







一、引言
在神经科学研究中,科学家们常常需要比较两组实验结果,比如两组动物在不同刺激条件下的神经反应数据。设想一个典型的实验:研究者测量了小鼠在不同光照条件下的脑电活动,试图找出两组条件下大脑中某个区域的激活水平是否存在显著差异。经过统计分析,t 检验结果显示 p 值小于 0.05,意味着两组数据之间存在显著差异。乍一看,这似乎表明不同光照条件对小鼠的神经反应有显著影响。然而,当研究者进一步尝试通过机器学习算法来区分这两组实验数据时,却发现分类模型的准确率并不理想。这一现象让人疑惑:既然统计上已经证明两组数据存在显著性差异,为什么分类模型无法有效地将它们区分开?这样的案例并不罕见,尤其在复杂的生物数据和高维特征集的背景下更为常见。这引出了我们今天要讨论的核心问题——统计显著性是否意味着分类准确率一定很高?在数据分析和建模过程中,显著性检验能否真正转化为分类模型的高效表现?我们将在接下来的探讨中逐步揭开这个谜团。
在神经科学研究中,当我们发现两组实验条件下的数据表现出差异时,最常用的统计方法就是 t 检验和方差分析,这些工具可以帮助我们判断这种差异是否具有统计显著性。以刚才的光照实验为例,研究者希望确定在不同的光照条件下,小鼠大脑某个区域的平均激活水平是否不同。此时,t 检验作为一种经典的假设检验方法,能够帮助我们回答这个问题。t 检验的基本原理是通过比较两组数据的均值差异,并结合它们的方差和样本量,计算出一个 t 值,再根据这个 t 值和自由度查找相应的 p 值。如果 p 值小于设定的显著性水平(通常为 0.05),我们就可以认为这两组数据的均值差异是显著的,而不是随机产生的。类似的,方差分析(ANOVA)则用于比较多组数据,检验它们的均值是否存在系统性差异。这个方法通过计算组间方差和组内方差的比值来判断差异的显著性。比如,如果我们在多个不同光照条件下测试了小鼠的神经活动,方差分析就可以帮助我们判断这些条件是否对神经反应产生了显著影响。然而,这些统计方法虽然能够有效识别组间差异,却无法直接告诉我们这些差异是否足以用于分类。显著性差异只说明在平均水平上存在差异,但它并不反映数据点在特征空间中的分布情况,尤其是当数据存在高度重叠时,分类模型可能无法轻易分辨两组数据。因此,t 检验和方差分析尽管能为研究提供重要的初步结论,但它们并不能保证在分类任务中同样取得理想的效果。为了更清楚地说明这个问题,我们首先展示关于t检验和方差分析的基本原理和具体计算步骤,之后再使用python代码构建数据案例,说明导致统计和分类准确率不一致的数据特征。
二、常用统计方法的基本原理、计算流程及局限性
2.1 t检验
2.1.1 t检验的基本原理及计算流程
t 检验用于比较两组样本均值是否存在显著差异,其背后的假设是:如果两组数据来自相同的总体,则它们的均值差异应该主要是随机误差引起的。通过比较两组数据的均值、方差以及样本数量,t 检验可以计算出一个 t 值,该值表示均值差异的大小与组内变异性的相对比。具体计算公式如下:
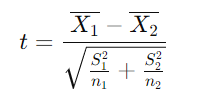

通过自由度和 t 分布表,我们可以计算出对应的 p 值。当 p 值小于设定的显著性水平(通常为 0.05),我们可以拒绝原假设,认为两组均值之间存在显著差异。
2.1.2 t检验局限性
t 检验的目标是评估均值差异的显著性,而不是评估数据点之间的可分离性。这意味着 t 检验在面对具有高度重叠的分布时,可能会显示出显著性差异,但这并不意味着分类算法可以轻松地区分这些数据。举个例子,两组数据可能在均值上有所不同,然而它们的分布高度重叠,这会导致分类模型难以找到有效的决策边界。因此,即使 t 检验显示 p 值较小,分类准确率却可能并不高。相反,一些数据组在统计上可能没有显著
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4764
4764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









