







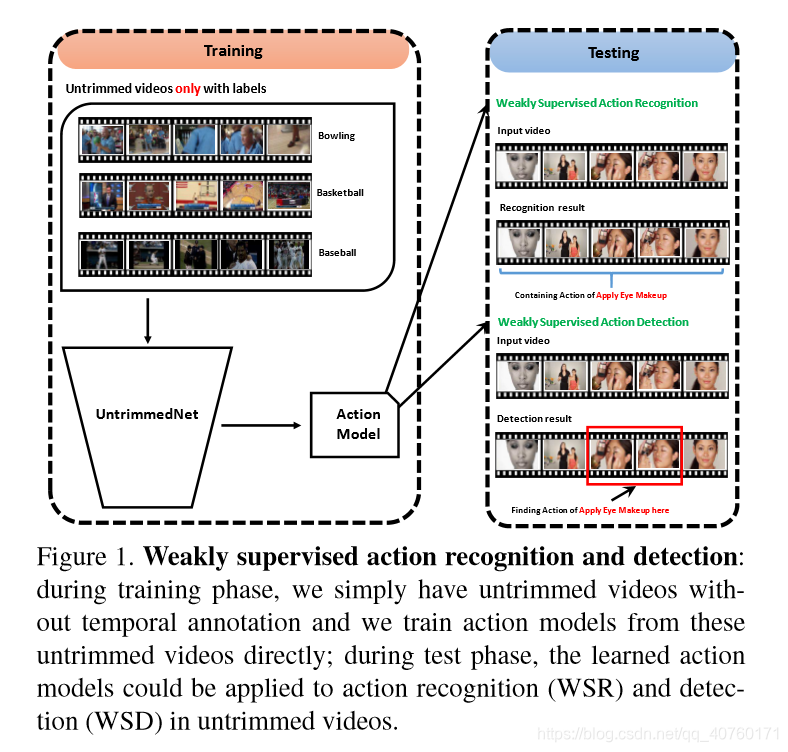
UntrimmedNets for Weakly Supervised Action Recognition and Detection
作者贡献
问题:
- 为每个行为实例标注时间持续时间花费高且耗时。
- 这些时间的注释可能是主观的,在不同人之间不一致。
目标:从未裁剪的视频中学习模型,以应用到新的视频中以进行行为识别或检测。(将此问题称为 weakly supervised action recognition (WSR) and detection (WSD))
困难:
- 从每个行为类中学习视觉模式
- 自动推断可能的行为实例的时间位置
解决:提出了一个新的端到端的体系结构:UntrimmedNet(将未修剪的视频作为输入,利用视频级标签学习网络权重)
UntrimmedNet主要由两部分组成:分类模块和选择模块。他们分别处理学习行为模型的问题和检测行为实例。
从未修剪的视频中学习
剪辑采样
对于给定的T帧时长的未修剪的视频,生成一个clip proposal集合
C
=
{
c
i
}
i
=
1
N
C = {\{c_i\}}^N_{i=1}
C={ci}i=1N,其中N是给定的建议数,
c
i
=
(
b
i
,
e
i
)
c_i = (b_i, e_i)
ci=(bi,ei)是第i个clip proposal的开始和结束。作者设计了两种简单有效的生成建议的方法,如下:
Uniform sampling
假设一个行为实例的持续时间较短,则建议将视频分成N个等长的剪辑,则
b
i
=
i
−
1
N
T
+
1
b_i = \frac{i-1}{N}T + 1
bi=Ni−1T+1,
c
i
=
i
N
