plot(results_df["n_regions"], results_df["Uncorrected"], label="Uncorrected", marker="o", color="#afd3e7")
plt.plot(results_df["n_regions"], results_df["Bonferroni"], label="Bonferroni", marker="o", color="#53a8e1")
plt.plot(results_df["n_regions"], results_df["FDR"], label="FDR", marker="x", color="#fca3a3")
plt.axhline(y=0, color="gray", linestyle="--", linewidth=0.8)
plt.xlabel("Number of Tests (Regions)")
plt.ylabel("Number of Significant Results")
plt.title("False Positives vs. Number of Tests")
plt.legend()
plt.grid(alpha=0.6)
# 保存图像
folder = ''
plt.savefig(os.path.join(folder, '假阳性与检验次数.png'), dpi=300)
plt.show()
3. 适用多重比较校正的情况
多重比较校正是为了避免因多次检验导致的假阳性率(Type I 错误)升高。当我们在数据分析中涉及多次显著性检验时,错误地将随机结果误判为显著差异的概率会大幅增加。这里列举了几种神经科学研究中常见适用于多重比较校正的情况。
3.1 重复检验问题
最经典的是重复检验问题,如同之前章节提到的案例一样,由于多次检验导致假阳性率上升。在神经科学研究中,最典型的是:
- 寻找特异性ROI:寻找某个特征在不同疾病或生理状态之间,有显著差异的脑区或通道,比如寻找抑郁症与健康被试的脑网络某个参数有显著差异的脑区。
- 寻找有效特征:寻找在特定脑区或通道在不同生理状态之间,有显著差异的特征
如果涉及的组别较少,且比较次数不多,可以采用Bonferroni方法进行校正。
3.2 高维数据分析
高维数据在全脑功能磁共振成像或全基因组关联研究十分常见,通常涉及数千甚至数百万个变量的统计检验。比如:
例1:对10种疾病的1000个体素的100个特征进行显著性检验,选择与健康被试有显著差异的体素的特征
例2:对10种疾病的1000个体素的100个特征进行显著性检验,寻找疾病之间有显著差异的体素的特征
对于例1,总检验次数=(疾病数量)×(体素数量)×(特征数量),即需要进行1,000,000 次显著性检验;对于例2,总检验次数=(成对比较数)×(体素数量)×(特征数量),其中成对比较数=N(N−1)/2,即需要进行45×1000×100=4,500,000次检验。
此时使用Bonferroni 校正会使显著性水平过于严苛,使用FDR是更好的选择。
3.3 Post-hoc 检验(事后成对比较)
进行 ANOVA 后,如果得出结果显示有显著差异,我们并不能知道哪些具体的组之间存在差异。此时需要通过事后检验来比较每一对组之间的差异。
3.4 纵向研究或重复实验
在某些实验设计中,可能对同一对象或个体进行多次测量。常见的如 跨时间的纵向研究 或 多次对同一组样本的测量,这类设计需要在每个时间点或每个测量中进行多次检验。比如连续10天采集同一个被试的运动想象脑电数据,分析左右手是否具有显著差异。
3.5 机器学习中的模型评估
在对多个模型进行比较时,我们通常会比较它们在相同数据集上的 平均准确率。这种方法简单直观,能够反映模型的总体表现。然而,平均准确率本身并不能很好地衡量模型之间的显著差异。
为什么仅使用平均准确率有局限性:
- 缺乏显著性分析:即使两个模型在平均准确率上看似表现相似,也不能直接得出它们的表现差异是否统计显著。如果没有进行显著性检验,可能会高估或低估某个模型的表现。
- 未考虑模型间的方差:平均准确率只关注每个模型的表现的中心趋势,忽视了模型的稳定性和方差。如果两个模型的准确率差距微小,但一个模型的表现非常稳定,另一个模型的表现波动较大,单纯依赖平均准确率可能会导致误导。
因此,在多个模型比较时,除了计算平均准确率外,进行显著性检验是更为科学的方法。显著性检验可以确保模型的比较结果具有统计意义。显著性检验能够反映模型的稳定性,避免因为偶然因素导致的误判。例如,如果一个模型在多个交叉验证的折叠中波动较大,另一个模型在大多数情况下稳定地表现较好,显著性检验能帮助我们识别这种差异。
总结
在神经科学和其他领域的研究中,面对大量的统计检验时,多重比较问题是不可忽视的挑战。随着研究涉及的变量数量和检验次数的增加,错误的统计结论,特别是假阳性结果的概率也会显著上升。为了避免这种问题,多重比较校正方法成为确保研究结果可靠性的关键。
本文探讨了多重比较问题的背景和机制,特别是在神经科学研究中的应用,介绍了如何通过 Bonferroni 校正 和 FDR 校正 等方法控制假阳性率,并通过具体的代码案例展示了不同校正方法的效果。此外,针对不同的研究场景,我们还讨论了在以下情境下使用多重比较校正的重要性:
- 重复检验问题:在多个脑区或特征之间进行比较时,多重检验容易导致假阳性,因此需要校正。
- 高维数据分析:当面临大量的变量和检验时,Bonferroni 校正可能过于保守,FDR 校正则提供了一个更灵活且有效的选择。
- Post-hoc 检验:在进行ANOVA分析后,事后比较帮助确定哪些组之间存在显著差异。
- 纵向研究或重复实验:对于同一对象进行多次测量时,避免多重比较问题是确保结果准确性的必要步骤。
- 机器学习中的模型评估:在比较不同模型的表现时,显著性检验可以帮助验证某个模型是否在统计上优于其他模型,避免仅依赖平均准确率的误导。
希望本文能为研究者们提供关于多重比较校正的基础知识和实践指南,帮助大家在复杂的数据分析过程中作出更加科学和可靠的决策。

















 8008
8008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