T
c_i = \frac{i}{N}T
ci=NiT。
缺点:容易产生不精确的建议。
Shot-based sampling:一种基于镜头变化检测的采样方法。
- 提取每帧图片的HOG特征,计算相邻帧之间的HOG特征差异。
- 用差值的绝对值来测量视觉内容的变化,如果大于阈值,将检测到一个镜头的变化。
- 对于每个镜头,连续采样K帧固定的镜头剪辑(在实践中,K设置为300)
设 s i = ( s i b , s i e ) s_i = (s^b_i, s^e_i) si=(sib,sie)是第i个镜头的开始和结束
则 C ( s i ) = ( s i b + ( i − 1 ) × K , s i b + i × K ) i : s i b + i × K < s i e C(s_i) = {(s^b_i+(i-1)×K, s^b_i+i×K)}_{i:s^b_i+i×K < s^e_i} C(si)=(sib+(i−1)×K,sib+i×K)i:sib+i×K<sie - 合并不同镜头的clip proposals。
UntrimmedNets
如下图所示,UntrimmedNet的体系结构由特征提取模块、分类模块和选择模块组成。这些不同的组件都被设计成可微的,并以端到端的方式呈现UntrimmedNet。
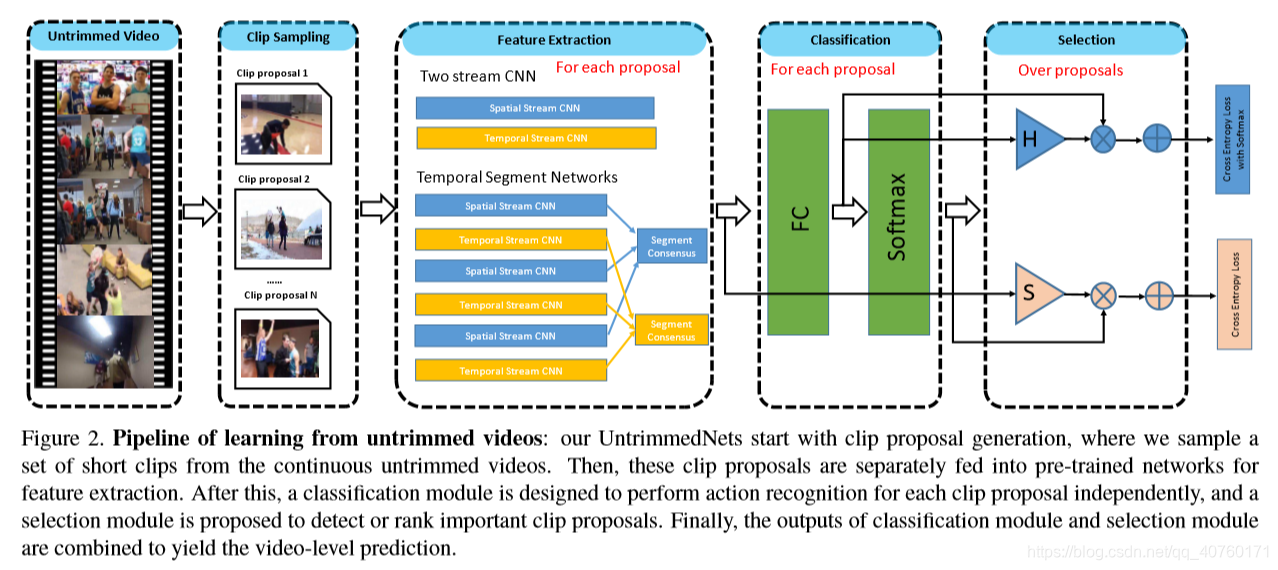
特征提取模块
对于给定的视频
C
=
{
c
i
}
i
=
1
N
C = {\{c_i\}}^N_{i=1}
C={ci}i=1N,提取特征表示为Φ(V, c)。
采用了两种架构,一是双流CNN,二是TSN。
分类模块
在分类模块中,根据提取的特征Φ(V, c) 将每个clip proposal c分类为预定义的动作类别.
- 假设有C个行为类别,学习一个线性映射 W c ∈ R C × D W^c ∈R^{C×D} Wc∈RC×D将Φ(V,c) 一个C维的分数向量 x c ( c ) x^c(c) xc(c),即 x c ( c ) = W c Φ ( V , c ) x^c(c) = W^c \mathit{Φ(V,c)} xc(c)=WcΦ(V,c)
- 分数向量通过SoftMax层,公式如下:
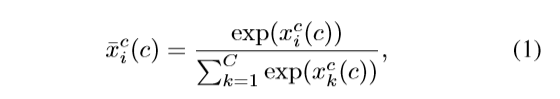
其中, x i c ( c ) x^c_i(c) xic(c) 是 x c ( c ) x^c(c) xc(c)的第i维。
x c ( c ) x^c(c) xc(c)表示clip proposal c的原始分类分数, x ‾ c ( c ) \overline{x}^c(c) xc(c)表示softMax层分类分数。
分析:两个分数之间略有不同。
1) x c ( c ) x^c(c) xc(c)对原始类的激活进行编码,它能够响应包含特定行为类的程度。在不包含行为实例的情况下,他的每个类的值会特别小。
2) x ‾ c ( c ) \overline{x}^c(c) xc(c)进行过归一化的操作,使其值和为1。如果有行为实例在这个剪辑中,softmax分数会编码行为类分布的信息。但对于背景剪辑,这种归一化操作可能会放大噪声激活,其响应可能无法正确编码视觉信息。
选择模块
选择模块旨在选择那些最有可能包含动作实例的clip proposals。为此,设计了两种选择机制:基于多实例学习(MIL)原则的hard selection和基于注意建模的soft selection。
hard selection
- 选择分类分数最高的k个实例,然后在这些实例中进行平均。这里使用原始的分类分数,因为它的值能够正确地反映包含某些动作实例的可能性。
- 这里用 x i s ( c j ) = δ ( j ∈ S i k ) x^s_i(c_j) = δ(j∈S^k_i) xis(cj)=δ(j∈Sik)来编码selection选择i类和实例 c j c_j cj,其中 S i k S^k_i Sik是第i类分类得分最高的k个clip proposals的索引集。(如果 c j c_j cj属于 S i k S^k_i Sik设置 x i s ( c j ) = δ x^s_i(c_j) = δ xis(cj)=δ)
soft selection :
1.直观上, 这些clip proposals并不都与行为类相关,可以学习一个attention weight来突出有区别的clip proposals,并抑制背景clip proposals。
2. 形式上,对于每个clip proposal,学习基于特征表示Φ(V, c) 的attention weight(带有线性转换),即
x
s
(
c
)
=
w
s
T
Φ
(
c
)
x^s(c) =w^{sT}\mathit{Φ(c)}
xs(c)=wsTΦ(c),
w
s
∈
R
D
w^s∈R^D
ws∈RD。然后,通过softmax层,公式如下:
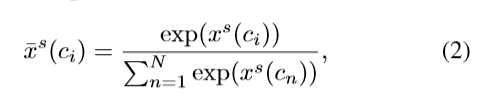
x
s
(
c
)
x^s(c)
xs(c)表示clip proposal c的原始选择分数,
x
‾
c
(
c
)
\overline{x}^c(c)
xc(c)表示softMax层选择分数。
注意:在分类模块中,针对每个clip proposal,分别对不同行动类的分类分数应用softmax操作,而在selection模块中,这个操作是针对不同的clip proposal执行的。
视频预测
通过结合分类分数和选择分数,对未修剪的视频产生预测分数
x
‾
p
(
V
)
\overline{x}^p(V)
xp(V)。
hard selection:对所选的top-k实例求平均值
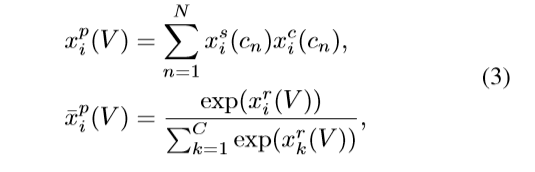
其中,其中
x
s
(
c
n
)
x^s(c_n)
xs(cn)和
x
c
(
c
n
)
x^c(c_n)
xc(cn)是clip proposal
c
n
c_n
cn的hard selection指标和分类分数。
soft selection
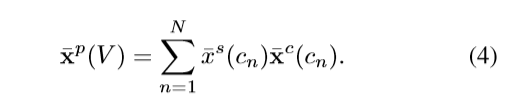
训练
损失函数如下:
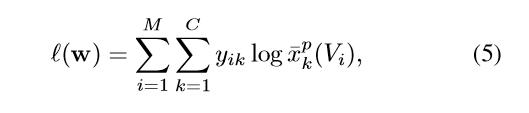
其中,M是训练视频数量,在训练中衰退权重设为0.0005。
对于包含多个类的行为实例,使用L1-norm归一化标签,然后使用其来计算损失函数,如下:
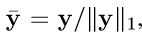
行为识别与检测
行为识别
由于UntrimmedNets是建立在两个流CNNs或时间段网络上的,所学习的模型可以被看作是snippet-level分类器。所以在未裁剪的视频中对动作识别进行了snippet-wise评估。在实际中,我们每30帧采样一帧(或5帧叠加光流)。将采样帧的识别分数通过top-k池(k设置为20)或加权和进行聚合,从而得到最终的视频级预测。
行为检测
带有soft selection module的UntrimmedNet不仅提供了一个识别评分,还输出了每个片段的attention weight。当然,这种attention weights可以用于未修剪视频的动作检测(时间定位)。为了获得更精确的定位,每15帧进行一次测试,并保留每一帧的预测分数和注意权重。在注意权值的基础上,通过阈值(设置为0.0001)去除背景。最后,在去除背景后,对分类分数进行阈值化(设置为0.5)得到最终的检测结果。
实验
数据集
数据集:THUMOS14和ActivityNet。这两个数据集适合评估方法,因为它们提供了原始的未修剪。ActivityNet数据集是最近引入的一个基准,用于未修剪视频中的动作识别和检测。使用ActivityNet 1.2版本进行实验。在这个版本中,ActivityNet包含了4819个培训视频、2383个验证视频和2480个测试视频,共100个活动类。
两种实验:
- 在训练数据上学习UntrimmedNets并在验证数据上测试它;
- 在训练和验证数据的结合上学习UntrimmedNets并将测试结果提交给评估服务器。
注:评估指标是基于平均精度均值(mAP)行动识别这两个数据集。对于动作检测,遵循标准的评估度量,报告THUMOS14数据集上不同的IoU值的交集的mAP值。
实现细节
- 使用Caffe toolbox的视频扩展版本来实现UntrimmedNet。
- 在UntrimmedNet中,选择了两个流CNNs[和时间分段网络以提取特征。两种网络都基于两种流输入(RGB和光流),时间分段网络采用分段建模(3段)来捕获长时间的时间信息。
时间分段网络的空间流的输入流是1帧RGB图像和空间流是5-帧TVL1光流。 - 选择Inception architecture with Batch Normalization来设计UntrimmedNet。
- 使用ImageNet预训练模型。
- UntrimmedNet参数的优化采用mini-batch随机梯度算法,批量大小设置为256,动量设置为0.9。空间流的初始学习率设置为0.001,每4000次迭代减少10倍,整个训练在10000次迭代时停止。对于时间流,将初始学习率设置为0.005,每6000次迭代减少10倍,在18000次迭代时停止训练。
- 由于THUMOS14和ActivityNet的训练集相对较小,因此使用了高的dropout比率(空间流为0.8,时间流为0.7)和常见的数据增强技术,包括裁剪增强和规模抖动。
探索研究
评估WSR
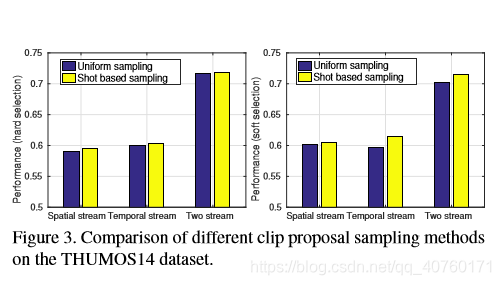
- 对比两个采样方式
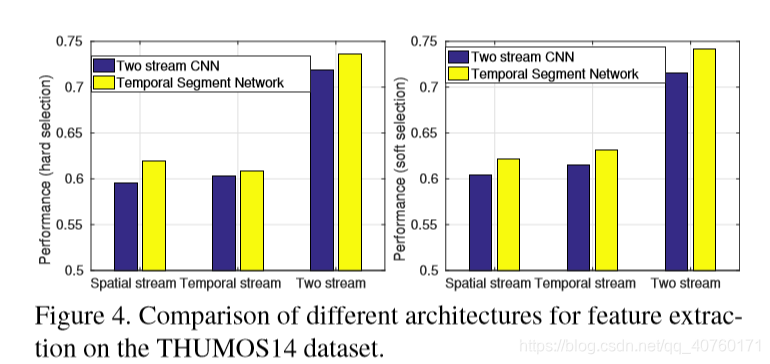
- 比较两种网络的特征提取
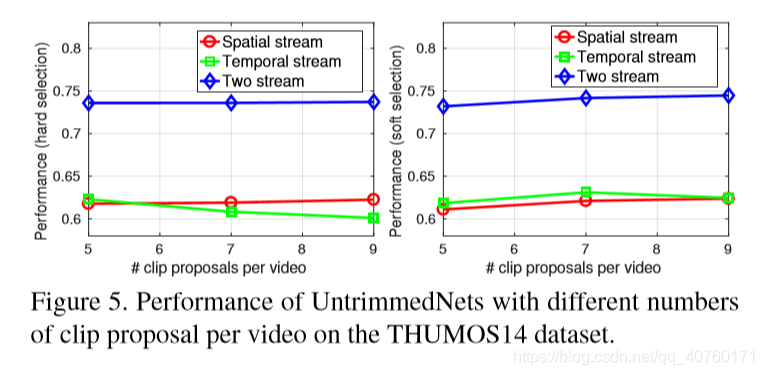
- 比较不同clip proporsal数量
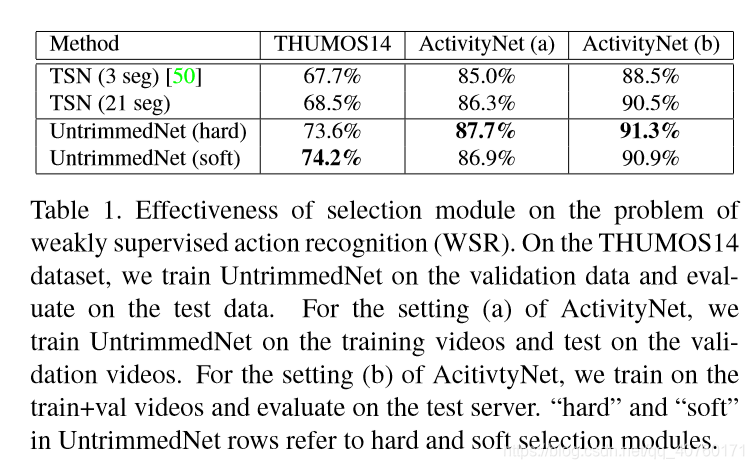
- 选择模块的有效性
- 与先进技术的比较
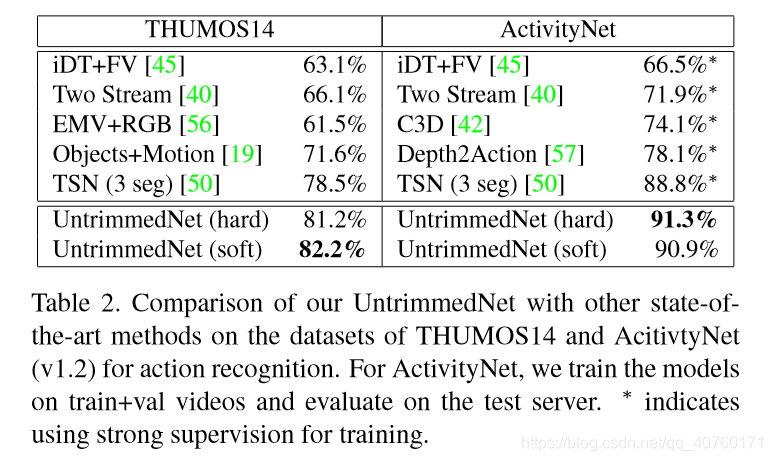
评估WSD
定性的结果
首先在THUMOS14和ActivityNet的测试数据上可视化一些学习attention weights的例子。这些示例如图所示。

在这个示例中,每一行描述一个视频,其中前4张图像显示的帧具有最高的attention weight,而最后4张图像显示的帧具有最低的权attention weight。选择模块能够自动突出重要的帧,并避免与静态背景或非动作姿势相对应的无关帧。
定量的结果
报告了行动检测的性能在THUMOS14数据集上,基于标准的交叉联合(IoU)标准。只是尝试了一个简单的检测策略,通过阈值的attention weights和检测分数,旨在说明,UntrimmedNets学习模型也可以应用于行动检测。在未来,可能会尝试更先进的检测方法和后处理技术。将检测结果与表中其他最先进的方法进行了比较。
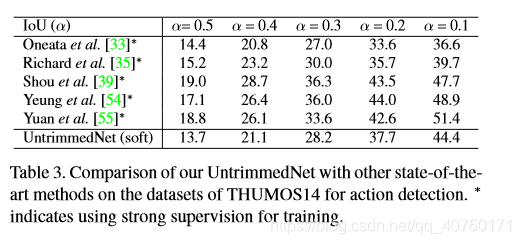
可以看出,仍然可以获得与强监督方法相当的性能,这证明了UntrimmedNets在学习未修剪视频方面的有效性。














 3458
3458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









